 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-Quant: Granular Semantic and Generative Structural Quantization for Knowledge Graph Completion
Apr 23, 2026Large Language Models (LLMs) have shown immense potential in Knowledge Graph Completion (KGC), yet bridging the modality gap between continuous graph embeddings and discrete LLM tokens remains a critical challenge. While recent quantization-based approaches attempt to align these modalities, they typically treat quantization as flat numerical compression, resulting in semantically entangled codes that fail to mirror the hierarchical nature of human reasoning. In this paper, we propose GS-Quant, a novel framework that generates semantically coherent and structurally stratified discrete codes for KG entities. Unlike prior methods, GS-Quant is grounded in the insight that entity representations should follow a linguistic coarse-to-fine logic. We introduce a Granular Semantic Enhancement module that injects hierarchical knowledge into the codebook, ensuring that earlier codes capture global semantic categories while later codes refine specific attributes. Furthermore, a Generative Structural Reconstruction module imposes causal dependencies on the code sequence, transforming independent discrete units into structured semantic descriptors. By expanding the LLM vocabulary with these learned codes, we enable the model to reason over graph structures isomorphically to natural language generation. Experimental results demonstrate that GS-Quant significantly outperforms existing text-based and embedding-based baselines. Our code is publicly available at https://github.com/mikumifa/GS-Quant.
AutoMS: Multi-Agent Evolutionary Search for Cross-Physics Inverse Microstructure Design
Mar 28, 2026Designing microstructures that satisfy coupled cross-physics objectives is a fundamental challenge in material science. This inverse design problem involves a vast, discontinuous search space where traditional topology optimization is computationally prohibitive, and deep generative models often suffer from "physical hallucinations," lacking the capability to ensure rigorous validity. To address this limitation, we introduce AutoMS, a multi-agent neuro-symbolic framework that reformulates inverse design as an LLM-driven evolutionary search. Unlike methods that treat LLMs merely as interfaces, AutoMS integrates them as "semantic navigators" to initialize search spaces and break local optima, while our novel Simulation-Aware Evolutionary Search (SAES) addresses the "blindness" of traditional evolutionary strategies. Specifically, SAES utilizes simulation feedback to perform local gradient approximation and directed parameter updates, effectively guiding the search toward physically valid Pareto frontiers. Orchestrating specialized agents (Manager, Parser, Generator, and Simulator), AutoMS achieves a state-of-the-art 83.8\% success rate on 17 diverse cross-physics tasks, nearly doubling the performance of traditional NSGA-II (43.7\%) and significantly outperforming ReAct-based LLM baselines (53.3\%). Furthermore, our hierarchical architecture reduces total execution time by 23.3\%. AutoMS demonstrates that autonomous agent systems can effectively navigate complex physical landscapes, bridging the gap between semantic design intent and rigorous physical validity.
Bridging Academia and Industry: A Comprehensive Benchmark for Attributed Graph Clustering
Feb 09, 2026Attributed Graph Clustering (AGC) is a fundamental unsupervised task that integrates structural topology and node attributes to uncover latent patterns in graph-structured data. Despite its significance in industrial applications such as fraud detection and user segmentation, a significant chasm persists between academic research and real-world deployment. Current evaluation protocols suffer from the small-scale, high-homophily citation datasets, non-scalable full-batch training paradigms, and a reliance on supervised metrics that fail to reflect performance in label-scarce environments. To bridge these gaps, we present PyAGC, a comprehensive, production-ready benchmark and library designed to stress-test AGC methods across diverse scales and structural properties. We unify existing methodologies into a modular Encode-Cluster-Optimize framework and, for the first time, provide memory-efficient, mini-batch implementations for a wide array of state-of-the-art AGC algorithms. Our benchmark curates 12 diverse datasets, ranging from 2.7K to 111M nodes, specifically incorporating industrial graphs with complex tabular features and low homophily. Furthermore, we advocate for a holistic evaluation protocol that mandates unsupervised structural metrics and efficiency profiling alongside traditional supervised metrics. Battle-tested in high-stakes industrial workflows at Ant Group, this benchmark offers the community a robust, reproducible, and scalable platform to advance AGC research towards realistic deployment. The code and resources are publicly available via GitHub (https://github.com/Cloudy1225/PyAGC), PyPI (https://pypi.org/project/pyagc), and Documentation (https://pyagc.readthedocs.io).
