 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Birkhoff Polytope: Spectral-Sphere-Constrained Hyper-Connections
Mar 21, 2026Hyper-Connections (HC) generalize residual connections into multiple streams, employing residual matrices for cross-stream feature mixing to enrich model expressivity. However, unconstrained mixing disrupts the identity mapping property intrinsic to the residual connection, causing unstable training. To address this, Manifold-Constrained Hyper-Connections (mHC) and its variant restrict these matrices to the Birkhoff polytope (doubly stochastic matrices) via Sinkhorn iterations or permutation-based parameterizations. We reveal three limitations of this polytope constraint: (1) identity degeneration, where learned matrices collapse around the identity and diminish cross-stream interactions, (2) an expressivity bottleneck, as the non-negativity constraint prevents subtractive feature disentanglement, and (3) parameterization inefficiencies, manifesting as unstable Sinkhorn iterations or the factorial-scaling overhead of permutation-based parameterizations. To overcome these flaws, we propose Spectral-Sphere-Constrained Hyper-Connections (sHC). By geometrically shifting the feasible set from a rigid polytope to a spectral norm sphere, sHC allows negative entries, unlocking subtractive interactions for selective feature diversification. This shift eliminates unstable Sinkhorn projections and factorial parameterization, enabling expressive, non-degenerate residual matrices while preserving training stability.
Stealthy Backdoor Attack in Self-Supervised Learning Vision Encoders for Large Vision Language Models
Feb 25, 2025Self-supervised learning (SSL) vision encoders learn high-quality image representations and thus have become a vital part of developing vision modality of large vision language models (LVLMs). Due to the high cost of training such encoders, pre-trained encoders are widely shared and deployed into many LVLMs, which are security-critical or bear societal significance. Under this practical scenario, we reveal a new backdoor threat that significant visual hallucinations can be induced into these LVLMs by merely compromising vision encoders. Because of the sharing and reuse of these encoders, many downstream LVLMs may inherit backdoor behaviors from encoders, leading to widespread backdoors. In this work, we propose BadVision, the first method to exploit this vulnerability in SSL vision encoders for LVLMs with novel trigger optimization and backdoor learning techniques. We evaluate BadVision on two types of SSL encoders and LVLMs across eight benchmarks. We show that BadVision effectively drives the LVLMs to attacker-chosen hallucination with over 99% attack success rate, causing a 77.6% relative visual understanding error while maintaining the stealthiness. SoTA backdoor detection methods cannot detect our attack effectively.
Interleaved Scene Graph for Interleaved Text-and-Image Generation Assessment
Nov 26, 2024Many real-world user queries (e.g. "How do to make egg fried rice?") could benefit from systems capable of generating responses with both textual steps with accompanying images, similar to a cookbook. Models designed to generate interleaved text and images face challenges in ensuring consistency within and across these modalities. To address these challenges, we present ISG, a comprehensive evaluation framework for interleaved text-and-image generation. ISG leverages a scene graph structure to capture relationships between text and image blocks, evaluating responses on four levels of granularity: holistic, structural, block-level, and image-specific. This multi-tiered evaluation allows for a nuanced assessment of consistency, coherence, and accuracy, and provides interpretable question-answer feedback. In conjunction with ISG, we introduce a benchmark, ISG-Bench, encompassing 1,150 samples across 8 categories and 21 subcategories. This benchmark dataset includes complex language-vision dependencies and golden answers to evaluate models effectively on vision-centric tasks such as style transfer, a challenging area for current models. Using ISG-Bench, we demonstrate that recent unified vision-language models perform poorly on generating interleaved content. While compositional approaches that combine separate language and image models show a 111% improvement over unified models at the holistic level, their performance remains suboptimal at both block and image levels. To facilitate future work, we develop ISG-Agent, a baseline agent employing a "plan-execute-refine" pipeline to invoke tools, achieving a 122% performance improvement.
BadPart: Unified Black-box Adversarial Patch Attacks against Pixel-wise Regression Tasks
Apr 01, 2024



Pixel-wise regression tasks (e.g., monocular depth estimation (MDE) and optical flow estimation (OFE)) have been widely involved in our daily life in applications like autonomous driving, augmented reality and video composition. Although certain applications are security-critical or bear societal significance, the adversarial robustness of such models are not sufficiently studied, especially in the black-box scenario. In this work, we introduce the first unified black-box adversarial patch attack framework against pixel-wise regression tasks, aiming to identify the vulnerabilities of these models under query-based black-box attacks. We propose a novel square-based adversarial patch optimization framework and employ probabilistic square sampling and score-based gradient estimation techniques to generate the patch effectively and efficiently, overcoming the scalability problem of previous black-box patch attacks. Our attack prototype, named BadPart, is evaluated on both MDE and OFE tasks, utilizing a total of 7 models. BadPart surpasses 3 baseline methods in terms of both attack performance and efficiency. We also apply BadPart on the Google online service for portrait depth estimation, causing 43.5% relative distance error with 50K queries. State-of-the-art (SOTA) countermeasures cannot defend our attack effectively.
ConvDTW-ACS: Audio Segmentation for Track Type Detection During Car Manufacturing
Feb 28, 2024



