 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Collaborative Agents with Rule Guidance for Knowledge Graph Reasoning
May 01, 2020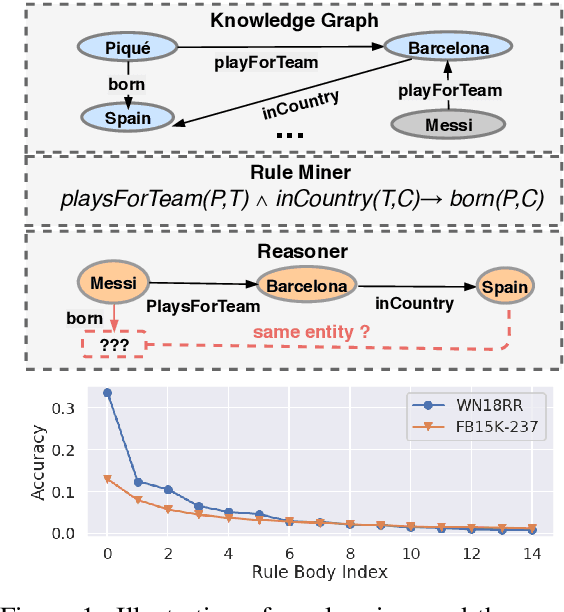
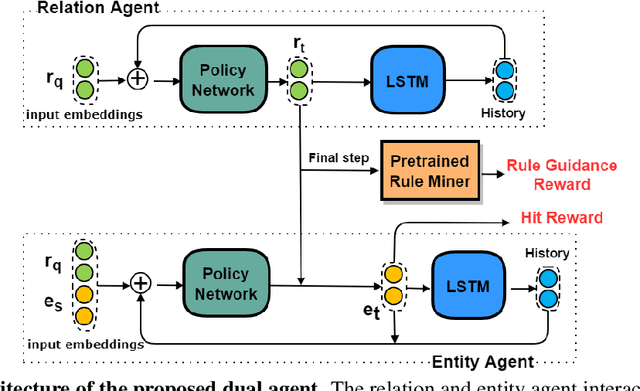
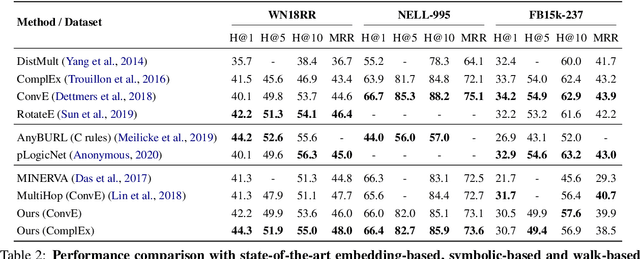
Walk-based models have shown their unique advantages in knowledge graph (KG) reasoning by achieving state-of-the-art performance while allowing for explicit visualization of the decision sequence. However, the sparse reward signals offered by the KG during a traversal are often insufficient to guide a sophisticated reinforcement learning (RL) model. An alternate approach to KG reasoning is using traditional symbolic methods (e.g., rule induction), which achieve high precision without learning but are hard to generalize due to the limitation of symbolic representation. In this paper, we propose to fuse these two paradigms to get the best of both worlds. Our method leverages high-quality rules generated by symbolic-based methods to provide reward supervision for walk-based agents. Due to the structure of symbolic rules with their entity variables, we can separate our walk-based agent into two sub-agents thus allowing for additional efficiency. Experiments on public datasets demonstrate that walk-based models can benefit from rule guidance significantly.
