 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Twin for O-RAN Towards 6G
Oct 03, 2024In future wireless systems of beyond 5G and 6G, addressing diverse applications with varying quality requirements is essential. Open Radio Access Network (O-RAN) architectures offer the potential for dynamic resource adaptation based on traffic demands. However, achieving real-time resource orchestration remains a challenge. Simultaneously, Digital Twin (DT) technology holds promise for testing and analysing complex systems, offering a unique platform for addressing dynamic operation and automation in O-RAN architectures. Yet, developing DTs for complex 5G/6G networks poses challenges, including data exchanges, ML model training data availability, network dynamics, processing power limitations, interdisciplinary collaboration needs, and a lack of standardized methodologies. This paper provides an overview of Open RAN architecture, trend and challenges, proposing the DT concepts for O-RAN with solution examples showcasing its integration into the framework.
MARVEL: Multidimensional Abstraction and Reasoning through Visual Evaluation and Learning
Apr 24, 2024



While multi-modal large language models (MLLMs) have shown significant progress on many popular visual reasoning benchmarks, whether they possess abstract visual reasoning abilities remains an open question. Similar to the Sudoku puzzles, abstract visual reasoning (AVR) problems require finding high-level patterns (e.g., repetition constraints) that control the input shapes (e.g., digits) in a specific task configuration (e.g., matrix). However, existing AVR benchmarks only considered a limited set of patterns (addition, conjunction), input shapes (rectangle, square), and task configurations (3 by 3 matrices). To evaluate MLLMs' reasoning abilities comprehensively, we introduce MARVEL, a multidimensional AVR benchmark with 770 puzzles composed of six core knowledge patterns, geometric and abstract shapes, and five different task configurations. To inspect whether the model accuracy is grounded in perception and reasoning, MARVEL complements the general AVR question with perception questions in a hierarchical evaluation framework. We conduct comprehensive experiments on MARVEL with nine representative MLLMs in zero-shot and few-shot settings. Our experiments reveal that all models show near-random performance on the AVR question, with significant performance gaps (40%) compared to humans across all patterns and task configurations. Further analysis of perception questions reveals that MLLMs struggle to comprehend the visual features (near-random performance) and even count the panels in the puzzle ( <45%), hindering their ability for abstract reasoning. We release our entire code and dataset.
The Curious Case of Nonverbal Abstract Reasoning with Multi-Modal Large Language Models
Jan 22, 2024



While large language models (LLMs) are still being adopted to new domains and utilized in novel applications, we are experiencing an influx of the new generation of foundation models, namely multi-modal large language models (MLLMs). These models integrate verbal and visual information, opening new possibilities to demonstrate more complex reasoning abilities at the intersection of the two modalities. However, despite the revolutionizing prospect of MLLMs, our understanding of their reasoning abilities is limited. In this study, we assess the nonverbal abstract reasoning abilities of open-source and closed-source MLLMs using variations of Raven's Progressive Matrices. Our experiments expose the difficulty of solving such problems while showcasing the immense gap between open-source and closed-source models. We also reveal critical shortcomings with individual visual and textual modules, subjecting the models to low-performance ceilings. Finally, to improve MLLMs' performance, we experiment with various methods, such as Chain-of-Thought prompting, resulting in a significant (up to 100%) boost in performance.
