 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual VQA: A Cause-Effect Look at Language Bias
Jun 15, 2020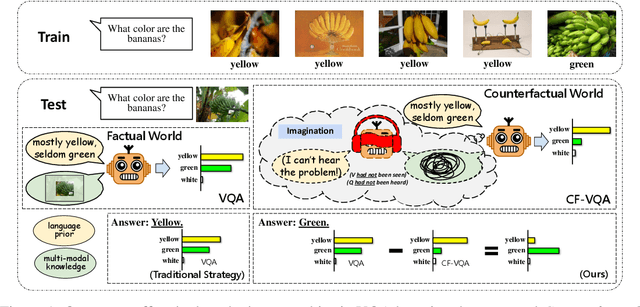
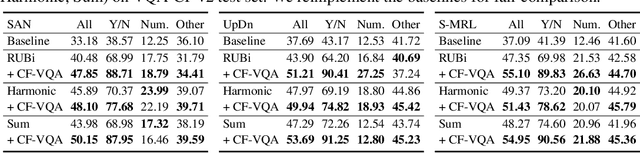
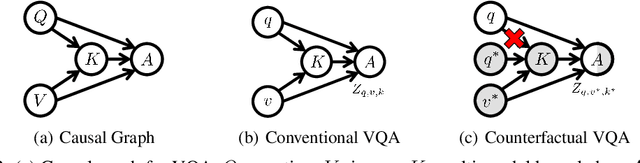
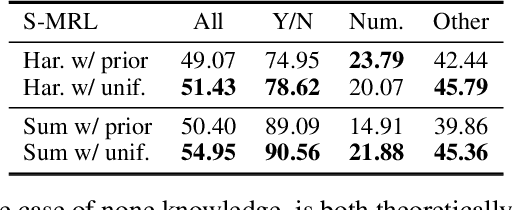
Visual Question Answering (VQA) models tend to rely on the language bias and thus fail to learn the reasoning from visual knowledge, which is however the original intention of VQA. In this paper, we propose a novel cause-effect look at the language bias, where the bias is formulated as the direct effect of question on answer from the view of causal inference. The effect can be captured by counterfactual VQA, where the image had not existed in an imagined scenario. Our proposed cause-effect look 1) is general to any baseline VQA architecture, 2) achieves significant improvement on the language-bias sensitive VQA-CP dataset, and 3) fills the theoretical gap in recent language prior based works.
PyRetri: A PyTorch-based Library for Unsupervised Image Retrieval by Deep Convolutional Neural Networks
May 02, 2020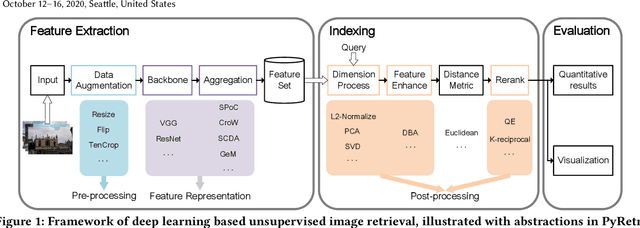
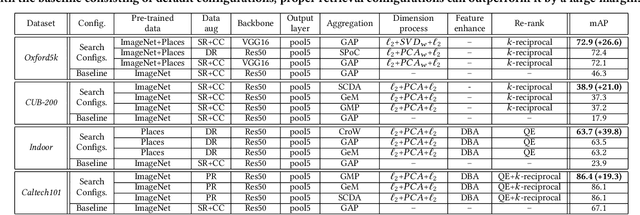

Despite significant progress of applying deep learning methods to the field of content-based image retrieval, there has not been a software library that covers these methods in a unified manner. In order to fill this gap, we introduce PyRetri, an open source library for deep learning based unsupervised image retrieval. The library encapsulates the retrieval process in several stages and provides functionality that covers various prominent methods for each stage. The idea underlying its design is to provide a unified platform for deep learning based image retrieval research, with high usability and extensibility. To the best of our knowledge, this is the first open-source library for unsupervised image retrieval by deep learning.