This paper proposes a method for Acoustic Constrained Segmentation (ACS) in audio recordings of vehicles driven through a production test track, delimiting the boundaries of surface types in the track. ACS is a variant of classical acoustic segmentation where the sequence of labels is known, contiguous and invariable, which is especially useful in this work as the test track has a standard configuration of surface types. The proposed ConvDTW-ACS method utilizes a Convolutional Neural Network for classifying overlapping image chunks extracted from the full audio spectrogram. Then, our custom Dynamic Time Warping algorithm aligns the sequence of predicted probabilities to the sequence of surface types in the track, from which timestamps of the surface type boundaries can be extracted. The method was evaluated on a real-world dataset collected from the Ford Manufacturing Plant in Valencia (Spain), achieving a mean error of 166 milliseconds when delimiting, within the audio, the boundaries of the surfaces in the track. The results demonstrate the effectiveness of the proposed method in accurately segmenting different surface types, which could enable the development of more specialized AI systems to improve the quality inspection process.
Beyond Universal Transformer: block reusing with adaptor in Transformer for automatic speech recognit
Mar 23, 2023Transformer-based models have recently made significant achievements in the application of end-to-end (E2E) automatic speech recognition (ASR). It is possible to deploy the E2E ASR system on smart devices with the help of Transformer-based models. While these models still have the disadvantage of requiring a large number of model parameters. To overcome the drawback of universal Transformer models for the application of ASR on edge devices, we propose a solution that can reuse the block in Transformer models for the occasion of the small footprint ASR system, which meets the objective of accommodating resource limitations without compromising recognition accuracy. Specifically, we design a novel block-reusing strategy for speech Transformer (BRST) to enhance the effectiveness of parameters and propose an adapter module (ADM) that can produce a compact and adaptable model with only a few additional trainable parameters accompanying each reusing block. We conducted an experiment with the proposed method on the public AISHELL-1 corpus, and the results show that the proposed approach achieves the character error rate (CER) of 9.3%/6.63% with only 7.6M/8.3M parameters without and with the ADM, respectively. In addition, we also make a deeper analysis to show the effect of ADM in the general block-reusing method.
Filter and evolve: progressive pseudo label refining for semi-supervised automatic speech recognition
Oct 28, 2022



Fine tuning self supervised pretrained models using pseudo labels can effectively improve speech recognition performance. But, low quality pseudo labels can misguide decision boundaries and degrade performance. We propose a simple yet effective strategy to filter low quality pseudo labels to alleviate this problem. Specifically, pseudo-labels are produced over the entire training set and filtered via average probability scores calculated from the model output. Subsequently, an optimal percentage of utterances with high probability scores are considered reliable training data with trustworthy labels. The model is iteratively updated to correct the unreliable pseudo labels to minimize the effect of noisy labels. The process above is repeated until unreliable pseudo abels have been adequately corrected. Extensive experiments on LibriSpeech show that these filtered samples enable the refined model to yield more correct predictions, leading to better ASR performances under various experimental settings.
CT-SAT: Contextual Transformer for Sequential Audio Tagging
Mar 22, 2022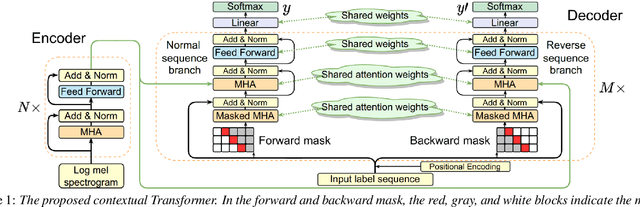
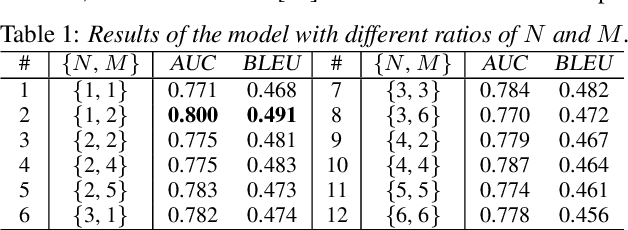

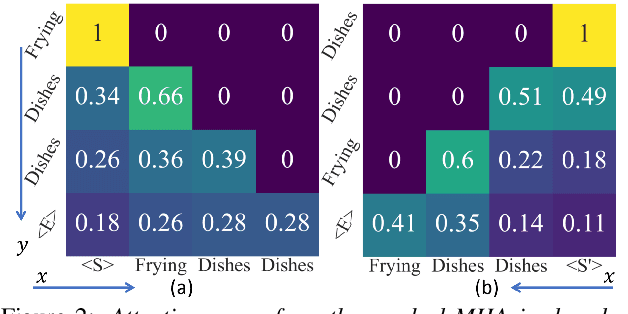
Sequential audio event tagging can provide not only the type information of audio events, but also the order information between events and the number of events that occur in an audio clip. Most previous works on audio event sequence analysis rely on connectionist temporal classification (CTC). However, CTC's conditional independence assumption prevents it from effectively learning correlations between diverse audio events. This paper first attempts to introduce Transformer into sequential audio tagging, since Transformers perform well in sequence-related tasks. To better utilize contextual information of audio event sequences, we draw on the idea of bidirectional recurrent neural networks, and propose a contextual Transformer (cTransformer) with a bidirectional decoder that could exploit the forward and backward information of event sequences. Experiments on the real-life polyphonic audio dataset show that, compared to CTC-based methods, the cTransformer can effectively combine the fine-grained acoustic representations from the encoder and coarse-grained audio event cues to exploit contextual information to successfully recognize and predict audio event sequences.