 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetune like you pretrain: Improved finetuning of zero-shot vision models
Dec 01, 2022



Finetuning image-text models such as CLIP achieves state-of-the-art accuracies on a variety of benchmarks. However, recent works like WiseFT (Wortsman et al., 2021) and LP-FT (Kumar et al., 2022) have shown that even subtle differences in the finetuning process can lead to surprisingly large differences in the final performance, both for in-distribution (ID) and out-of-distribution (OOD) data. In this work, we show that a natural and simple approach of mimicking contrastive pretraining consistently outperforms alternative finetuning approaches. Specifically, we cast downstream class labels as text prompts and continue optimizing the contrastive loss between image embeddings and class-descriptive prompt embeddings (contrastive finetuning). Our method consistently outperforms baselines across 7 distribution shifts, 6 transfer learning, and 3 few-shot learning benchmarks. On WILDS-iWILDCam, our proposed approach FLYP outperforms the top of the leaderboard by $2.3\%$ ID and $2.7\%$ OOD, giving the highest reported accuracy. Averaged across 7 OOD datasets (2 WILDS and 5 ImageNet associated shifts), FLYP gives gains of $4.2\%$ OOD over standard finetuning and outperforms the current state of the art (LP-FT) by more than $1\%$ both ID and OOD. Similarly, on 3 few-shot learning benchmarks, our approach gives gains up to $4.6\%$ over standard finetuning and $4.4\%$ over the state of the art. In total, these benchmarks establish contrastive finetuning as a simple, intuitive, and state-of-the-art approach for supervised finetuning of image-text models like CLIP. Code is available at https://github.com/locuslab/FLYP.
Temporal Attribute Prediction via Joint Modeling of Multi-Relational Structure Evolution
Mar 09, 2020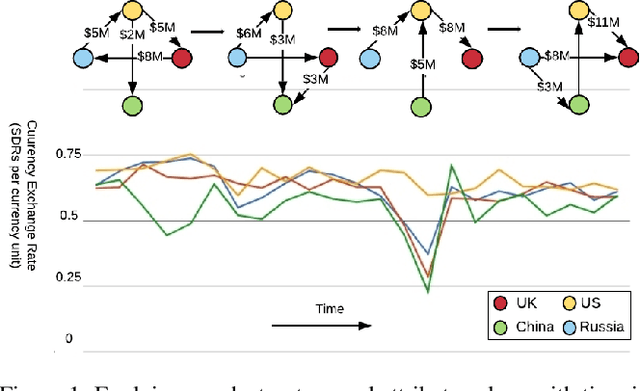
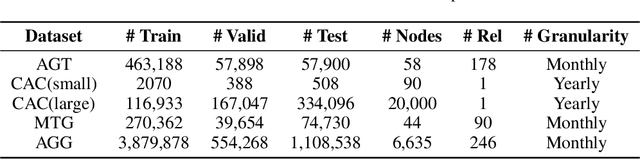
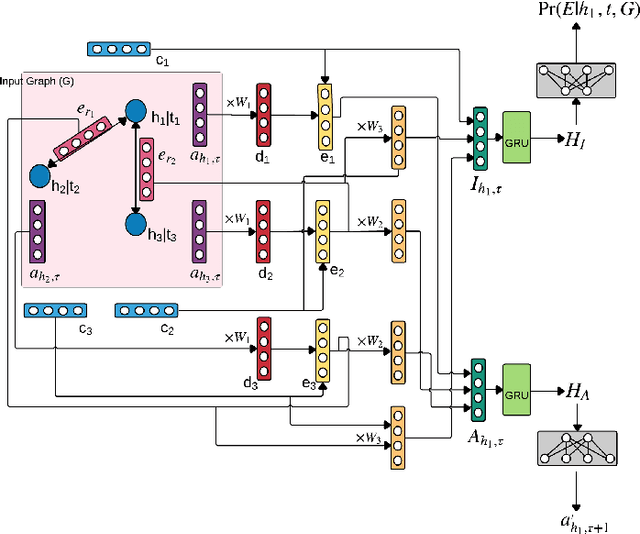
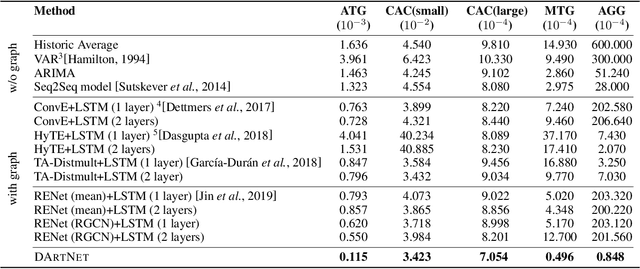