Table-based Fact Verification with Salience-aware Learning
Sep 09, 2021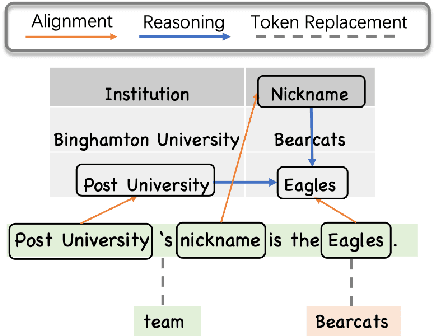
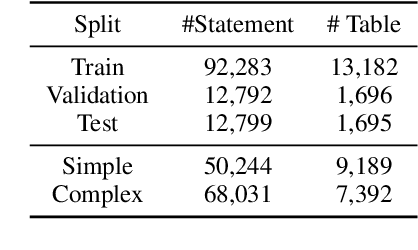
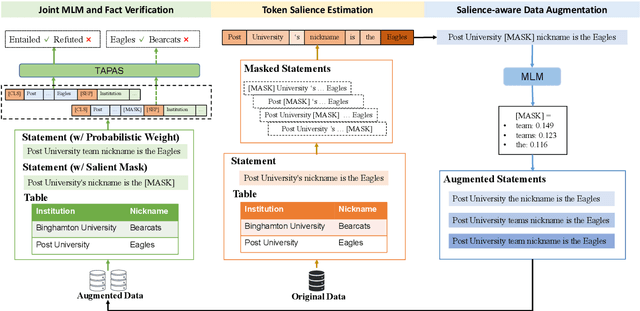
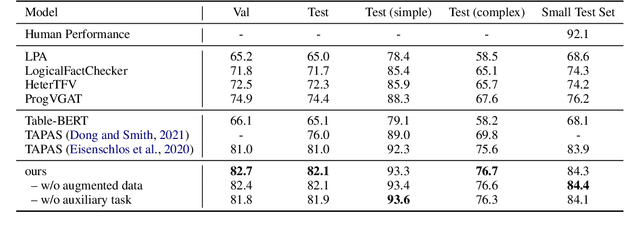
Tables provide valuable knowledge that can be used to verify textual statements. While a number of works have considered table-based fact verification, direct alignments of tabular data with tokens in textual statements are rarely available. Moreover, training a generalized fact verification model requires abundant labeled training data. In this paper, we propose a novel system to address these problems. Inspired by counterfactual causality, our system identifies token-level salience in the statement with probing-based salience estimation. Salience estimation allows enhanced learning of fact verification from two perspectives. From one perspective, our system conducts masked salient token prediction to enhance the model for alignment and reasoning between the table and the statement. From the other perspective, our system applies salience-aware data augmentation to generate a more diverse set of training instances by replacing non-salient terms. Experimental results on TabFact show the effective improvement by the proposed salience-aware learning techniques, leading to the new SOTA performance on the benchmark. Our code is publicly available at https://github.com/luka-group/Salience-aware-Learning .
Retrieving Complex Tables with Multi-Granular Graph Representation Learning
May 04, 2021
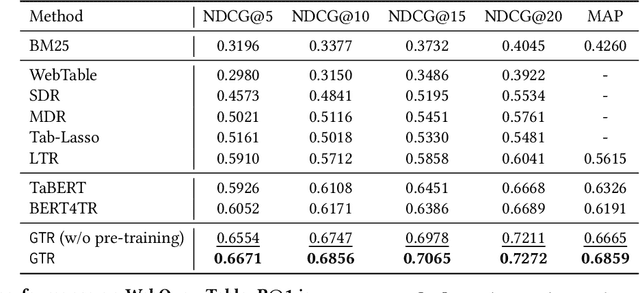
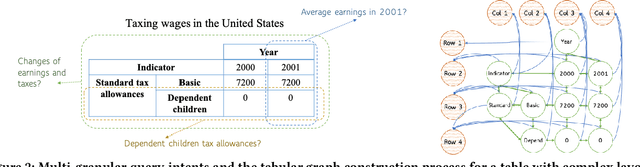
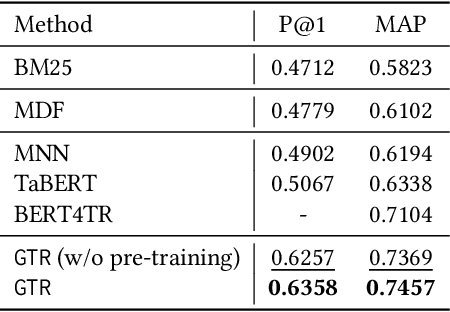
The task of natural language table retrieval (NLTR) seeks to retrieve semantically relevant tables based on natural language queries. Existing learning systems for this task often treat tables as plain text based on the assumption that tables are structured as dataframes. However, tables can have complex layouts which indicate diverse dependencies between subtable structures, such as nested headers. As a result, queries may refer to different spans of relevant content that is distributed across these structures. Moreover, such systems fail to generalize to novel scenarios beyond those seen in the training set. Prior methods are still distant from a generalizable solution to the NLTR problem, as they fall short in handling complex table layouts or queries over multiple granularities. To address these issues, we propose Graph-based Table Retrieval (GTR), a generalizable NLTR framework with multi-granular graph representation learning. In our framework, a table is first converted into a tabular graph, with cell nodes, row nodes and column nodes to capture content at different granularities. Then the tabular graph is input to a Graph Transformer model that can capture both table cell content and the layout structures. To enhance the robustness and generalizability of the model, we further incorporate a self-supervised pre-training task based on graph-context matching. Experimental results on two benchmarks show that our method leads to significant improvements over the current state-of-the-art systems. Further experiments demonstrate promising performance of our method on cross-dataset generalization, and enhanced capability of handling complex tables and fulfilling diverse query intents. Code and data are available at https://github.com/FeiWang96/GTR.
