 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChEmREF: Evaluating Language Model Readiness for Chemical Emergency Response
Nov 14, 2025Emergency responders managing hazardous material HAZMAT incidents face critical, time-sensitive decisions, manually navigating extensive chemical guidelines. We investigate whether today's language models can assist responders by rapidly and reliably understanding critical information, identifying hazards, and providing recommendations. We introduce the Chemical Emergency Response Evaluation Framework (ChEmREF), a new benchmark comprising questions on 1,035 HAZMAT chemicals from the Emergency Response Guidebook and the PubChem Database. ChEmREF is organized into three tasks: (1) translation of chemical representation between structured and unstructured forms (e.g., converting C2H6O to ethanol), (2) emergency response generation (e.g., recommending appropriate evacuation distances) and (3) domain knowledge question answering from chemical safety and certification exams. Our best evaluated models received an exact match of 68.0% on unstructured HAZMAT chemical representation translation, a LLM Judge score of 52.7% on incident response recommendations, and a multiple-choice accuracy of 63.9% on HAMZAT examinations. These findings suggest that while language models show potential to assist emergency responders in various tasks, they require careful human oversight due to their current limitations.
Stress-Testing Long-Context Language Models with Lifelong ICL and Task Haystack
Jul 23, 2024We introduce Lifelong ICL, a problem setting that challenges long-context language models (LMs) to learn from a sequence of language tasks through in-context learning (ICL). We further introduce Task Haystack, an evaluation suite dedicated to assessing and diagnosing how long-context LMs utilizes contexts in Lifelong ICL. When given a task instruction and test inputs, long-context LMs are expected to leverage the relevant demonstrations in the Lifelong ICL prompt, avoid distraction and interference from other tasks, and achieve test accuracies that are not significantly worse than the Single-task ICL baseline. Task Haystack draws inspiration from the widely-adopted "needle-in-a-haystack" (NIAH) evaluation, but presents new and unique challenges. It demands that models (1) utilize the contexts with deeper understanding, rather than resorting to simple copying and pasting; (2) navigate through long streams of evolving topics and tasks, which closely approximates the complexities of real-world usage of long-context LMs. Additionally, Task Haystack inherits the controllability aspect of NIAH, providing model developers with tools and visualizations to identify model vulnerabilities effectively. We benchmark 12 long-context LMs using Task Haystack. We find that state-of-the-art closed models such as GPT-4o still struggle in this setting, failing 15% of the cases on average, while all open-weight models we evaluate further lack behind by a large margin, failing up to 61% of the cases. In our controlled analysis, we identify factors such as distraction and recency bias as contributors to these failure cases. Further, we observe declines in performance when task instructions are paraphrased at test time or when ICL demonstrations are repeated excessively, raising concerns about the robustness, instruction understanding, and true context utilization of current long-context LMs.
Prompt Engineering a Prompt Engineer
Nov 09, 2023Prompt engineering is a challenging yet crucial task for optimizing the performance of large language models (LLMs). It requires complex reasoning to examine the model's errors, hypothesize what is missing or misleading in the current prompt, and communicate the task with clarity. While recent works indicate that LLMs can be meta-prompted to perform automatic prompt engineering, their potentials may not be fully untapped due to the lack of sufficient guidance to elicit complex reasoning capabilities in LLMs in the meta-prompt. In this work, we investigate the problem of "prompt engineering a prompt engineer" -- constructing a meta-prompt that more effectively guides LLMs to perform automatic prompt engineering. We introduce and analyze key components, such as a step-by-step reasoning template and context specification, which lead to improved performance. In addition, inspired by common optimization concepts such as batch size, step size and momentum, we introduce their verbalized counterparts to the meta-prompt and investigate their effects. Our final method, named PE2, finds a prompt that outperforms "let's think step by step" by 6.3% on the MultiArith dataset and 3.1% on the GSM8K dataset. To demonstrate its versatility, we apply PE2 to the Instruction Induction benchmark, a suite of counterfactual tasks, and a lengthy, real-world industrial prompt. In these settings, PE2 achieves strong performance and outperforms prior automatic prompt engineering baselines. Further, we show that PE2 makes meaningful and targeted prompt edits, amends erroneous or incomplete prompts, and presents non-trivial counterfactual reasoning abilities.
