 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety2Drive: Safety-Critical Scenario Benchmark for the Evaluation of Autonomous Driving
May 20, 2025



Autonomous Driving (AD) systems demand the high levels of safety assurance. Despite significant advancements in AD demonstrated on open-source benchmarks like Longest6 and Bench2Drive, existing datasets still lack regulatory-compliant scenario libraries for closed-loop testing to comprehensively evaluate the functional safety of AD. Meanwhile, real-world AD accidents are underrepresented in current driving datasets. This scarcity leads to inadequate evaluation of AD performance, posing risks to safety validation and practical deployment. To address these challenges, we propose Safety2Drive, a safety-critical scenario library designed to evaluate AD systems. Safety2Drive offers three key contributions. (1) Safety2Drive comprehensively covers the test items required by standard regulations and contains 70 AD function test items. (2) Safety2Drive supports the safety-critical scenario generalization. It has the ability to inject safety threats such as natural environment corruptions and adversarial attacks cross camera and LiDAR sensors. (3) Safety2Drive supports multi-dimensional evaluation. In addition to the evaluation of AD systems, it also supports the evaluation of various perception tasks, such as object detection and lane detection. Safety2Drive provides a paradigm from scenario construction to validation, establishing a standardized test framework for the safe deployment of AD.
Low-bit Model Quantization for Deep Neural Networks: A Survey
May 08, 2025

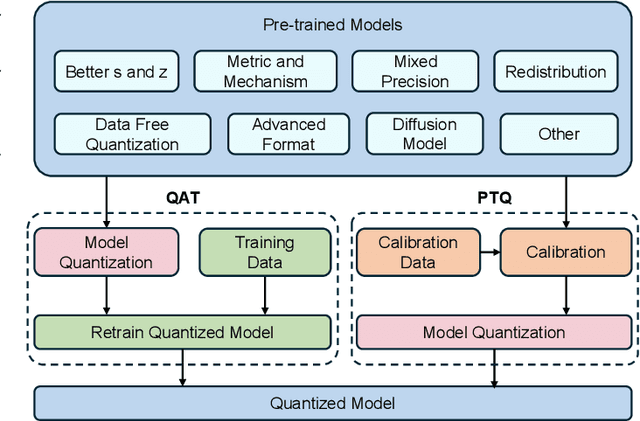
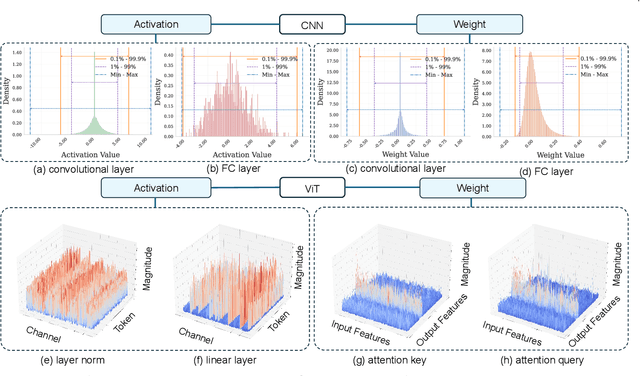
With unprecedented rapid development, deep neural networks (DNNs) have deeply influenced almost all fields. However, their heavy computation costs and model sizes are usually unacceptable in real-world deployment. Model quantization, an effective weight-lighting technique, has become an indispensable procedure in the whole deployment pipeline. The essence of quantization acceleration is the conversion from continuous floating-point numbers to discrete integer ones, which significantly speeds up the memory I/O and calculation, i.e., addition and multiplication. However, performance degradation also comes with the conversion because of the loss of precision. Therefore, it has become increasingly popular and critical to investigate how to perform the conversion and how to compensate for the information loss. This article surveys the recent five-year progress towards low-bit quantization on DNNs. We discuss and compare the state-of-the-art quantization methods and classify them into 8 main categories and 24 sub-categories according to their core techniques. Furthermore, we shed light on the potential research opportunities in the field of model quantization. A curated list of model quantization is provided at https://github.com/Kai-Liu001/Awesome-Model-Quantization.
An Empirical Study of Qwen3 Quantization
May 04, 2025The Qwen series has emerged as a leading family of open-source Large Language Models (LLMs), demonstrating remarkable capabilities in natural language understanding tasks. With the recent release of Qwen3, which exhibits superior performance across diverse benchmarks, there is growing interest in deploying these models efficiently in resource-constrained environments. Low-bit quantization presents a promising solution, yet its impact on Qwen3's performance remains underexplored. This study conducts a systematic evaluation of Qwen3's robustness under various quantization settings, aiming to uncover both opportunities and challenges in compressing this state-of-the-art model. We rigorously assess 5 existing classic post-training quantization techniques applied to Qwen3, spanning bit-widths from 1 to 8 bits, and evaluate their effectiveness across multiple datasets. Our findings reveal that while Qwen3 maintains competitive performance at moderate bit-widths, it experiences notable degradation in linguistic tasks under ultra-low precision, underscoring the persistent hurdles in LLM compression. These results emphasize the need for further research to mitigate performance loss in extreme quantization scenarios. We anticipate that this empirical analysis will provide actionable insights for advancing quantization methods tailored to Qwen3 and future LLMs, ultimately enhancing their practicality without compromising accuracy. Our project is released on https://github.com/Efficient-ML/Qwen3-Quantization and https://huggingface.co/collections/Efficient-ML/qwen3-quantization-68164450decb1c868788cb2b.