CPR-GCN: Conditional Partial-Residual Graph Convolutional Network in Automated Anatomical Labeling of Coronary Arteries
Apr 18, 2020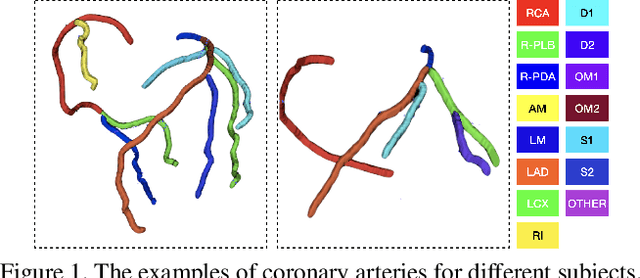
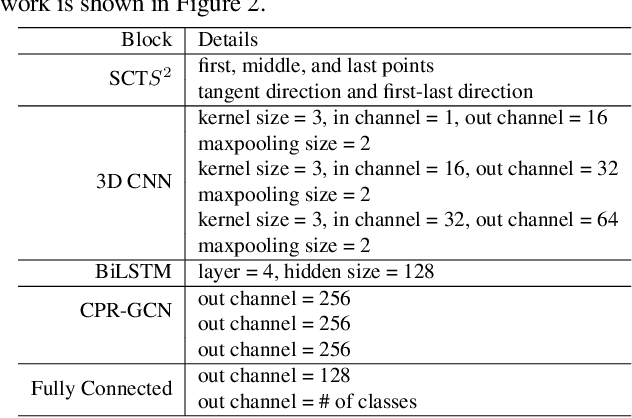
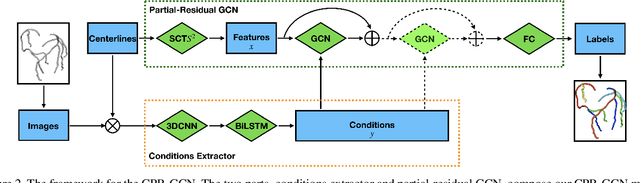
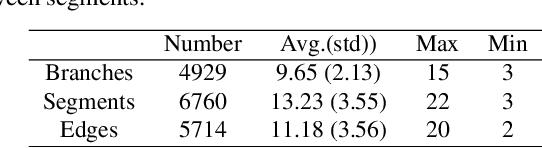
Automated anatomical labeling plays a vital role in coronary artery disease diagnosing procedure. The main challenge in this problem is the large individual variability inherited in human anatomy. Existing methods usually rely on the position information and the prior knowledge of the topology of the coronary artery tree, which may lead to unsatisfactory performance when the main branches are confusing. Motivated by the wide application of the graph neural network in structured data, in this paper, we propose a conditional partial-residual graph convolutional network (CPR-GCN), which takes both position and CT image into consideration, since CT image contains abundant information such as branch size and spanning direction. Two majority parts, a Partial-Residual GCN and a conditions extractor, are included in CPR-GCN. The conditions extractor is a hybrid model containing the 3D CNN and the LSTM, which can extract 3D spatial image features along the branches. On the technical side, the Partial-Residual GCN takes the position features of the branches, with the 3D spatial image features as conditions, to predict the label for each branches. While on the mathematical side, our approach twists the partial differential equation (PDE) into the graph modeling. A dataset with 511 subjects is collected from the clinic and annotated by two experts with a two-phase annotation process. According to the five-fold cross-validation, our CPR-GCN yields 95.8% meanRecall, 95.4% meanPrecision and 0.955 meanF1, which outperforms state-of-the-art approaches.