How Predictable Are Large Language Model Capabilities? A Case Study on BIG-bench
May 24, 2023



We investigate the predictability of large language model (LLM) capabilities: given records of past experiments using different model families, numbers of parameters, tasks, and numbers of in-context examples, can we accurately predict LLM performance on new experiment configurations? Answering this question has practical implications for LLM users (e.g., deciding which models to try), developers (e.g., prioritizing evaluation on representative tasks), and the research community (e.g., identifying hard-to-predict capabilities that warrant further investigation). We study the performance prediction problem on experiment records from BIG-bench. On a random train-test split, an MLP-based predictor achieves RMSE below 5%, demonstrating the presence of learnable patterns within the experiment records. Further, we formulate the problem of searching for "small-bench," an informative subset of BIG-bench tasks from which the performance of the full set can be maximally recovered, and find a subset as informative for evaluating new model families as BIG-bench Hard, while being 3x smaller.
Estimating Large Language Model Capabilities without Labeled Test Data
May 24, 2023



Large Language Models (LLMs) have exhibited an impressive ability to perform in-context learning (ICL) from only a few examples, but the success of ICL varies widely from task to task. Thus, it is important to quickly determine whether ICL is applicable to a new task, but directly evaluating ICL accuracy can be expensive in situations where test data is expensive to annotate -- the exact situations where ICL is most appealing. In this paper, we propose the task of ICL accuracy estimation, in which we predict the accuracy of an LLM when doing in-context learning on a new task given only unlabeled data for that task. To perform ICL accuracy estimation, we propose a method that trains a meta-model using LLM confidence scores as features. We compare our method to several strong accuracy estimation baselines on a new benchmark that covers 4 LLMs and 3 task collections. On average, the meta-model improves over all baselines and achieves the same estimation performance as directly evaluating on 40 labeled test examples per task, across the total 12 settings. We encourage future work to improve on our methods and evaluate on our ICL accuracy estimation benchmark to deepen our understanding of when ICL works.