Time series prediction is an important problem in machine learning. Previous methods for time series prediction did not involve additional information. With a lot of dynamic knowledge graphs available, we can use this additional information to predict the time series better. Recently, there has been a focus on the application of deep representation learning on dynamic graphs. These methods predict the structure of the graph by reasoning over the interactions in the graph at previous time steps. In this paper, we propose a new framework to incorporate the information from dynamic knowledge graphs for time series prediction. We show that if the information contained in the graph and the time series data are closely related, then this inter-dependence can be used to predict the time series with improved accuracy. Our framework, DArtNet, learns a static embedding for every node in the graph as well as a dynamic embedding which is dependent on the dynamic attribute value (time-series). Then it captures the information from the neighborhood by taking a relation specific mean and encodes the history information using RNN. We jointly train the model link prediction and attribute prediction. We evaluate our method on five specially curated datasets for this problem and show a consistent improvement in time series prediction results.
Generalized Neural Policies for Relational MDPs
Feb 18, 2020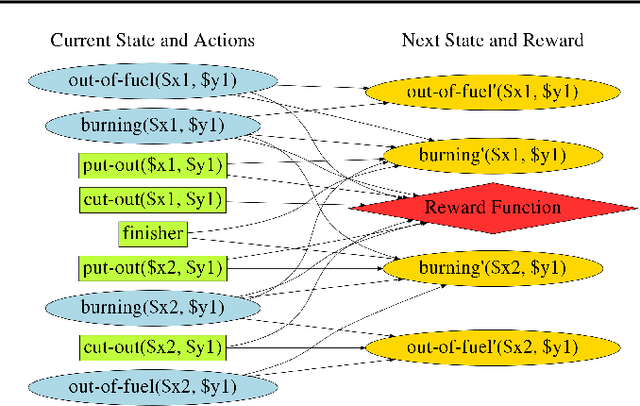
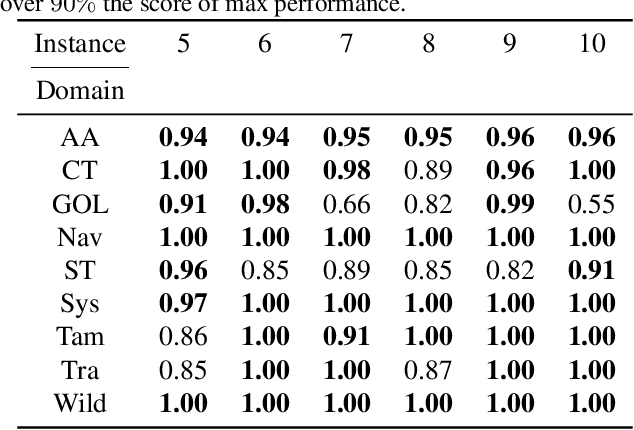
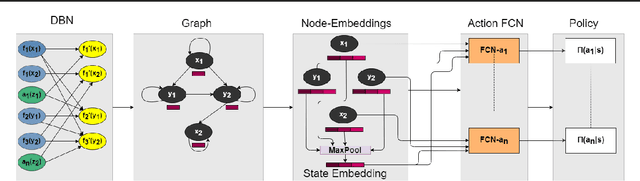
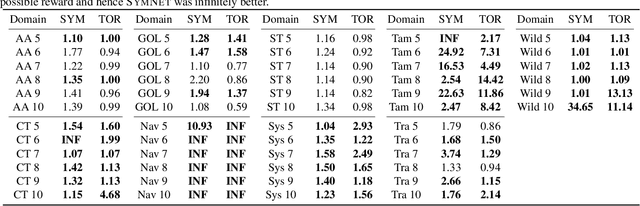
A Relational Markov Decision Process (RMDP) is a first-order representation to express all instances of a single probabilistic planning domain with possibly unbounded number of objects. Early work in RMDPs outputs generalized (instance-independent) first-order policies or value functions as a means to solve all instances of a domain at once. Unfortunately, this line of work met with limited success due to inherent limitations of the representation space used in such policies or value functions. Can neural models provide the missing link by easily representing more complex generalized policies, thus making them effective on all instances of a given domain? We present the first neural approach for solving RMDPs, expressed