* This work is done by Xingjian Zhen during internship in Alibaba Damo Academy
Towards Precise Intra-camera Supervised Person Re-identification
Feb 12, 2020

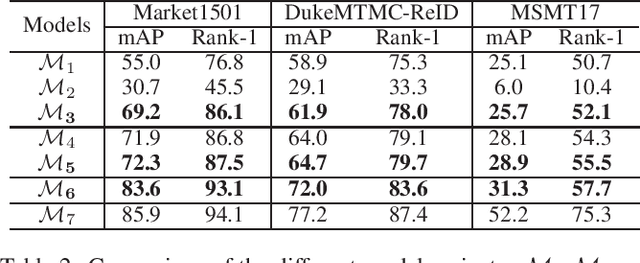
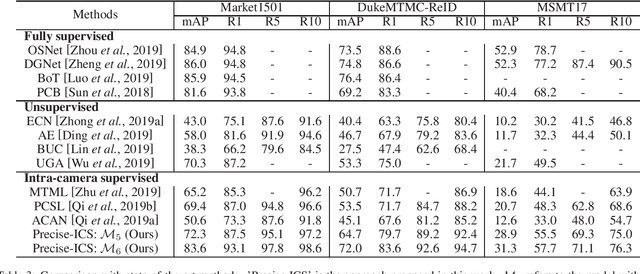
Intra-camera supervision (ICS) for person re-identification (Re-ID) assumes that identity labels are independently annotated within each camera view and no inter-camera identity association is labeled. It is a new setting proposed recently to reduce the burden of annotation while expect to maintain desirable Re-ID performance. However, the lack of inter-camera labels makes the ICS Re-ID problem much more challenging than the fully supervised counterpart. By investigating the characteristics of ICS, this paper proposes camera-specific non-parametric classifiers, together with a hybrid mining quintuplet loss, to perform intra-camera learning. Then, an inter-camera learning module consisting of a graph-based ID association step and a Re-ID model updating step is conducted. Extensive experiments on three large-scale Re-ID datasets show that our approach outperforms all existing ICS works by a great margin. Our approach performs even comparable to state-of-the-art fully supervised methods in two of the datasets.
Towards a Fast Steady-State Visual Evoked Potentials Brain-Computer Interface
Feb 04, 2020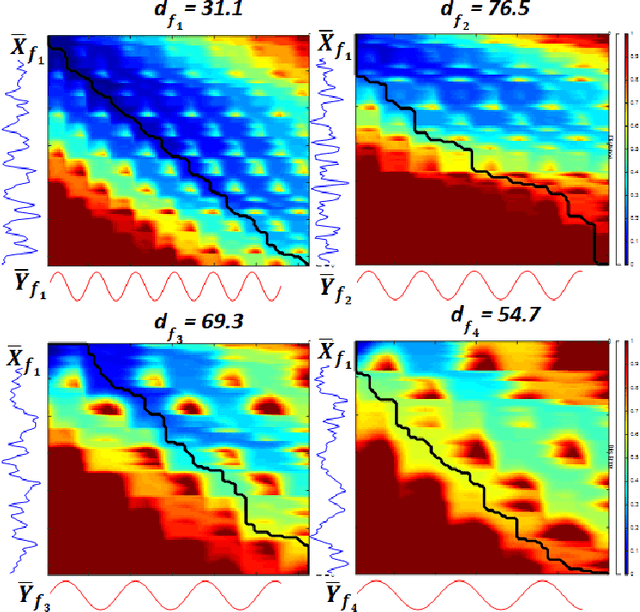
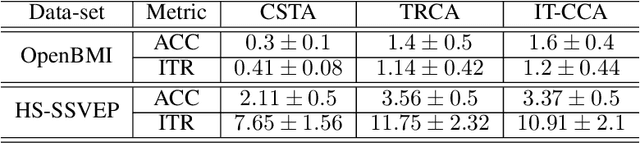
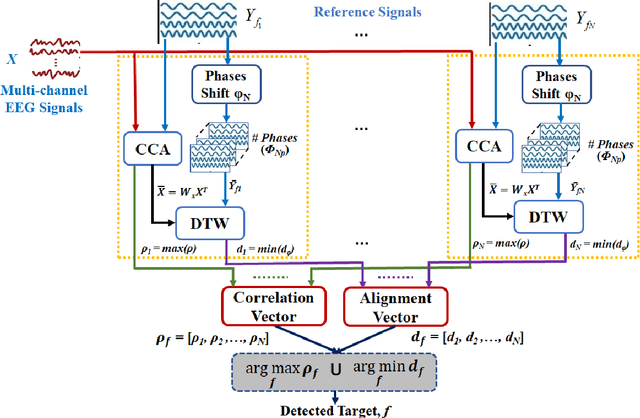
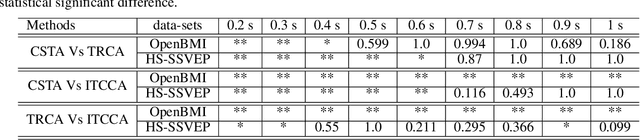
Steady-state visual evoked potentials (SSVEP) brain-computer interface (BCI) provides reliable responses leading to high accuracy and information throughput. But achieving high accuracy typically requires a relatively long time window of one second or more. Various methods were proposed to improve sub-second response accuracy through subject-specific training and calibration. Substantial performance improvements were achieved with tedious calibration and