TriggerNER: Learning with Entity Triggers as Explanations for Named Entity Recognition
Apr 24, 2020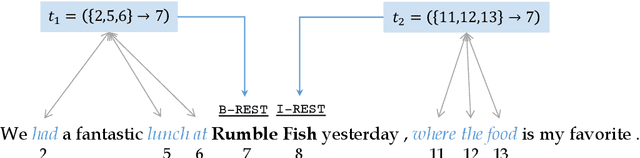
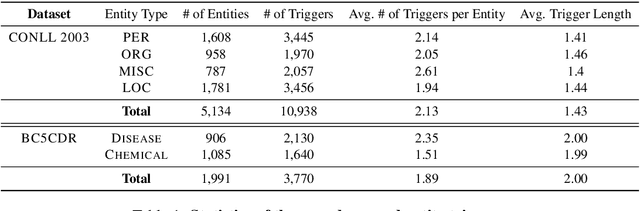
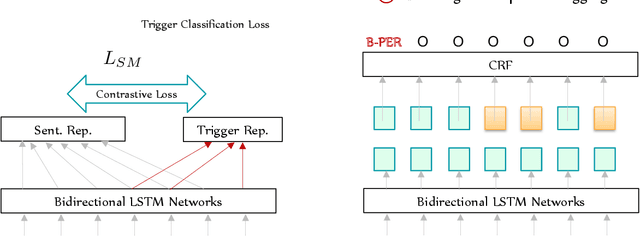
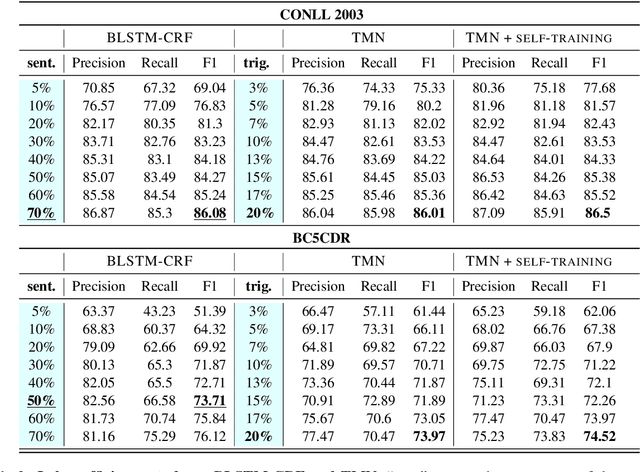
Training neural models for named entity recognition (NER) in a new domain often requires additional human annotations (e.g., tens of thousands of labeled instances) that are usually expensive and time-consuming to collect. Thus, a crucial research question is how to obtain supervision in a cost-effective way. In this paper, we introduce "entity triggers," an effective proxy of human explanations for facilitating label-efficient learning of NER models. An entity trigger is defined as a group of words in a sentence that helps to explain why humans would recognize an entity in the sentence. We crowd-sourced 14k entity triggers for two well-studied NER datasets. Our proposed model, Trigger Matching Network, jointly learns trigger representations and soft matching module with self-attention such that can generalize to unseen sentences easily for tagging. Our framework is significantly more cost-effective than the traditional neural NER frameworks. Experiments show that using only 20% of the trigger-annotated sentences results in a comparable performance as using 70% of conventional annotated sentences.
LEAN-LIFE: A Label-Efficient Annotation Framework Towards Learning from Explanation
