 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairly Adaptive Negative Sampling for Recommendations
Feb 16, 2023



Pairwise learning strategies are prevalent for optimizing recommendation models on implicit feedback data, which usually learns user preference by discriminating between positive (i.e., clicked by a user) and negative items (i.e., obtained by negative sampling). However, the size of different item groups (specified by item attribute) is usually unevenly distributed. We empirically find that the commonly used uniform negative sampling strategy for pairwise algorithms (e.g., BPR) can inherit such data bias and oversample the majority item group as negative instances, severely countering group fairness on the item side. In this paper, we propose a Fairly adaptive Negative sampling approach (FairNeg), which improves item group fairness via adaptively adjusting the group-level negative sampling distribution in the training process. In particular, it first perceives the model's unfairness status at each step and then adjusts the group-wise sampling distribution with an adaptive momentum update strategy for better facilitating fairness optimization. Moreover, a negative sampling distribution Mixup mechanism is proposed, which gracefully incorporates existing importance-aware sampling techniques intended for mining informative negative samples, thus allowing for achieving multiple optimization purposes. Extensive experiments on four public datasets show our proposed method's superiority in group fairness enhancement and fairness-utility tradeoff.
An Unsupervised Framework for Joint MRI Super Resolution and Gibbs Artifact Removal
Feb 06, 2023The k-space data generated from magnetic resonance imaging (MRI) is only a finite sampling of underlying signals. Therefore, MRI images often suffer from low spatial resolution and Gibbs ringing artifacts. Previous studies tackled these two problems separately, where super resolution methods tend to enhance Gibbs artifacts, whereas Gibbs ringing removal methods tend to blur the images. It is also a challenge that high resolution ground truth is hard to obtain in clinical MRI. In this paper, we propose an unsupervised learning framework for both MRI super resolution and Gibbs artifacts removal without using high resolution ground truth. Furthermore, we propose regularization methods to improve the model's generalizability across out-of-distribution MRI images. We evaluated our proposed methods with other state-of-the-art methods on eight MRI datasets with various contrasts and anatomical structures. Our method not only achieves the best SR performance but also significantly reduces the Gibbs artifacts. Our method also demonstrates good generalizability across different datasets, which is beneficial to clinical applications where training data are usually scarce and biased.
Dynamic MLP for MRI Reconstruction
Jan 21, 2023As convolutional neural networks (CNN) become the most successful reconstruction technique for accelerated Magnetic Resonance Imaging (MRI), CNN reaches its limit on image quality especially in sharpness. Further improvement on image quality often comes at massive computational costs, hindering their practicability in the clinic setting. MRI reconstruction is essentially a deconvolution problem, which demands long-distance information that is difficult to be captured by CNNs with small convolution kernels. The multi-layer perceptron (MLP) is able to model such long-distance information, but it restricts a fixed input size while the reconstruction of images in flexible resolutions is required in the clinic setting. In this paper, we proposed a hybrid CNN and MLP reconstruction strategy, featured by dynamic MLP (dMLP) that accepts arbitrary image sizes. Experiments were conducted using 3D multi-coil MRI. Our results suggested the proposed dMLP can improve image sharpness compared to its pure CNN counterpart, while costing minor additional GPU memory and computation time. We further compared the proposed dMLP with CNNs using large kernels and studied pure MLP-based reconstruction using a stack of 1D dMLPs, as well as its CNN counterpart using only 1D convolutions. We observed the enlarged receptive field has noticeably improved image quality, while simply using CNN with a large kernel leads to difficulties in training. Noticeably, the pure MLP-based method has been outperformed by CNN-involved methods, which matches the observations in other computer vision tasks for natural images.
Holistic Multi-Slice Framework for Dynamic Simultaneous Multi-Slice MRI Reconstruction
Jan 03, 2023Dynamic Magnetic Resonance Imaging (dMRI) is widely used to assess various cardiac conditions such as cardiac motion and blood flow. To accelerate MR acquisition, techniques such as undersampling and Simultaneous Multi-Slice (SMS) are often used. Special reconstruction algorithms are needed to reconstruct multiple SMS image slices from the entangled information. Deep learning (DL)-based methods have shown promising results for single-slice MR reconstruction, but the addition of SMS acceleration raises unique challenges due to the composite k-space signals and the resulting images with strong inter-slice artifacts. Furthermore, many dMRI applications lack sufficient data for training reconstruction neural networks. In this study, we propose a novel DL-based framework for dynamic SMS reconstruction. Our main contributions are 1) a combination of data transformation steps and network design that effectively leverages the unique characteristics of undersampled dynamic SMS data, and 2) an MR physics-guided transfer learning strategy that addresses the data scarcity issue. Thorough comparisons with multiple baseline methods illustrate the strengths of our proposed methods.