subject-specific training; resulting in the user's discomfort. So, we propose a training-free method by combining spatial-filtering and temporal alignment (CSTA) to recognize SSVEP responses in sub-second response time. CSTA exploits linear correlation and non-linear similarity between steady-state responses and stimulus templates with complementary fusion to achieve desirable performance improvements. We evaluated the performance of CSTA in terms of accuracy and Information Transfer Rate (ITR) in comparison with both training-based and training-free methods using two SSVEP data-sets. We observed that CSTA achieves the maximum mean accuracy of 97.43$\pm$2.26 % and 85.71$\pm$13.41 % with four-class and forty-class SSVEP data-sets respectively in sub-second response time in offline analysis. CSTA yields significantly higher mean performance (p<0.001) than the training-free method on both data-sets. Compared with training-based methods, CSTA shows 29.33$\pm$19.65 % higher mean accuracy with statistically significant differences in time window less than 0.5 s. In longer time windows, CSTA exhibits either better or comparable performance though not statistically significantly better than training-based methods. We show that the proposed method brings advantages of subject-independent SSVEP classification without requiring training while enabling high target recognition performance in sub-second response time.
HoMM: Higher-order Moment Matching for Unsupervised Domain Adaptation
Dec 27, 2019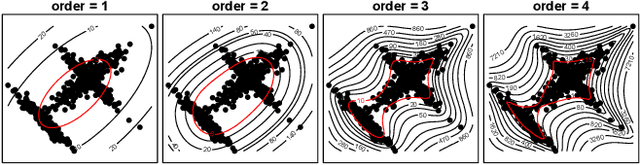
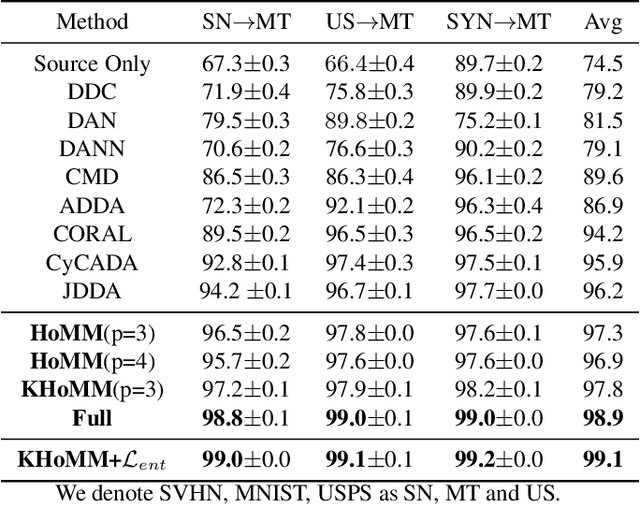
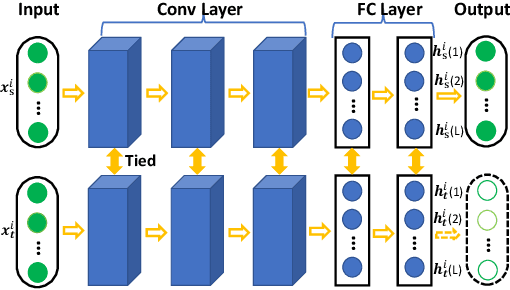
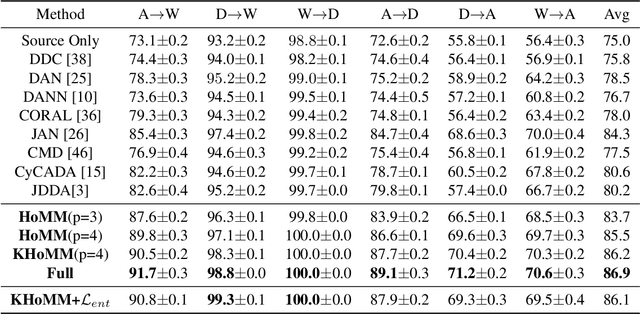
Minimizing the discrepancy of feature distributions between different domains is one of the most promising directions in unsupervised domain adaptation. From the perspective of distribution matching, most existing discrepancy-based methods are designed to match the second-order or lower statistics, which