in the probabilistic planning language of RDDL. Our solution first converts an RDDL instance into a ground DBN. We then extract a graph structure from the DBN. We train a relational neural model that computes an embedding for each node in the graph and also scores each ground action as a function over the first-order action variable and object embeddings on which the action is applied. In essence, this represents a neural generalized policy for the whole domain. Given a new test problem of the same domain, we can compute all node embeddings using trained parameters and score each ground action to choose the best action using a single forward pass without any retraining. Our experiments on nine RDDL domains from IPPC demonstrate that neural generalized policies are significantly better than random and sometimes even more effective than training a state-of-the-art deep reactive policy from scratch.
Size Independent Neural Transfer for RDDL Planning
Apr 04, 2019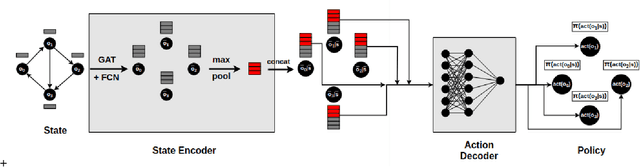
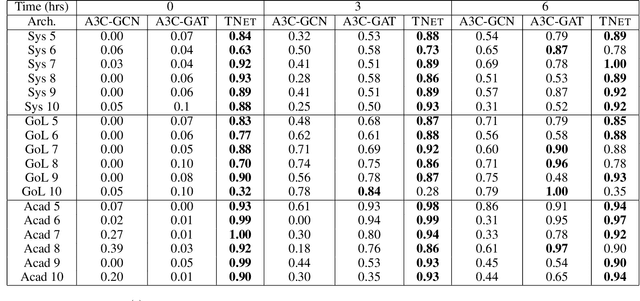
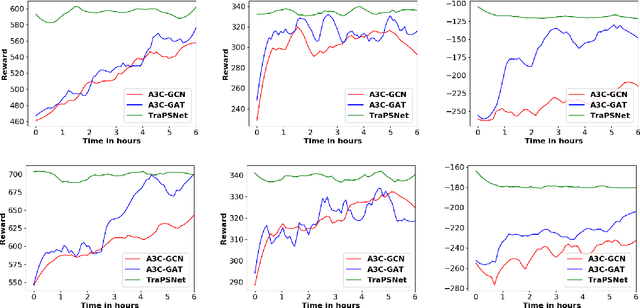
Neural planners for RDDL MDPs produce deep reactive policies in an offline fashion. These scale well with large domains, but are sample inefficient and time-consuming to train from scratch for each new problem. To mitigate this, recent work has studied neural transfer learning, so that a generic planner trained on other problems of the same domain can rapidly transfer to a new problem. However, this approach only transfers across problems of the same size. We present the first method for neural transfer of RDDL MDPs that can transfer across problems of different sizes. Our architecture has two key innovations to achieve size independence: (1) a state encoder, which outputs a fixed length state embedding by max pooling over varying number of object embeddings, (2) a single parameter-tied action decoder that projects object embeddings into action probabilities for the final policy. On the two challenging RDDL domains of SysAdmin and Game Of Life, our approach powerfully transfers across problem sizes and has superior learning curves over training from scratch.