Apr 16, 2020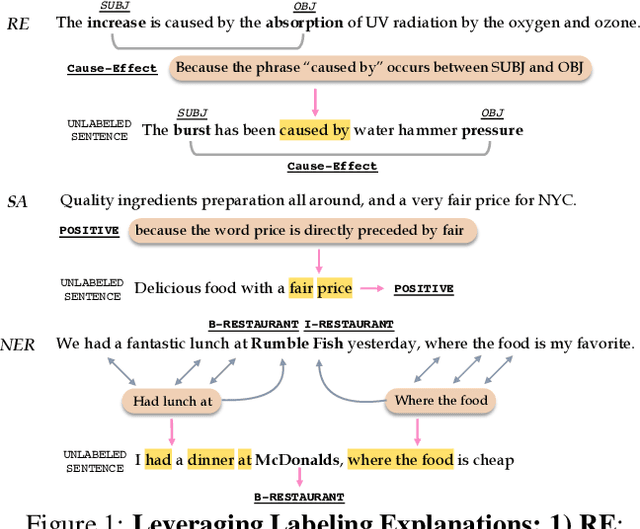
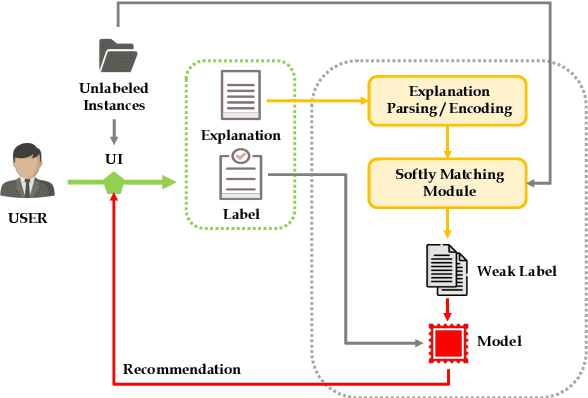

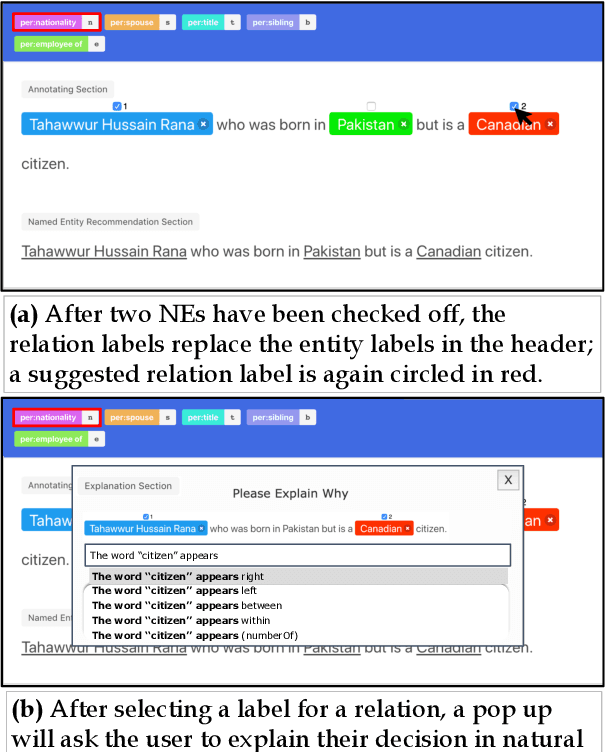
Successfully training a deep neural network demands a huge corpus of labeled data. However, each label only provides limited information to learn from and collecting the requisite number of labels involves massive human effort. In this work, we introduce LEAN-LIFE, a web-based, Label-Efficient AnnotatioN framework for sequence labeling and classification tasks, with an easy-to-use UI that not only allows an annotator to provide the needed labels for a task, but also enables LearnIng From Explanations for each labeling decision. Such explanations enable us to generate useful additional labeled data from unlabeled instances, bolstering the pool of available training data. On three popular NLP tasks (named entity recognition, relation extraction, sentiment analysis), we find that using this enhanced supervision allows our models to surpass competitive baseline F1 scores by more than 5-10 percentage points, while using 2X times fewer labeled instances. Our framework is the first to utilize this enhanced supervision technique and does so for three important tasks -- thus providing improved annotation recommendations to users and an ability to build datasets of (data, label, explanation) triples instead of the regular (data, label) pair.