Eliciting Transferability in Multi-task Learning with Task-level Mixture-of-Experts
May 25, 2022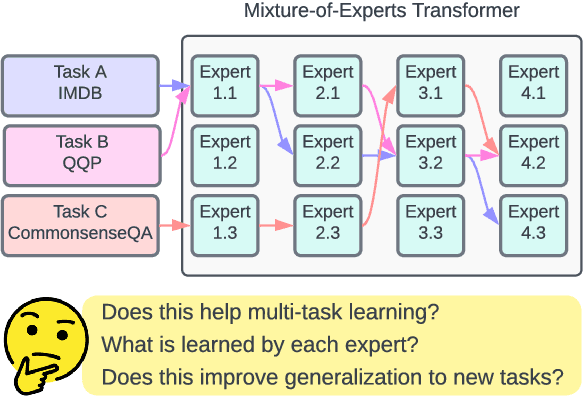
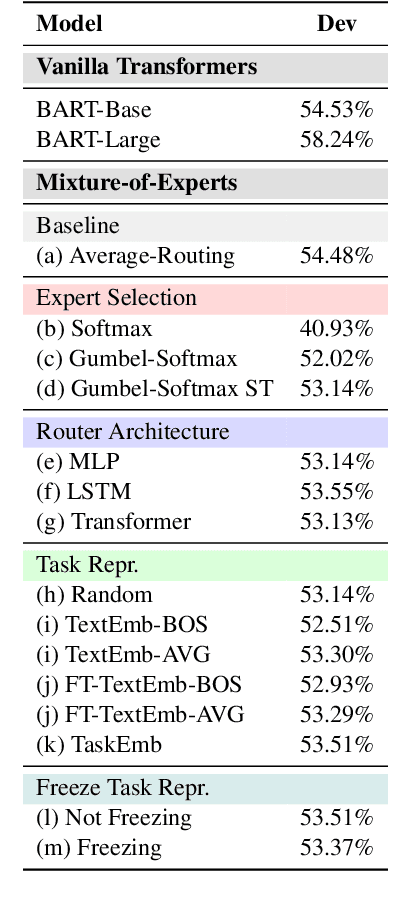
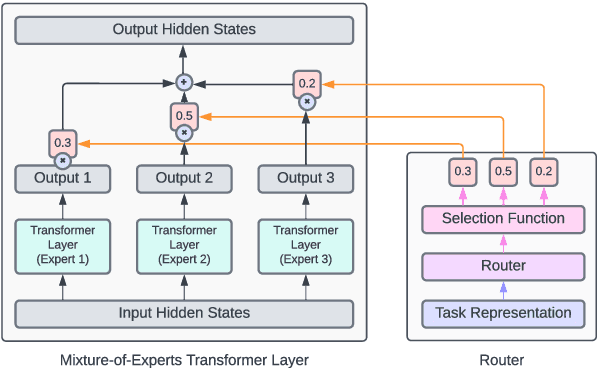
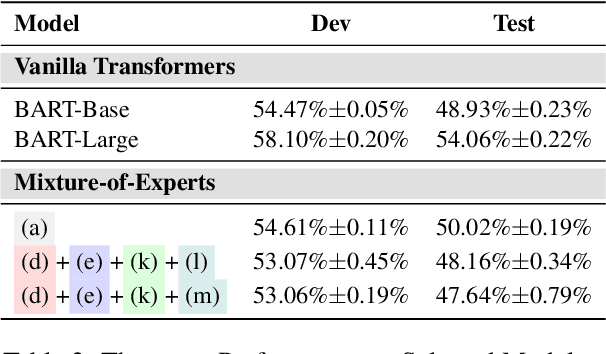
Recent work suggests that transformer models are capable of multi-task learning on diverse NLP tasks. However, the potential of these models may be limited as they use the same set of parameters for all tasks. In contrast, humans tackle tasks in a more flexible way, by making proper presumptions on what skills and knowledge are relevant and executing only the necessary computations. Inspired by this, we propose to use task-level mixture-of-expert models, which has a collection of transformer layers (i.e., experts) and a router component to choose among these experts dynamically and flexibly. We show that the learned routing decisions and experts partially rediscover human categorization of NLP tasks -- certain experts are strongly associated with extractive tasks, some with classification tasks, and some with tasks requiring world knowledge.
Sparse Distillation: Speeding Up Text Classification by Using Bigger Models
Oct 16, 2021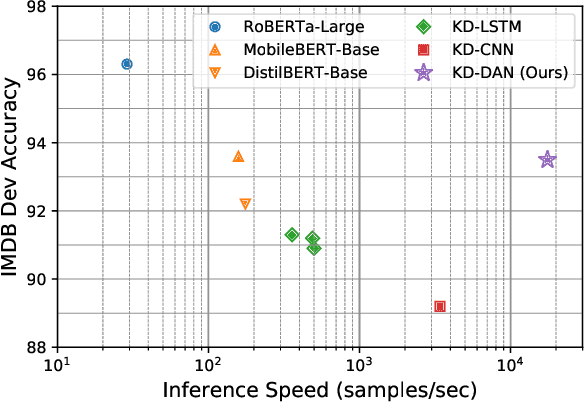
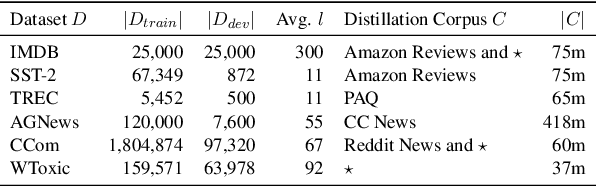
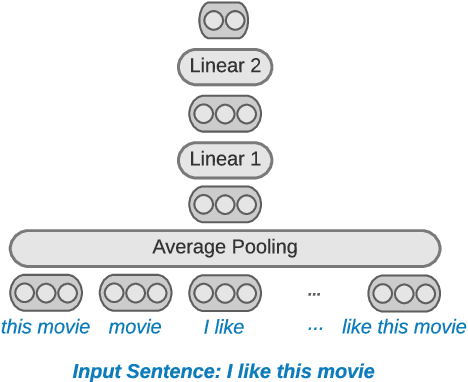
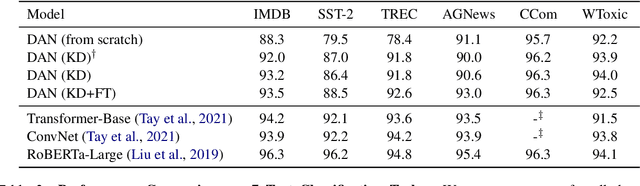
Distilling state-of-the-art transformer models into lightweight student models is an effective way to reduce computation cost at inference time. However, the improved inference speed may be still unsatisfactory for certain time-sensitive applications. In this paper, we aim to further push the limit of inference speed by exploring a new area in the design space of the student model. More specifically, we consider distilling a transformer-based text classifier into a billion-parameter, sparsely-activated student model with a embedding-averaging architecture. Our experiments show that the student models retain 97% of the RoBERTa-Large teacher performance on a collection of six text classification tasks. Meanwhile, the student model achieves up to 600x speed-up on both GPUs and CPUs, compared to the teacher models. Further investigation shows that our pipeline is also effective in privacy-preserving and domain generalization settings.