Transfer of Deep Reactive Policies for MDP Planning
Oct 26, 2018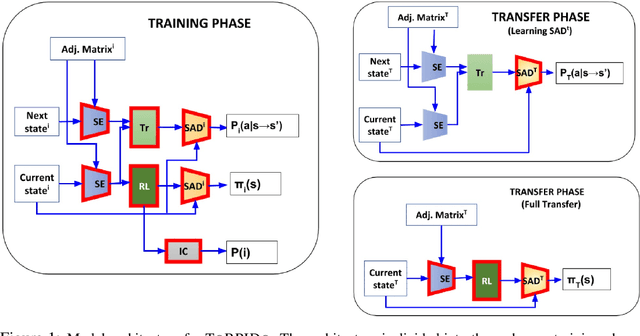
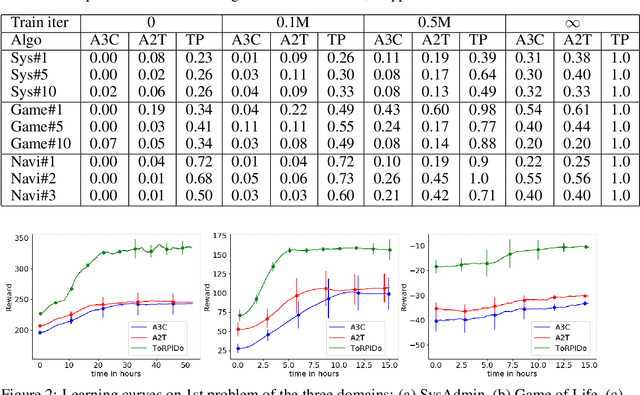
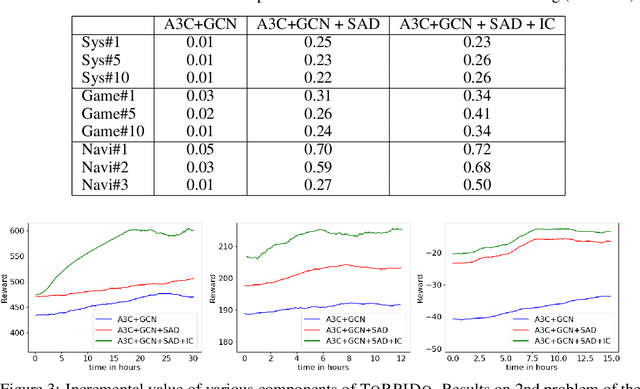
Domain-independent probabilistic planners input an MDP description in a factored representation language such as PPDDL or RDDL, and exploit the specifics of the representation for faster planning. Traditional algorithms operate on each problem instance independently, and good methods for transferring experience from policies of other instances of a domain to a new instance do not exist. Recently, researchers have begun exploring the use of deep reactive policies, trained via deep reinforcement learning (RL), for MDP planning domains. One advantage of deep reactive policies is that they are more amenable to transfer learning. In this paper, we present the first domain-independent transfer algorithm for MDP planning domains expressed in an RDDL representation. Our architecture exploits the symbolic state configuration and transition function of the domain (available via RDDL) to learn a shared embedding space for states and state-action pairs for all problem instances of a domain. We then learn an RL agent in the embedding space, making a near zero-shot transfer possible, i.e., without much training on the new instance, and without using the domain simulator at all. Experiments on three different benchmark domains underscore the value of our transfer algorithm. Compared against planning from scratch, and a state-of-the-art RL transfer algorithm, our transfer solution has significantly superior learning curves.