Generating Natural Language Adversarial Examples on a Large Scale with Generative Models
Mar 10, 2020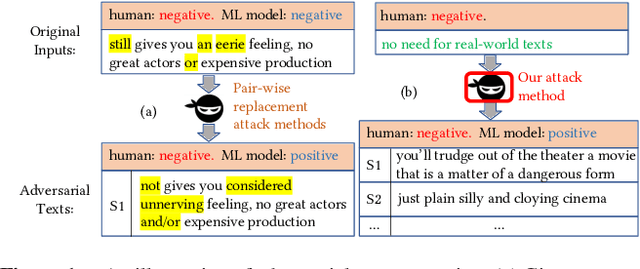

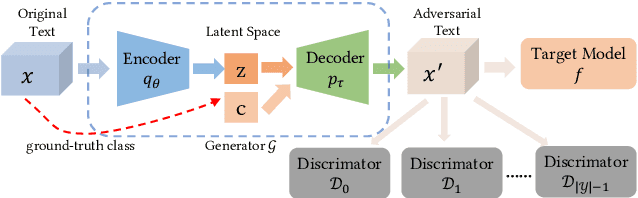

Today text classification models have been widely used. However, these classifiers are found to be easily fooled by adversarial examples. Fortunately, standard attacking methods generate adversarial texts in a pair-wise way, that is, an adversarial text can only be created from a real-world text by replacing a few words. In many applications, these texts are limited in numbers, therefore their corresponding adversarial examples are often not diverse enough and sometimes hard to read, thus can be easily detected by humans and cannot create chaos at a large scale. In this paper, we propose an end to end solution to efficiently generate adversarial texts from scratch using generative models, which are not restricted to perturbing the given texts. We call it unrestricted adversarial text generation. Specifically, we train a conditional variational autoencoder (VAE) with an additional adversarial loss to guide the generation of adversarial examples. Moreover, to improve the validity of adversarial texts, we utilize discrimators and the training framework of generative adversarial networks (GANs) to make adversarial texts consistent with real data. Experimental results on sentiment analysis demonstrate the scalability and efficiency of our method. It can attack text classification models with a higher success rate than existing methods, and provide acceptable quality for humans in the meantime.
Temporal Attribute Prediction via Joint Modeling of Multi-Relational Structure Evolution
Mar 09, 2020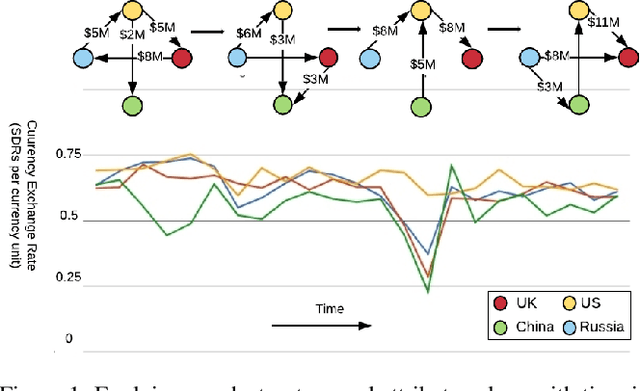
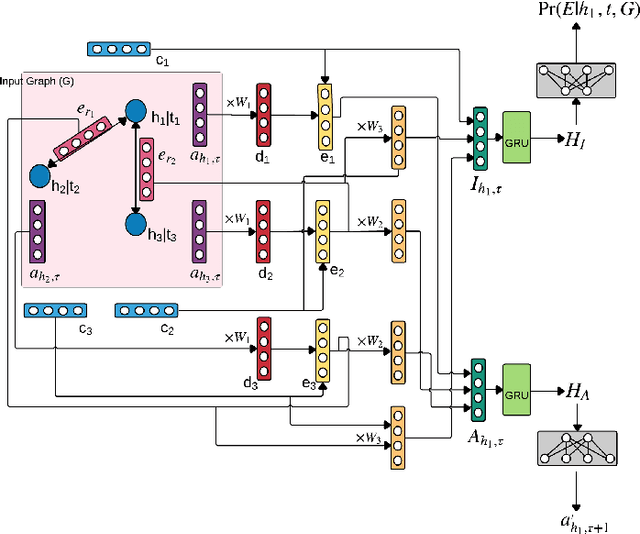
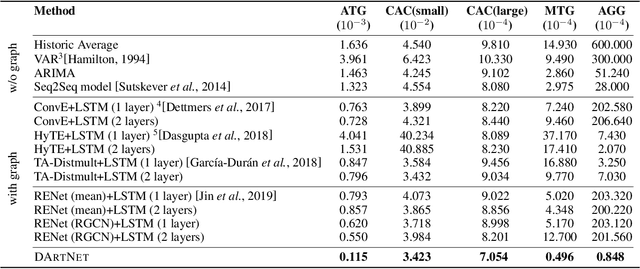
Time series prediction is an important problem in machine learning. Previous methods for time series prediction did not involve additional information. With a lot of dynamic knowledge graphs available, we can use this additional information to predict the time series better. Recently, there has been a focus on the application of deep representation learning on dynamic graphs. These methods predict the structure of the graph by reasoning over the interactions in the graph at previous time steps. In this paper, we propose a new framework to incorporate the information from dynamic knowledge graphs for time series prediction. We show that if the information contained in the graph and the time series data are closely related, then this inter-dependence can be used to predict the time series with improved accuracy. Our framework, DArtNet, learns a static embedding for every node in the graph as well as a dynamic embedding which is dependent on the dynamic attribute value (time-series). Then it captures the information from the neighborhood by taking a relation specific mean and encodes the history information using RNN. We jointly train the model link prediction and attribute prediction. We evaluate our method on five specially curated datasets for this problem and show a consistent improvement in time series prediction results.