On the Influence of Masking Policies in Intermediate Pre-training
Apr 18, 2021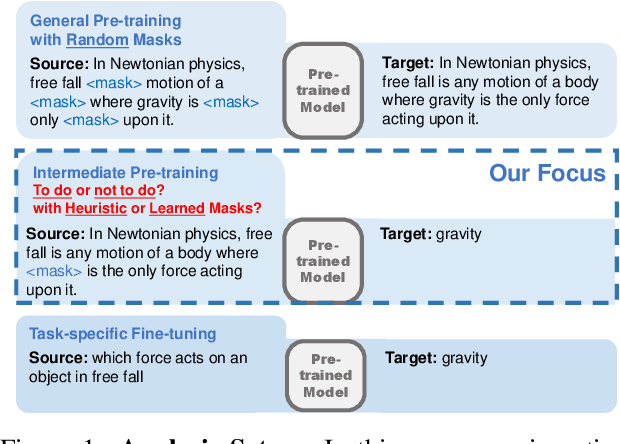
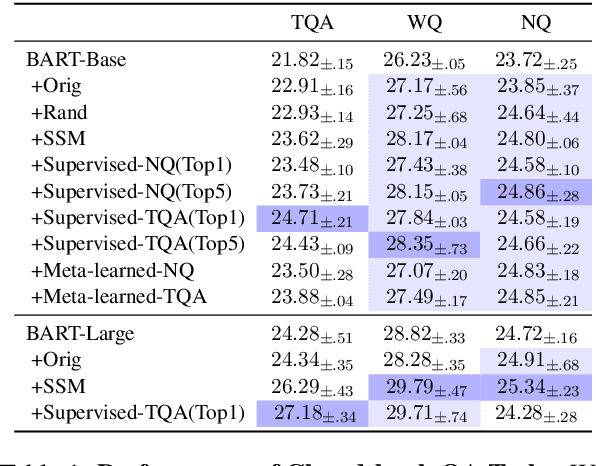
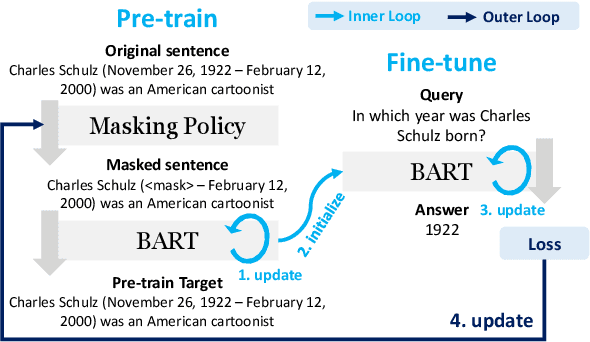
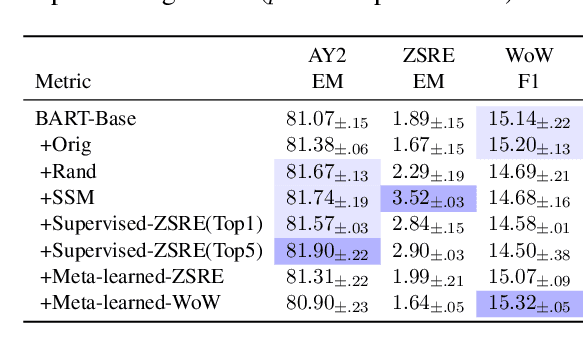
Current NLP models are predominantly trained through a pretrain-then-finetune pipeline, where models are first pretrained on a large text corpus with a masked-language-modelling (MLM) objective, then finetuned on the downstream task. Prior work has shown that inserting an intermediate pre-training phase, with heuristic MLM objectives that resemble downstream tasks, can significantly improve final performance. However, it is still unclear (1) in what cases such intermediate pre-training is helpful, (2) whether hand-crafted heuristic objectives are optimal for a given task, and (3) whether a MLM policy designed for one task is generalizable beyond that task. In this paper, we perform a large-scale empirical study to investigate the effect of various MLM policies in intermediate pre-training. Crucially, we introduce methods to automate discovery of optimal MLM policies, by learning a masking model through either direct supervision or meta-learning on the downstream task. We investigate the effects of using heuristic, directly supervised, and meta-learned MLM policies for intermediate pretraining, on eight selected tasks across three categories (closed-book QA, knowledge-intensive language tasks, and abstractive summarization). Most notably, we show that learned masking policies outperform the heuristic of masking named entities on TriviaQA, and masking policies learned on one task can positively transfer to other tasks in certain cases.