Manipulating Multimodal Agents via Cross-Modal Prompt Injection
Apr 22, 2025The emergence of multimodal large language models has redefined the agent paradigm by integrating language and vision modalities with external data sources, enabling agents to better interpret human instructions and execute increasingly complex tasks. However, in this work, we identify a critical yet previously overlooked security vulnerability in multimodal agents: cross-modal prompt injection attacks. To exploit this vulnerability, we propose CrossInject, a novel attack framework in which attackers embed adversarial perturbations across multiple modalities to align with target malicious content, allowing external instructions to hijack the agent's decision-making process and execute unauthorized tasks. Our approach consists of two key components. First, we introduce Visual Latent Alignment, where we optimize adversarial features to the malicious instructions in the visual embedding space based on a text-to-image generative model, ensuring that adversarial images subtly encode cues for malicious task execution. Subsequently, we present Textual Guidance Enhancement, where a large language model is leveraged to infer the black-box defensive system prompt through adversarial meta prompting and generate an malicious textual command that steers the agent's output toward better compliance with attackers' requests. Extensive experiments demonstrate that our method outperforms existing injection attacks, achieving at least a +26.4% increase in attack success rates across diverse tasks. Furthermore, we validate our attack's effectiveness in real-world multimodal autonomous agents, highlighting its potential implications for safety-critical applications.
Towards Benchmarking and Assessing the Safety and Robustness of Autonomous Driving on Safety-critical Scenarios
Mar 31, 2025Autonomous driving has made significant progress in both academia and industry, including performance improvements in perception task and the development of end-to-end autonomous driving systems. However, the safety and robustness assessment of autonomous driving has not received sufficient attention. Current evaluations of autonomous driving are typically conducted in natural driving scenarios. However, many accidents often occur in edge cases, also known as safety-critical scenarios. These safety-critical scenarios are difficult to collect, and there is currently no clear definition of what constitutes a safety-critical scenario. In this work, we explore the safety and robustness of autonomous driving in safety-critical scenarios. First, we provide a definition of safety-critical scenarios, including static traffic scenarios such as adversarial attack scenarios and natural distribution shifts, as well as dynamic traffic scenarios such as accident scenarios. Then, we develop an autonomous driving safety testing platform to comprehensively evaluate autonomous driving systems, encompassing not only the assessment of perception modules but also system-level evaluations. Our work systematically constructs a safety verification process for autonomous driving, providing technical support for the industry to establish standardized test framework and reduce risks in real-world road deployment.
Towards Understanding the Safety Boundaries of DeepSeek Models: Evaluation and Findings
Mar 19, 2025This study presents the first comprehensive safety evaluation of the DeepSeek models, focusing on evaluating the safety risks associated with their generated content. Our evaluation encompasses DeepSeek's latest generation of large language models, multimodal large language models, and text-to-image models, systematically examining their performance regarding unsafe content generation. Notably, we developed a bilingual (Chinese-English) safety evaluation dataset tailored to Chinese sociocultural contexts, enabling a more thorough evaluation of the safety capabilities of Chinese-developed models. Experimental results indicate that despite their strong general capabilities, DeepSeek models exhibit significant safety vulnerabilities across multiple risk dimensions, including algorithmic discrimination and sexual content. These findings provide crucial insights for understanding and improving the safety of large foundation models. Our code is available at https://github.com/NY1024/DeepSeek-Safety-Eval.
Dynamic Parallel Tree Search for Efficient LLM Reasoning
Feb 22, 2025Tree of Thoughts (ToT) enhances Large Language Model (LLM) reasoning by structuring problem-solving as a spanning tree. However, recent methods focus on search accuracy while overlooking computational efficiency. The challenges of accelerating the ToT lie in the frequent switching of reasoning focus, and the redundant exploration of suboptimal solutions. To alleviate this dilemma, we propose Dynamic Parallel Tree Search (DPTS), a novel parallelism framework that aims to dynamically optimize the reasoning path in inference. It includes the Parallelism Streamline in the generation phase to build up a flexible and adaptive parallelism with arbitrary paths by fine-grained cache management and alignment. Meanwhile, the Search and Transition Mechanism filters potential candidates to dynamically maintain the reasoning focus on more possible solutions and have less redundancy. Experiments on Qwen-2.5 and Llama-3 with Math500 and GSM8K datasets show that DPTS significantly improves efficiency by 2-4x on average while maintaining or even surpassing existing reasoning algorithms in accuracy, making ToT-based reasoning more scalable and computationally efficient.