however, have limited expression of statistical characteristic for non-Gaussian distributions. In this work, we explore the benefits of using higher-order statistics (mainly refer to third-order and fourth-order statistics) for domain matching. We propose a Higher-order Moment Matching (HoMM) method, and further extend the HoMM into reproducing kernel Hilbert spaces (RKHS). In particular, our proposed HoMM can perform arbitrary-order moment tensor matching, we show that the first-order HoMM is equivalent to Maximum Mean Discrepancy (MMD) and the second-order HoMM is equivalent to Correlation Alignment (CORAL). Moreover, the third-order and the fourth-order moment tensor matching are expected to perform comprehensive domain alignment as higher-order statistics can approximate more complex, non-Gaussian distributions. Besides, we also exploit the pseudo-labeled target samples to learn discriminative representations in the target domain, which further improves the transfer performance. Extensive experiments are conducted, showing that our proposed HoMM consistently outperforms the existing moment matching methods by a large margin. Codes are available at \url{https://github.com/chenchao666/HoMM-Master}
Progressive Transfer Learning for Person Re-identification
Aug 08, 2019
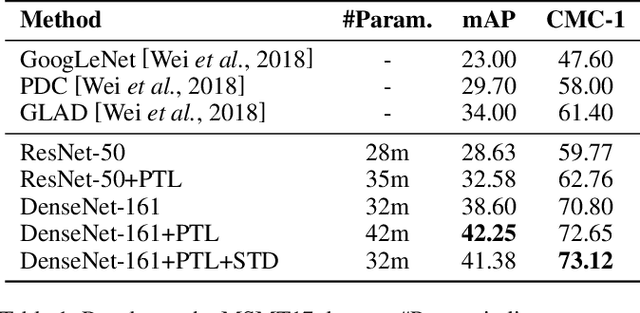
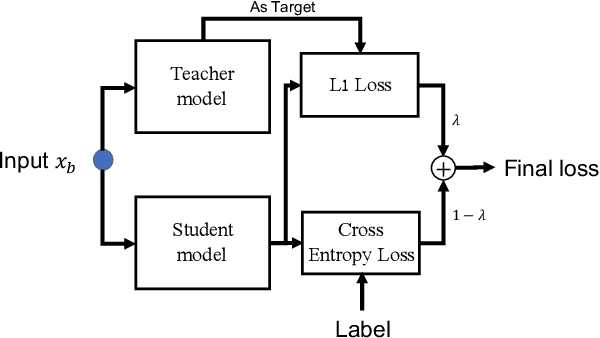
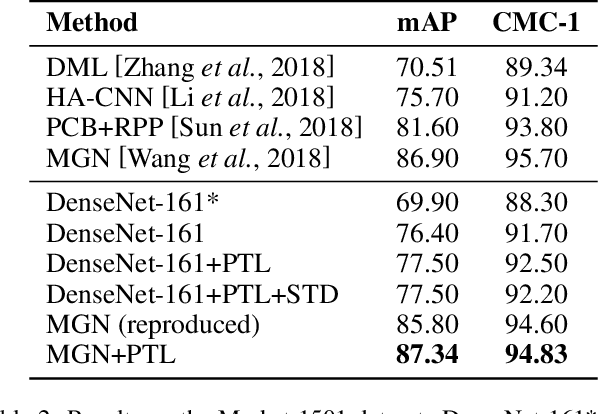
Model fine-tuning is a widely used transfer learning approach in person Re-identification (ReID) applications, which fine-tuning a pre-trained feature extraction model into the target scenario instead of training a model from scratch. It is challenging due to the significant variations inside the target scenario, e.g., different camera viewpoint, illumination changes, and occlusion. These variations result in a gap between the distribution of each mini-batch and the distribution of the whole dataset when using mini-batch training. In this paper, we