Watermarking Large Language Model-based Time Series Forecasting
Jul 28, 2025Large Language Model-based Time Series Forecasting (LLMTS) has shown remarkable promise in handling complex and diverse temporal data, representing a significant step toward foundation models for time series analysis. However, this emerging paradigm introduces two critical challenges. First, the substantial commercial potential and resource-intensive development raise urgent concerns about intellectual property (IP) protection. Second, their powerful time series forecasting capabilities may be misused to produce misleading or fabricated deepfake time series data. To address these concerns, we explore watermarking the outputs of LLMTS models, that is, embedding imperceptible signals into the generated time series data that remain detectable by specialized algorithms. We propose a novel post-hoc watermarking framework, Waltz, which is broadly compatible with existing LLMTS models. Waltz is inspired by the empirical observation that time series patch embeddings are rarely aligned with a specific set of LLM tokens, which we term ``cold tokens''. Leveraging this insight, Waltz embeds watermarks by rewiring the similarity statistics between patch embeddings and cold token embeddings, and detects watermarks using similarity z-scores. To minimize potential side effects, we introduce a similarity-based embedding position identification strategy and employ projected gradient descent to constrain the watermark noise within a defined boundary. Extensive experiments using two popular LLMTS models across seven benchmark datasets demonstrate that Waltz achieves high watermark detection accuracy with minimal impact on the quality of the generated time series.
A Real-time Endoscopic Image Denoising System
Jun 18, 2025


Endoscopes featuring a miniaturized design have significantly enhanced operational flexibility, portability, and diagnostic capability while substantially reducing the invasiveness of medical procedures. Recently, single-use endoscopes equipped with an ultra-compact analogue image sensor measuring less than 1mm x 1mm bring revolutionary advancements to medical diagnosis. They reduce the structural redundancy and large capital expenditures associated with reusable devices, eliminate the risk of patient infections caused by inadequate disinfection, and alleviate patient suffering. However, the limited photosensitive area results in reduced photon capture per pixel, requiring higher photon sensitivity settings to maintain adequate brightness. In high-contrast medical imaging scenarios, the small-sized sensor exhibits a constrained dynamic range, making it difficult to simultaneously capture details in both highlights and shadows, and additional localized digital gain is required to compensate. Moreover, the simplified circuit design and analog signal transmission introduce additional noise sources. These factors collectively contribute to significant noise issues in processed endoscopic images. In this work, we developed a comprehensive noise model for analog image sensors in medical endoscopes, addressing three primary noise types: fixed-pattern noise, periodic banding noise, and mixed Poisson-Gaussian noise. Building on this analysis, we propose a hybrid denoising system that synergistically combines traditional image processing algorithms with advanced learning-based techniques for captured raw frames from sensors. Experiments demonstrate that our approach effectively reduces image noise without fine detail loss or color distortion, while achieving real-time performance on FPGA platforms and an average PSNR improvement from 21.16 to 33.05 on our test dataset.
M-HOF-Opt: Multi-Objective Hierarchical Output Feedback Optimization via Multiplier Induced Loss Landscape Scheduling
Mar 20, 2024



When a neural network parameterized loss function consists of many terms, the combinatorial choice of weight multipliers during the optimization process forms a challenging problem. To address this, we proposed a probabilistic graphical model (PGM) for the joint model parameter and multiplier evolution process, with a hypervolume based likelihood that promotes multi-objective descent of each loss term. The corresponding parameter and multiplier estimation as a sequential decision process is then cast into an optimal control problem, where the multi-objective descent goal is dispatched hierarchically into a series of constraint optimization sub-problems. The sub-problem constraint automatically adapts itself according to Pareto dominance and serves as the setpoint for the low level multiplier controller to schedule loss landscapes via output feedback of each loss term. Our method is multiplier-free and operates at the timescale of epochs, thus saves tremendous computational resources compared to full training cycle multiplier tuning. We applied it to domain invariant variational auto-encoding with 6 loss terms on the PACS domain generalization task, and observed robust performance across a range of controller hyperparameters, as well as different multiplier initial conditions, outperforming other multiplier scheduling methods. We offered modular implementation of our method, admitting custom definition of many loss terms for applying our multi-objective hierarchical output feedback training scheme to other deep learning fields.