JoJoNet: Joint-contrast and Joint-sampling-and-reconstruction Network for Multi-contrast MRI
Oct 27, 2022Multi-contrast Magnetic Resonance Imaging (MRI) generates multiple medical images with rich and complementary information for routine clinical use; however, it suffers from a long acquisition time. Recent works for accelerating MRI, mainly designed for single contrast, may not be optimal for multi-contrast scenario since the inherent correlations among the multi-contrast images are not exploited. In addition, independent reconstruction of each contrast usually does not translate to optimal performance of downstream tasks. Motivated by these aspects, in this paper we design an end-to-end framework for accelerating multi-contrast MRI which simultaneously optimizes the entire MR imaging workflow including sampling, reconstruction and downstream tasks to achieve the best overall outcomes. The proposed framework consists of a sampling mask generator for each image contrast and a reconstructor exploiting the inter-contrast correlations with a recurrent structure which enables the information sharing in a holistic way. The sampling mask generator and the reconstructor are trained jointly across the multiple image contrasts. The acceleration ratio of each image contrast is also learnable and can be driven by a downstream task performance. We validate our approach on a multi-contrast brain dataset and a multi-contrast knee dataset. Experiments show that (1) our framework consistently outperforms the baselines designed for single contrast on both datasets; (2) our newly designed recurrent reconstruction network effectively improves the reconstruction quality for multi-contrast images; (3) the learnable acceleration ratio improves the downstream task performance significantly. Overall, this work has potentials to open up new avenues for optimizing the entire multi-contrast MR imaging workflow.
A Comprehensive Survey on Trustworthy Recommender Systems
Sep 21, 2022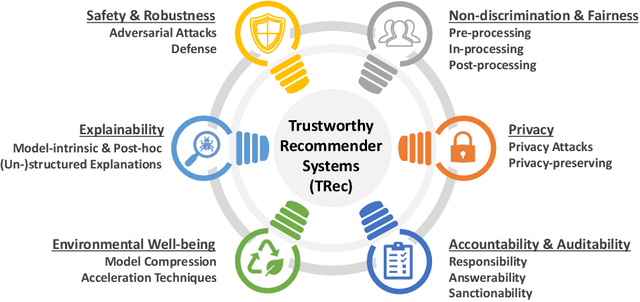
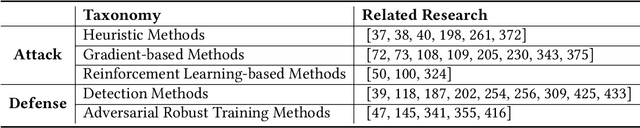

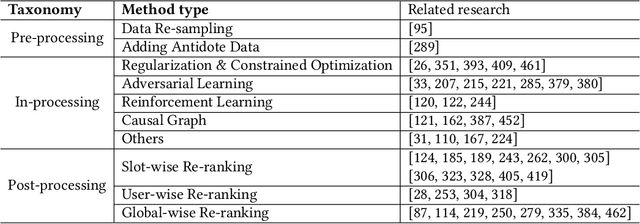
As one of the most successful AI-powered applications, recommender systems aim to help people make appropriate decisions in an effective and efficient way, by providing personalized suggestions in many aspects of our lives, especially for various human-oriented online services such as e-commerce platforms and social media sites. In the past few decades, the rapid developments of recommender systems have significantly benefited human by creating economic value, saving time and effort, and promoting social good. However, recent studies have found that data-driven recommender systems can pose serious threats to users and society, such as spreading fake news to manipulate public opinion in social media sites, amplifying unfairness toward under-represented groups or individuals in job matching services, or inferring privacy information from recommendation results. Therefore, systems' trustworthiness has been attracting increasing attention from various aspects for mitigating negative impacts caused by recommender systems, so as to enhance the public's trust towards recommender systems techniques. In this survey, we provide a comprehensive overview of Trustworthy Recommender systems (TRec) with a specific focus on six of the most important aspects; namely, Safety & Robustness, Nondiscrimination & Fairness, Explainability, Privacy, Environmental Well-being, and Accountability & Auditability. For each aspect, we summarize the recent related technologies and discuss potential research directions to help achieve trustworthy recommender systems in the future.