study model fine-tuning from the perspective of the aggregation and utilization of the global information of the dataset when using mini-batch training. Specifically, we introduce a novel network structure called Batch-related Convolutional Cell (BConv-Cell), which progressively collects the global information of the dataset into a latent state and uses this latent state to rectify the extracted feature. Based on BConv-Cells, we further proposed the Progressive Transfer Learning (PTL) method to facilitate the model fine-tuning process by joint training the BConv-Cells and the pre-trained ReID model. Empirical experiments show that our proposal can improve the performance of the ReID model greatly on MSMT17, Market-1501, CUHK03 and DukeMTMC-reID datasets. The code will be released later on at \url{https://github.com/ZJULearning/PTL}
Towards Self-similarity Consistency and Feature Discrimination for Unsupervised Domain Adaptation
Apr 13, 2019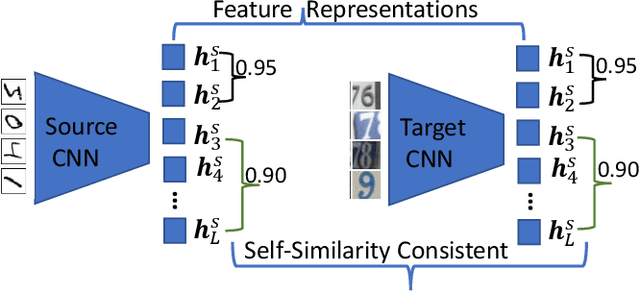
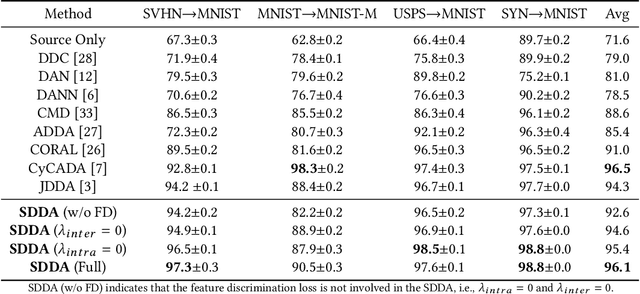
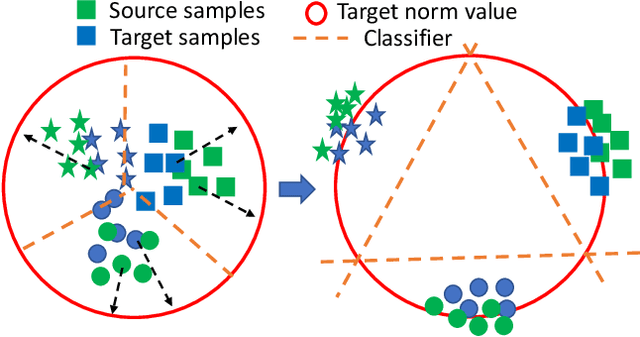
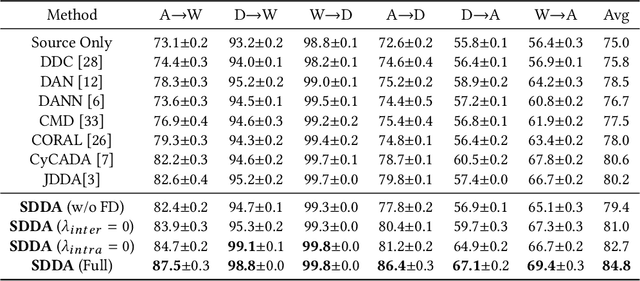
Recent advances in unsupervised domain adaptation mainly focus on learning shared representations by global distribution alignment without considering class information across domains. The neglect of class information, however, may lead to partial alignment (or even misalignment) and poor generalization performance. For comprehensive alignment, we argue that the similarities across different features in the source domain should be consistent with that of in the target domain. Based on this assumption, we propose a new domain discrepancy metric, i.e., Self-similarity Consistency (SSC), to enforce the feature structure being consistent across domains. The renowned correlation alignment (CORAL) is proven to be a special case, and a sub-optimal measure of our proposed SSC. Furthermore, we also propose to mitigate the side effect of the partial