Mining News Events from Comparable News Corpora: A Multi-Attribute Proximity Network Modeling Approach
Nov 14, 2019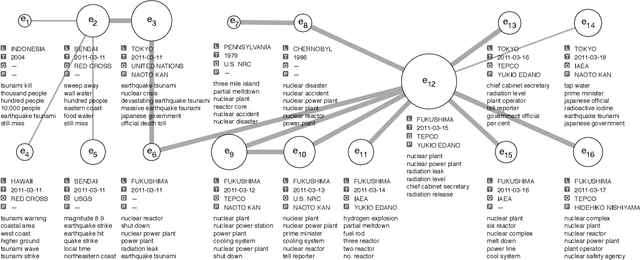
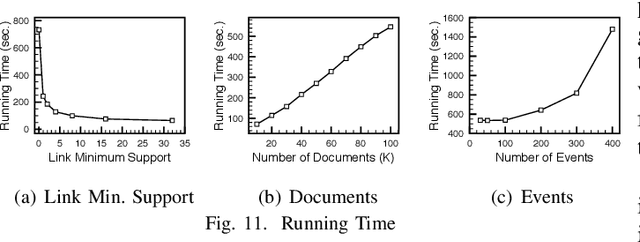
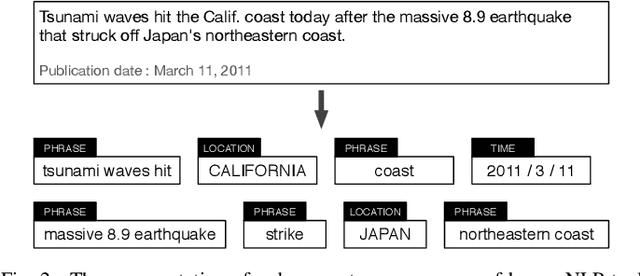
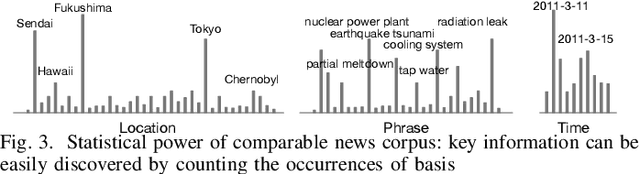
We present ProxiModel, a novel event mining framework for extracting high-quality structured event knowledge from large, redundant, and noisy news data sources. The proposed model differentiates itself from other approaches by modeling both the event correlation within each individual document as well as across the corpus. To facilitate this, we introduce the concept of a proximity-network, a novel space-efficient data structure to facilitate scalable event mining. This proximity network captures the corpus-level co-occurence statistics for candidate event descriptors, event attributes, as well as their connections. We probabilistically model the proximity network as a generative process with sparsity-inducing regularization. This allows us to efficiently and effectively extract high-quality and interpretable news events. Experiments on three different news corpora demonstrate that the proposed method is effective and robust at generating high-quality event descriptors and attributes. We briefly detail many interesting applications from our proposed framework such as news summarization, event tracking and multi-dimensional analysis on news. Finally, we explore a case study on visualizing the events for a Japan Tsunami news corpus and demonstrate ProxiModel's ability to automatically summarize emerging news events.