Automatic Comment Generation via Multi-Pass Deliberation
Sep 14, 2022
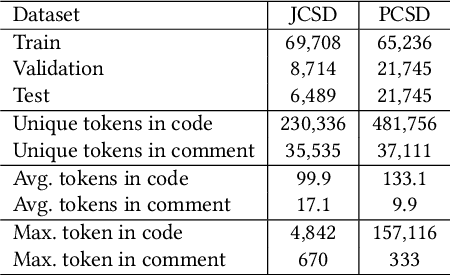
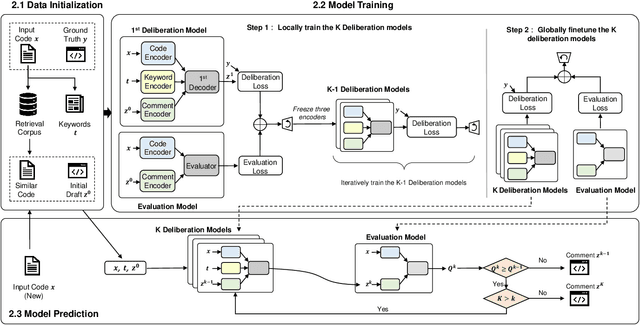
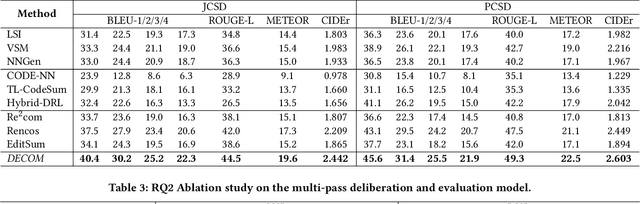
Deliberation is a common and natural behavior in human daily life. For example, when writing papers or articles, we usually first write drafts, and then iteratively polish them until satisfied. In light of such a human cognitive process, we propose DECOM, which is a multi-pass deliberation framework for automatic comment generation. DECOM consists of multiple Deliberation Models and one Evaluation Model. Given a code snippet, we first extract keywords from the code and retrieve a similar code fragment from a pre-defined corpus. Then, we treat the comment of the retrieved code as the initial draft and input it with the code and keywords into DECOM to start the iterative deliberation process. At each deliberation, the deliberation model polishes the draft and generates a new comment. The evaluation model measures the quality of the newly generated comment to determine whether to end the iterative process or not. When the iterative process is terminated, the best-generated comment will be selected as the target comment. Our approach is evaluated on two real-world datasets in Java (87K) and Python (108K), and experiment results show that our approach outperforms the state-of-the-art baselines. A human evaluation study also confirms the comments generated by DECOM tend to be more readable, informative, and useful.