CrossFit: A Few-shot Learning Challenge for Cross-task Generalization in NLP
Apr 18, 2021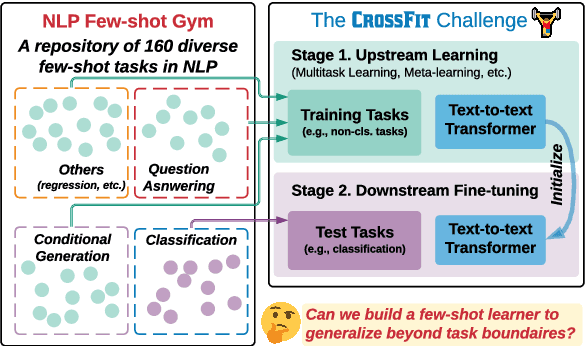
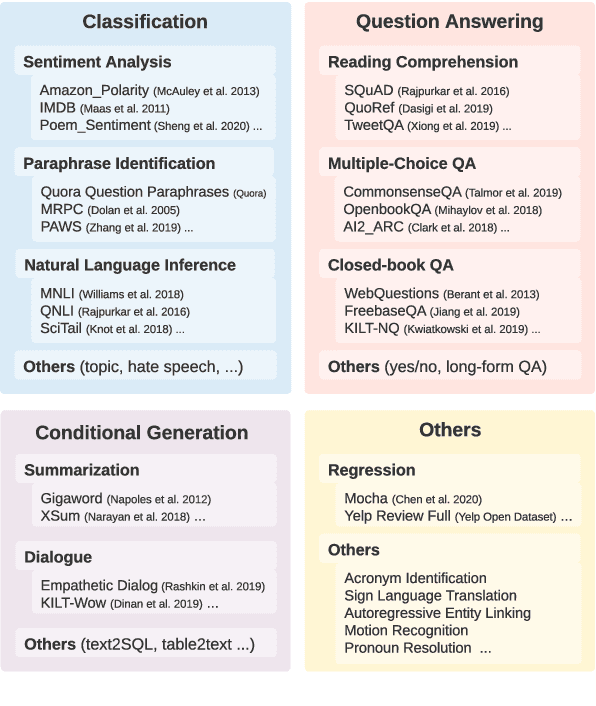
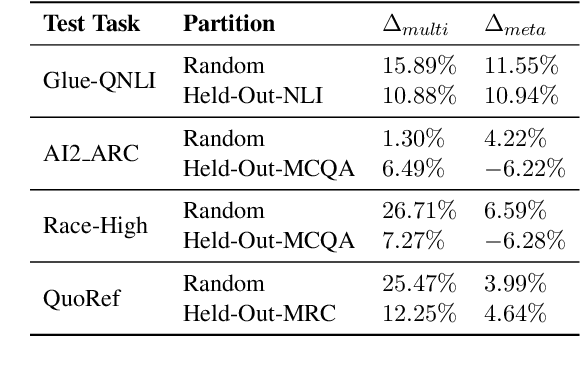
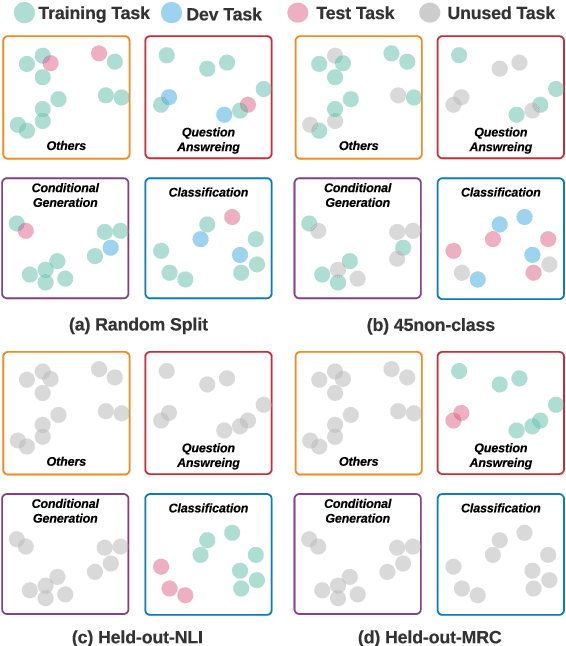
Humans can learn a new language task more efficiently than machines, conceivably by leveraging their prior experience and knowledge in learning other tasks. In this paper, we explore whether such cross-task generalization ability can be acquired, and further applied to build better few-shot learners across diverse NLP tasks. We introduce CrossFit, a task setup for studying cross-task few-shot learning ability, which standardizes seen/unseen task splits, data access during different learning stages, and the evaluation protocols. In addition, we present NLP Few-shot Gym, a repository of 160 few-shot NLP tasks, covering diverse task categories and applications, and converted to a unified text-to-text format. Our empirical analysis reveals that the few-shot learning ability on unseen tasks can be improved via an upstream learning stage using a set of seen tasks. Additionally, the advantage lasts into medium-resource scenarios when thousands of training examples are available. We also observe that selection of upstream learning tasks can significantly influence few-shot performance on unseen tasks, asking further analysis on task similarity and transferability.