Improving BERT Fine-tuning with Embedding Normalization
Nov 10, 2019
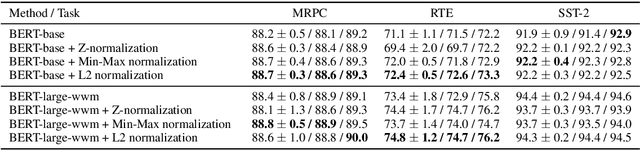
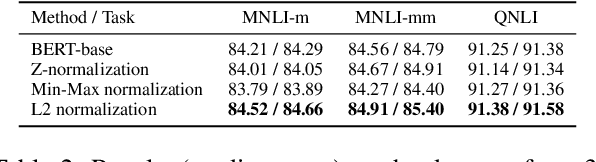
Large pre-trained sentence encoders like BERT start a new chapter in natural language processing. A common practice to apply pre-trained BERT to sequence classification tasks (e.g., classification of sentences or sentence pairs) is by feeding the embedding of [CLS] token (in the last layer) to a task-specific classification layer, and then fine tune the model parameters of BERT and classifier jointly. In this paper, we conduct systematic analysis over several sequence classification datasets to examine the embedding values of [CLS] token before the fine tuning phase, and present the biased embedding distribution issue---i.e., embedding values of [CLS] concentrate on a few dimensions and are non-zero centered. Such biased embedding brings challenge to the optimization process during fine-tuning as gradients of [CLS] embedding may explode and result in degraded model performance. We further propose several simple yet effective normalization methods to modify the [CLS] embedding during the fine-tuning. Compared with the previous practice, neural classification model with the normalized embedding shows improvements on several text classification tasks, demonstrates the effectiveness of our method.
CommonGen: A Constrained Text Generation Dataset Towards Generative Commonsense Reasoning
Nov 09, 2019

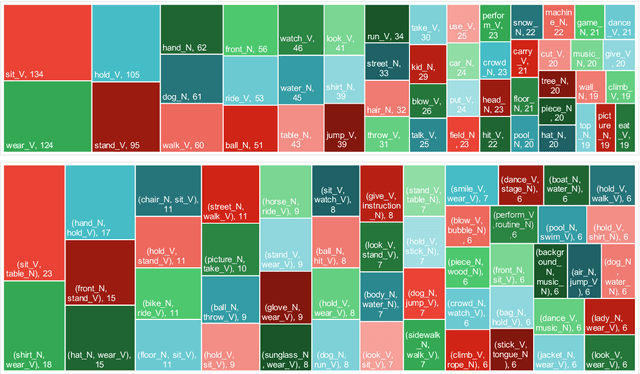
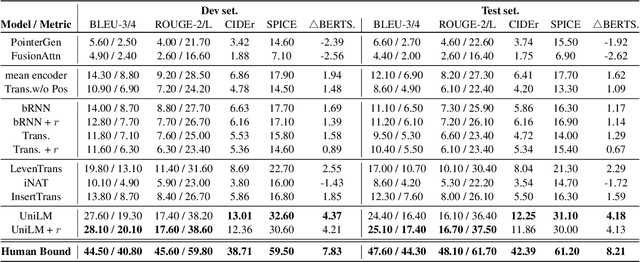
Rational humans can generate sentences that cover a certain set of concepts while describing natural and common scenes. For example, given {apple(noun), tree(noun), pick(verb)}, humans can easily come up with scenes like "a boy is picking an apple from a tree" via their generative commonsense reasoning ability. However, we find this capacity has not been well learned by machines. Most prior works in machine commonsense focus on discriminative reasoning tasks with a multi-choice question answering setting. Herein, we present CommonGen: a challenging dataset for testing generative commonsense reasoning with a constrained text generation task. We collect 37k concept-sets as inputs and 90k human-written sentences as associated outputs. Additionally, we also provide high-quality rationales behind the reasoning process for the development and test sets from the human annotators. We demonstrate the difficulty of the task by examining a wide range of sequence generation methods with both automatic metrics and human evaluation. The state-of-the-art pre-trained generation model, UniLM, is still far from human performance in this task. Our data and code is publicly available at http://inklab.usc.edu/CommonGen/ .