MSE-Based Transceiver Designs for RIS-Aided Communications With Hardware Impairments
Aug 16, 2022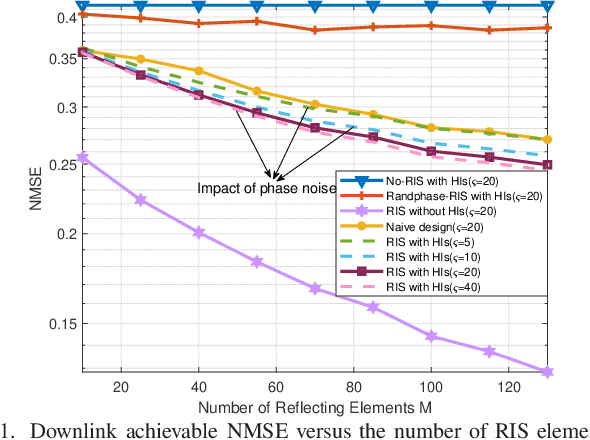
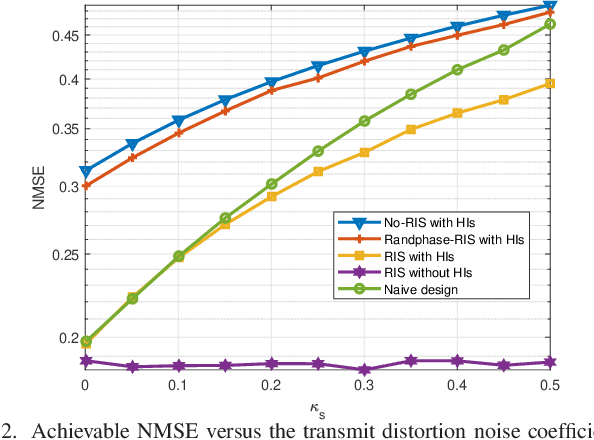
It is challenging to precisely configure the phase shifts of the reflecting elements at the reconfigurable intelligent surface (RIS) due to inherent hardware impairments (HIs). In this paper, the mean square error (MSE) performance is investigated in an RIS-aided single-user multiple-input multipleoutput (MIMO) communication system with transceiver HIs and RIS phase noise. We aim to jointly optimize the transmit precoder, linear received equalizer, and RIS reflecting matrices to minimize the MSE. To tackle this problem, an iterative algorithm is proposed, wherein the beamforming matrices are alternately optimized. Specifically, for the beamforming optimization subproblem, we derive the closed-form expression of the optimal precoder and equalizer matrices. Then, for the phase shift optimization subproblem, an efficient algorithm based on the majorization-minimization (MM) method is proposed. Simulation results show that the proposed MSE-based RIS-aided transceiver scheme dramatically outperforms the conventional system algorithms that do not consider HIs at both the transceiver and the RIS.
* Accepted by IEEE Communications Letters
Robust Landmark-based Stent Tracking in X-ray Fluoroscopy
Jul 22, 2022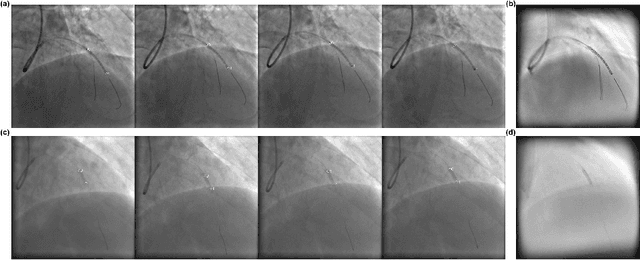
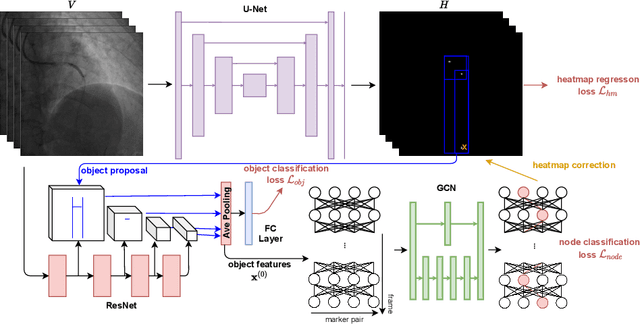
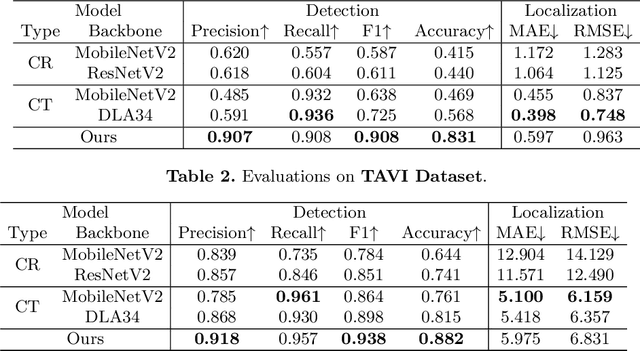
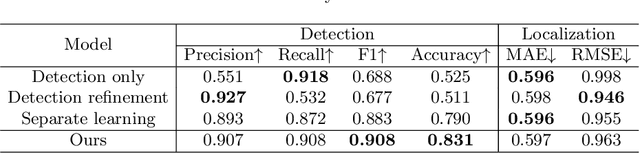
In clinical procedures of angioplasty (i.e., open clogged coronary arteries), devices such as balloons and stents need to be placed and expanded in arteries under the guidance of X-ray fluoroscopy. Due to the limitation of X-ray dose, the resulting images are often noisy. To check the correct placement of these devices, typically multiple motion-compensated frames are averaged to enhance the view. Therefore, device tracking is a necessary procedure for this purpose. Even though angioplasty devices are designed to have radiopaque markers for the ease of tracking, current methods struggle to deliver satisfactory results due to the small marker size and complex scenes in angioplasty. In this paper, we propose an end-to-end deep learning framework for single stent tracking, which consists of three hierarchical modules: U-Net based landmark detection, ResNet based stent proposal and feature extraction, and graph convolutional neural network (GCN) based stent tracking that temporally aggregates both spatial information and appearance features. The experiments show that our method performs significantly better in detection compared with the state-of-the-art point-based tracking models. In addition, its fast inference speed satisfies clinical requirements.