Refining Neural Networks with Compositional Explanations
Mar 18, 2021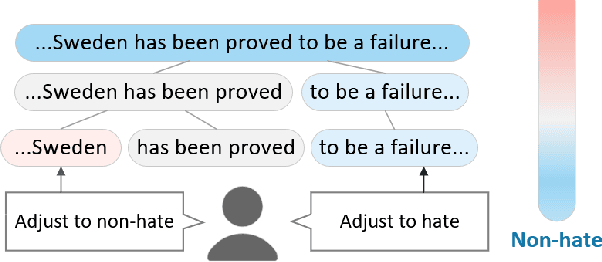
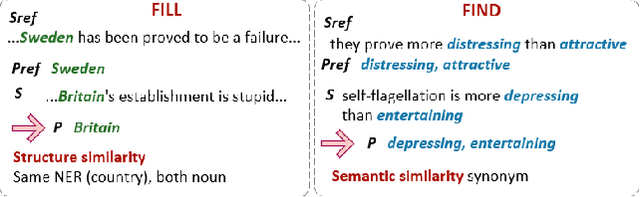


Neural networks are prone to learning spurious correlations from biased datasets, and are thus vulnerable when making inferences in a new target domain. Prior work reveals spurious patterns via post-hoc model explanations which compute the importance of input features, and further eliminates the unintended model behaviors by regularizing importance scores with human knowledge. However, such regularization technique lacks flexibility and coverage, since only importance scores towards a pre-defined list of features are adjusted, while more complex human knowledge such as feature interaction and pattern generalization can hardly be incorporated. In this work, we propose to refine a learned model by collecting human-provided compositional explanations on the models' failure cases. By describing generalizable rules about spurious patterns in the explanation, more training examples can be matched and regularized, tackling the challenge of regularization coverage. We additionally introduce a regularization term for feature interaction to support more complex human rationale in refining the model. We demonstrate the effectiveness of the proposed approach on two text classification tasks by showing improved performance in target domain after refinement.