alignment and misalignment by incorporating the discriminative information of the deep representations. Specifically, an embarrassingly simple and effective feature norm constraint is exploited to enlarge the discrepancy of inter-class samples. It relieves the requirements of strict alignment when performing adaptation, therefore improving the adaptation performance significantly. Extensive experiments on visual domain adaptation tasks demonstrate the effectiveness of our proposed SSC metric and feature discrimination approach.
Sharp Attention Network via Adaptive Sampling for Person Re-identification
Sep 26, 2018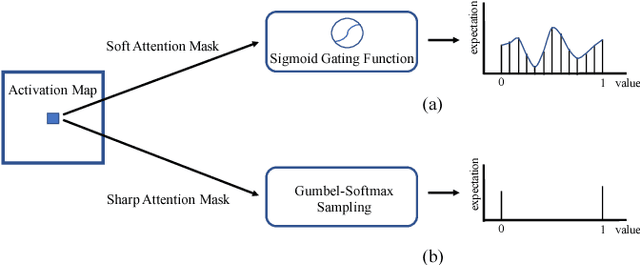
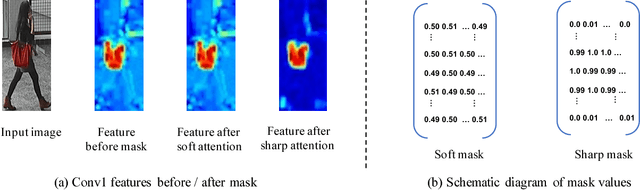
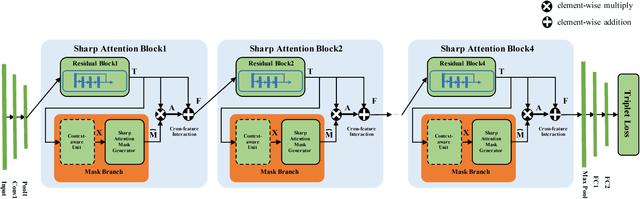
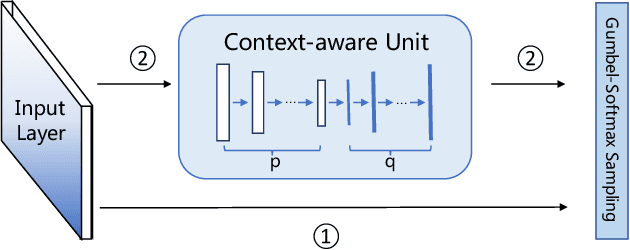
In this paper, we present novel sharp attention networks by adaptively sampling feature maps from convolutional neural networks (CNNs) for person re-identification (re-ID) problem. Due to the introduction of sampling-based attention models, the proposed approach can adaptively generate sharper attention-aware feature masks. This greatly differs from the gating-based attention mechanism that relies soft gating functions to select the relevant features for person re-ID. In contrast, the proposed sampling-based attention mechanism allows us to effectively trim irrelevant features by enforcing the resultant feature masks to focus on the most discriminative features. It can produce sharper attentions that are more assertive in localizing subtle features relevant to re-identifying people across cameras. For this purpose, a differentiable Gumbel-Softmax sampler is employed to approximate the Bernoulli sampling to train the sharp attention networks. Extensive experimental evaluations demonstrate the superiority of this new sharp attention model for person re-ID over the other state-of-the-art methods on three challenging benchmarks including CUHK03, Market-1501, and DukeMTMC-reID.