Learning Collaborative Agents with Rule Guidance for Knowledge Graph Reasoning
May 01, 2020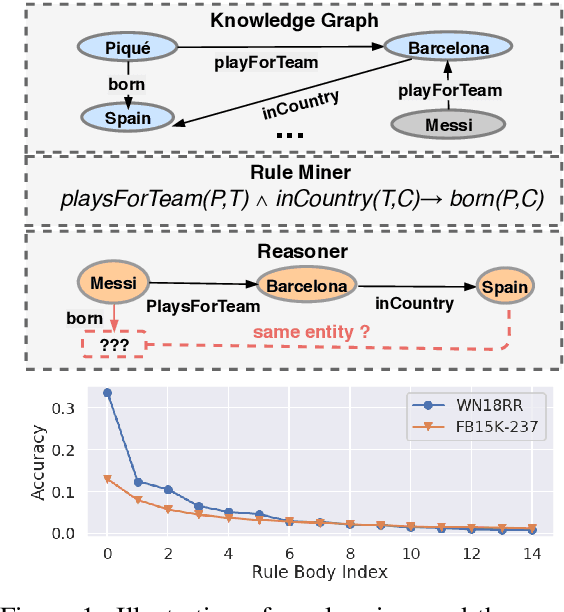
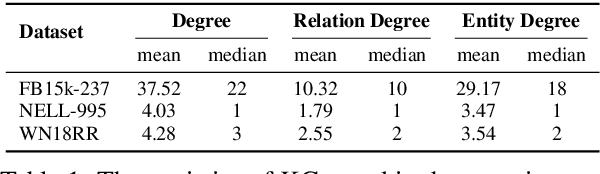
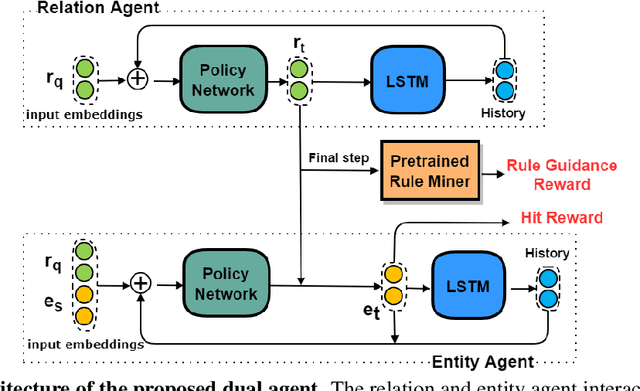
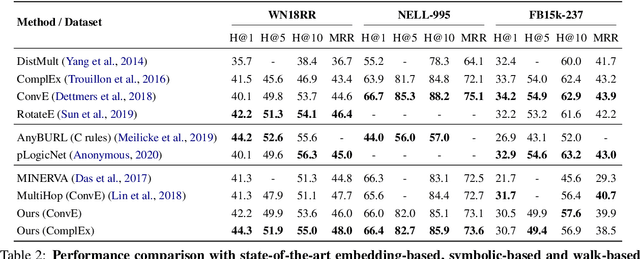
Walk-based models have shown their unique advantages in knowledge graph (KG) reasoning by achieving state-of-the-art performance while allowing for explicit visualization of the decision sequence. However, the sparse reward signals offered by the KG during a traversal are often insufficient to guide a sophisticated reinforcement learning (RL) model. An alternate approach to KG reasoning is using traditional symbolic methods (e.g., rule induction), which achieve high precision without learning but are hard to generalize due to the limitation of symbolic representation. In this paper, we propose to fuse these two paradigms to get the best of both worlds. Our method leverages high-quality rules generated by symbolic-based methods to provide reward supervision for walk-based agents. Due to the structure of symbolic rules with their entity variables, we can separate our walk-based agent into two sub-agents thus allowing for additional efficiency. Experiments on public datasets demonstrate that walk-based models can benefit from rule guidance significantly.