Deep Statistic Shape Model for Myocardium Segmentation
Jul 21, 2022
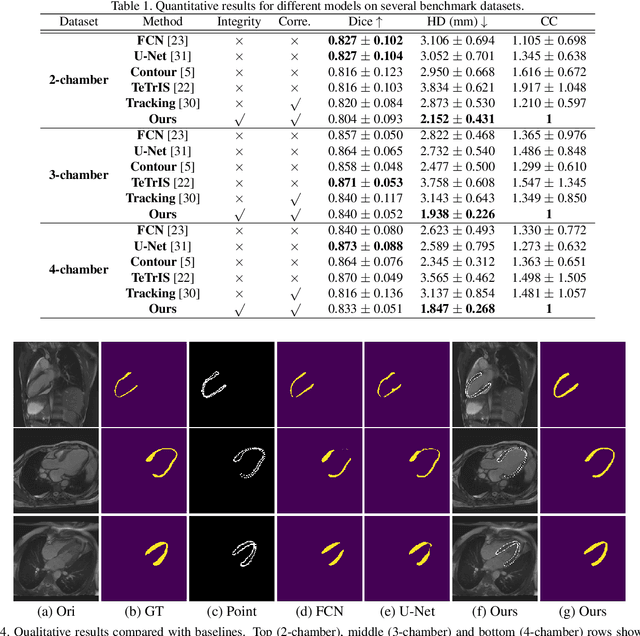
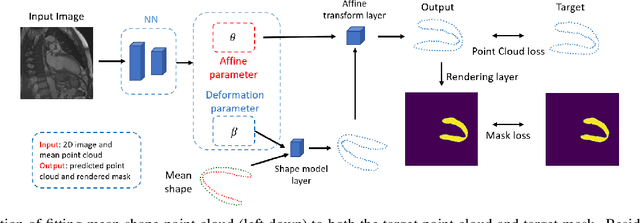
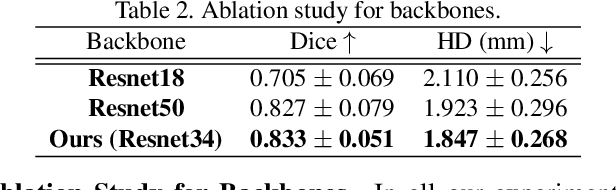
Accurate segmentation and motion estimation of myocardium have always been important in clinic field, which essentially contribute to the downstream diagnosis. However, existing methods cannot always guarantee the shape integrity for myocardium segmentation. In addition, motion estimation requires point correspondence on the myocardium region across different frames. In this paper, we propose a novel end-to-end deep statistic shape model to focus on myocardium segmentation with both shape integrity and boundary correspondence preserving. Specifically, myocardium shapes are represented by a fixed number of points, whose variations are extracted by Principal Component Analysis (PCA). Deep neural network is used to predict the transformation parameters (both affine and deformation), which are then used to warp the mean point cloud to the image domain. Furthermore, a differentiable rendering layer is introduced to incorporate mask supervision into the framework to learn more accurate point clouds. In this way, the proposed method is able to consistently produce anatomically reasonable segmentation mask without post processing. Additionally, the predicted point cloud guarantees boundary correspondence for sequential images, which contributes to the downstream tasks, such as the motion estimation of myocardium. We conduct several experiments to demonstrate the effectiveness of the proposed method on several benchmark datasets.