Video2Shop: Exactly Matching Clothes in Videos to Online Shopping Images
Apr 14, 2018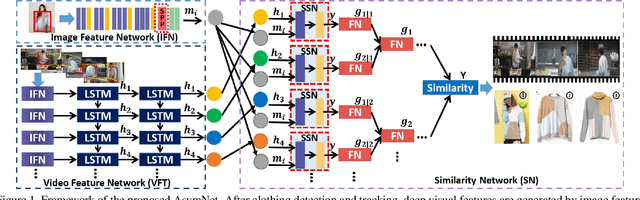
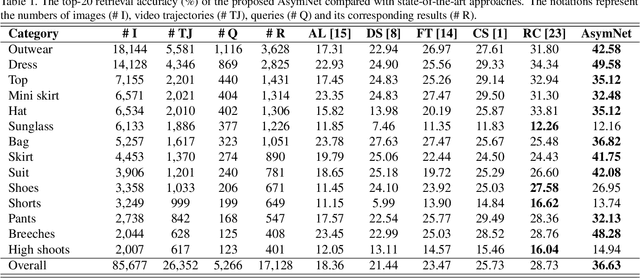
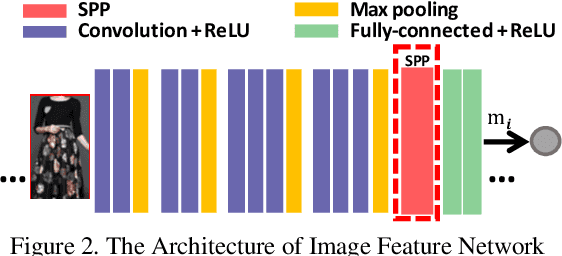
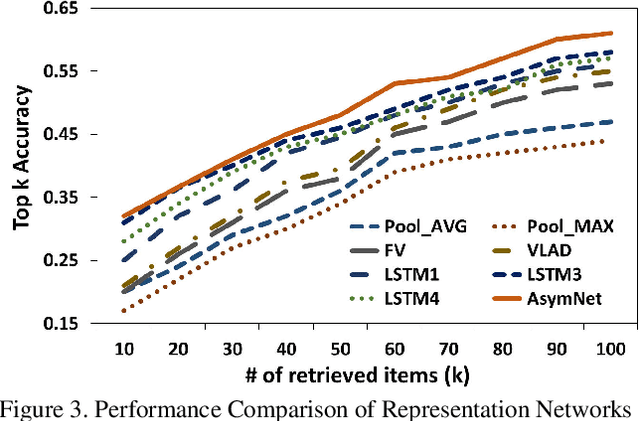
In recent years, both online retail and video hosting service are exponentially growing. In this paper, we explore a new cross-domain task, Video2Shop, targeting for matching clothes appeared in videos to the exact same items in online shops. A novel deep neural network, called AsymNet, is proposed to explore this problem. For the image side, well- established methods are used to detect and extract features for clothing patches with arbitrary sizes. For the video side, deep visual features are extracted from detected object re- gions in each frame, and further fed into a Long Short-Term Memory (LSTM) framework for sequence modeling, which captures the temporal dynamics in videos. To conduct exact matching between videos and online shopping images, LSTM hidden states, representing the video, and image features, which represent static object images, are jointly mod- eled under the similarity network with reconfigurable deep tree structure. Moreover, an approximate training method is proposed to achieve the efficiency when training. Extensive experiments conducted on a large cross-domain dataset have demonstrated the effectiveness and efficiency of the proposed AsymNet, which outperforms the state-of-the-art methods.