Towards Hierarchical Importance Attribution: Explaining Compositional Semantics for Neural Sequence Models
Nov 08, 2019
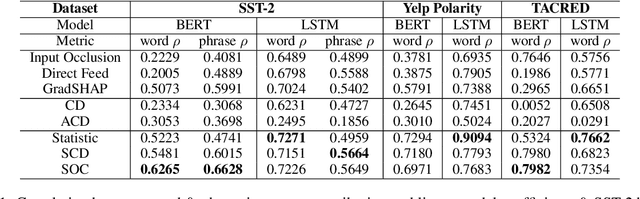
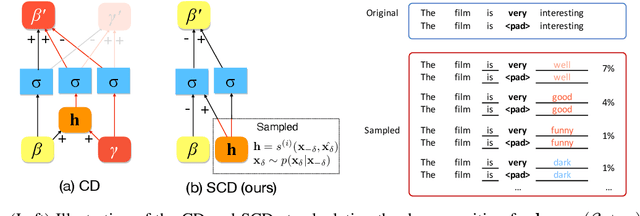

The impressive performance of neural networks on natural language processing tasks attributes to their ability to model complicated word and phrase interactions. Existing flat, word level explanations of predictions hardly unveil how neural networks handle compositional semantics to reach predictions. To tackle the challenge, we study hierarchical explanation of neural network predictions. We identify non-additivity and independent importance attributions within hierarchies as two desirable properties for highlighting word and phrase interactions. We show prior efforts on hierarchical explanations, e.g. contextual decomposition, however, do not satisfy the desired properties mathematically. In this paper, we propose a formal way to quantify the importance of each word or phrase for hierarchical explanations. Following the formulation, we propose Sampling and Contextual Decomposition (SCD) algorithm and Sampling and Occlusion (SOC) algorithm. Human and metrics evaluation on both LSTM models and BERT Transformer models on multiple datasets show that our algorithms outperform prior hierarchical explanation algorithms. Our algorithms apply to hierarchical visualization of compositional semantics, extraction of classification rules and improving human trust of models.
Learning to Annotate: Modularizing Data Augmentation for Text Classifiers with Natural Language Explanations
Nov 07, 2019

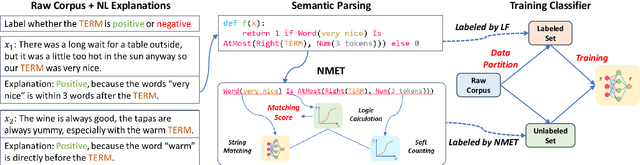
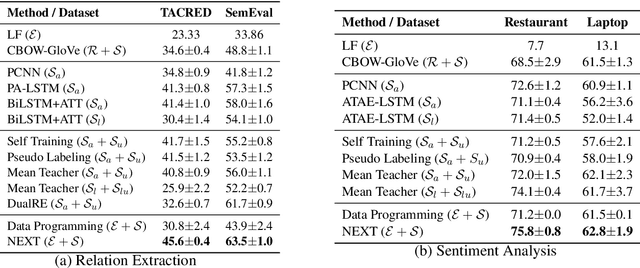
Deep neural networks usually require massive labeled data, which restricts their applications in scenarios where data annotation is expensive. Natural language (NL) explanations have been demonstrated very useful additional supervision, which can provide sufficient domain knowledge for generating more labeled data over new instances, while the annotation time only doubles. However, directly applying them for augmenting model learning encounters two challenges: (1) NL explanations are unstructured and inherently compositional. (2) NL explanations often have large numbers of linguistic variants, resulting in low recall and limited generalization ability. In this paper, we propose a novel Neural EXecution Tree (NEXT) framework to augment training data for text classification using NL explanations. After transforming NL explanations into executable logical forms by semantic parsing, NEXT generalizes different types of actions specified by the logical forms for labeling data instances, which substantially increases the coverage of each NL explanation. Experiments on two NLP tasks (relation extraction and sentiment analysis) demonstrate its superiority over baseline methods. Its extension to multi-hop question answering achieves performance gain with light annotation effort.