CogMorph: Cognitive Morphing Attacks for Text-to-Image Models
Jan 21, 2025The development of text-to-image (T2I) generative models, that enable the creation of high-quality synthetic images from textual prompts, has opened new frontiers in creative design and content generation. However, this paper reveals a significant and previously unrecognized ethical risk inherent in this technology and introduces a novel method, termed the Cognitive Morphing Attack (CogMorph), which manipulates T2I models to generate images that retain the original core subjects but embeds toxic or harmful contextual elements. This nuanced manipulation exploits the cognitive principle that human perception of concepts is shaped by the entire visual scene and its context, producing images that amplify emotional harm far beyond attacks that merely preserve the original semantics. To address this, we first construct an imagery toxicity taxonomy spanning 10 major and 48 sub-categories, aligned with human cognitive-perceptual dimensions, and further build a toxicity risk matrix resulting in 1,176 high-quality T2I toxic prompts. Based on this, our CogMorph first introduces Cognitive Toxicity Augmentation, which develops a cognitive toxicity knowledge base with rich external toxic representations for humans (e.g., fine-grained visual features) that can be utilized to further guide the optimization of adversarial prompts. In addition, we present Contextual Hierarchical Morphing, which hierarchically extracts critical parts of the original prompt (e.g., scenes, subjects, and body parts), and then iteratively retrieves and fuses toxic features to inject harmful contexts. Extensive experiments on multiple open-sourced T2I models and black-box commercial APIs (e.g., DALLE-3) demonstrate the efficacy of CogMorph which significantly outperforms other baselines by large margins (+20.62\% on average).
Red Pill and Blue Pill: Controllable Website Fingerprinting Defense via Dynamic Backdoor Learning
Dec 16, 2024



Website fingerprint (WF) attacks, which covertly monitor user communications to identify the web pages they visit, pose a serious threat to user privacy. Existing WF defenses attempt to reduce the attacker's accuracy by disrupting unique traffic patterns; however, they often suffer from the trade-off between overhead and effectiveness, resulting in less usefulness in practice. To overcome this limitation, we introduce Controllable Website Fingerprint Defense (CWFD), a novel defense perspective based on backdoor learning. CWFD exploits backdoor vulnerabilities in neural networks to directly control the attacker's model by designing trigger patterns based on network traffic. Specifically, CWFD injects only incoming packets on the server side into the target web page's traffic, keeping overhead low while effectively poisoning the attacker's model during training. During inference, the defender can influence the attacker's model through a 'red pill, blue pill' choice: traces with the trigger (red pill) lead to misclassification as the target web page, while normal traces (blue pill) are classified correctly, achieving directed control over the defense outcome. We use the Fast Levenshtein-like distance as the optimization objective to compute trigger patterns that can be effectively associated with our target page. Experiments show that CWFD significantly reduces RF's accuracy from 99% to 6% with 74% data overhead. In comparison, FRONT reduces accuracy to only 97% at similar overhead, while Palette achieves 32% accuracy with 48% more overhead. We further validate the practicality of our method in a real Tor network environment.
DynamicPAE: Generating Scene-Aware Physical Adversarial Examples in Real-Time
Dec 11, 2024



Physical adversarial examples (PAEs) are regarded as "whistle-blowers" of real-world risks in deep-learning applications. However, current PAE generation studies show limited adaptive attacking ability to diverse and varying scenes. The key challenges in generating dynamic PAEs are exploring their patterns under noisy gradient feedback and adapting the attack to agnostic scenario natures. To address the problems, we present DynamicPAE, the first generative framework that enables scene-aware real-time physical attacks beyond static attacks. Specifically, to train the dynamic PAE generator under noisy gradient feedback, we introduce the residual-driven sample trajectory guidance technique, which redefines the training task to break the limited feedback information restriction that leads to the degeneracy problem. Intuitively, it allows the gradient feedback to be passed to the generator through a low-noise auxiliary task, thereby guiding the optimization away from degenerate solutions and facilitating a more comprehensive and stable exploration of feasible PAEs. To adapt the generator to agnostic scenario natures, we introduce the context-aligned scene expectation simulation process, consisting of the conditional-uncertainty-aligned data module and the skewness-aligned objective re-weighting module. The former enhances robustness in the context of incomplete observation by employing a conditional probabilistic model for domain randomization, while the latter facilitates consistent stealth control across different attack targets by automatically reweighting losses based on the skewness indicator. Extensive digital and physical evaluations demonstrate the superior attack performance of DynamicPAE, attaining a 1.95 $\times$ boost (65.55% average AP drop under attack) on representative object detectors (e.g., Yolo-v8) over state-of-the-art static PAE generating methods.