Joint Learning of Network Topology and Opinion Dynamics Based on Bandit Algorithms
Jun 25, 2023



We study joint learning of network topology and a mixed opinion dynamics, in which agents may have different update rules. Such a model captures the diversity of real individual interactions. We propose a learning algorithm based on multi-armed bandit algorithms to address the problem. The goal of the algorithm is to find each agent's update rule from several candidate rules and to learn the underlying network. At each iteration, the algorithm assumes that each agent has one of the updated rules and then modifies network estimates to reduce validation error. Numerical experiments show that the proposed algorithm improves initial estimates of the network and update rules, decreases prediction error, and performs better than other methods such as sparse linear regression and Gaussian process regression.
On the Convergence of mSGD and AdaGrad for Stochastic Optimization
Jan 26, 2022As one of the most fundamental stochastic optimization algorithms, stochastic gradient descent (SGD) has been intensively developed and extensively applied in machine learning in the past decade. There have been some modified SGD-type algorithms, which outperform the SGD in many competitions and applications in terms of convergence rate and accuracy, such as momentum-based SGD (mSGD) and adaptive gradient algorithm (AdaGrad). Despite these empirical successes, the theoretical properties of these algorithms have not been well established due to technical difficulties. With this motivation, we focus on convergence analysis of mSGD and AdaGrad for any smooth (possibly non-convex) loss functions in stochastic optimization. First, we prove that the iterates of mSGD are asymptotically convergent to a connected set of stationary points with probability one, which is more general than existing works on subsequence convergence or convergence of time averages. Moreover, we prove that the loss function of mSGD decays at a certain rate faster than that of SGD. In addition, we prove the iterates of AdaGrad are asymptotically convergent to a connected set of stationary points with probability one. Also, this result extends the results from the literature on subsequence convergence and the convergence of time averages. Despite the generality of the above convergence results, we have relaxed some assumptions of gradient noises, convexity of loss functions, as well as boundedness of iterates.
CommonGen: A Constrained Text Generation Dataset Towards Generative Commonsense Reasoning
Nov 09, 2019

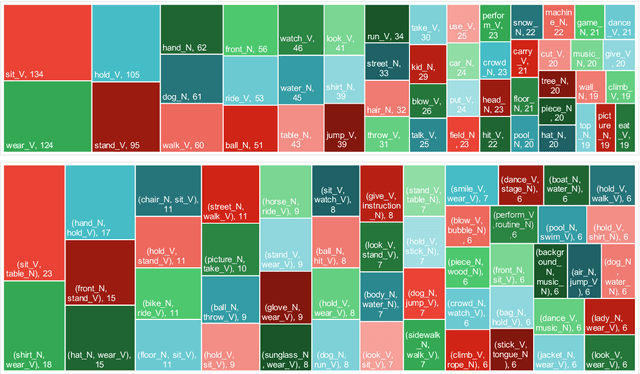
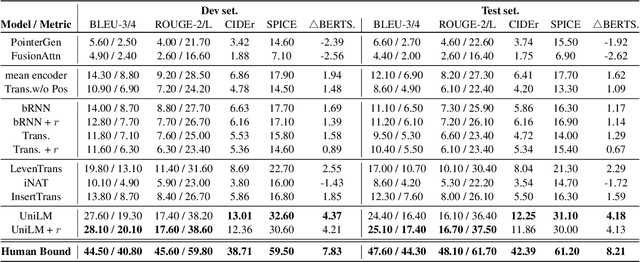
Rational humans can generate sentences that cover a certain set of concepts while describing natural and common scenes. For example, given {apple(noun), tree(noun), pick(verb)}, humans can easily come up with scenes like "a boy is picking an apple from a tree" via their generative commonsense reasoning ability. However, we find this capacity has not been well learned by machines. Most prior works in machine commonsense focus on discriminative reasoning tasks with a multi-choice question answering setting. Herein, we present CommonGen: a challenging dataset for testing generative commonsense reasoning with a constrained text generation task. We collect 37k concept-sets as inputs and 90k human-written sentences as associated outputs. Additionally, we also provide high-quality rationales behind the reasoning process for the development and test sets from the human annotators. We demonstrate the difficulty of the task by examining a wide range of sequence generation methods with both automatic metrics and human evaluation. The state-of-the-art pre-trained generation model, UniLM, is still far from human performance in this task. Our data and code is publicly available at http://inklab.usc.edu/CommonGen/ .
A Novel User Representation Paradigm for Making Personalized Candidate Retrieval
Jul 15, 2019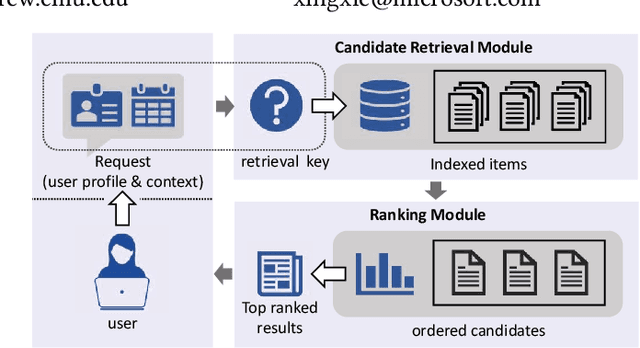
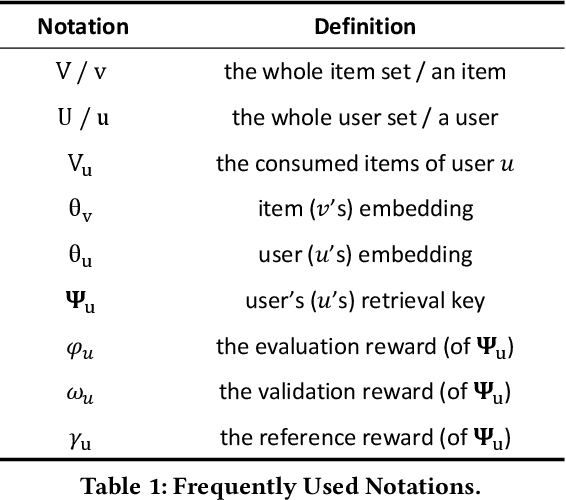
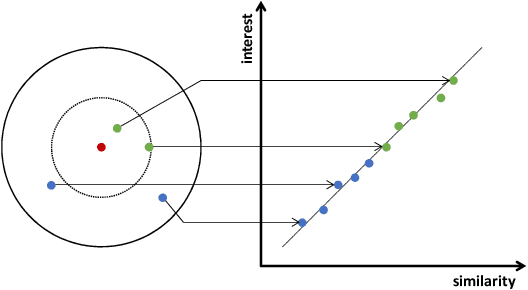
Candidate retrieval is a crucial part in recommendation system, where quality candidates need to be selected in realtime for user's recommendation request. Conventional methods would make use of feature similarity directly for highly scalable retrieval, yet their retrieval quality can be limited due to inferior user interest modeling. In contrast, deep learning-based recommenders are precise in modeling user interest, but they are difficult to be scaled for efficient candidate retrieval. In this work, a novel paradigm Synthonet is proposed for both precise and scalable candidate retrieval. With Synthonet, user is represented as a compact vector known as retrieval key. By developing an Actor-Critic learning framework, the generation of retrieval key is optimally conducted, such that the similarity between retrieval key and item's representation will accurately reflect user's interest towards the corresponding item. Consequently, quality candidates can be acquired in realtime on top of highly efficient similarity search methods. Comprehensive empirical studies are carried out for the verification of our proposed methods, where consistent and remarkable improvements are achieved over a series of competitive baselines, including representative variations on metric learning.