 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHomography Loss for Monocular 3D Object Detection
Apr 02, 2022
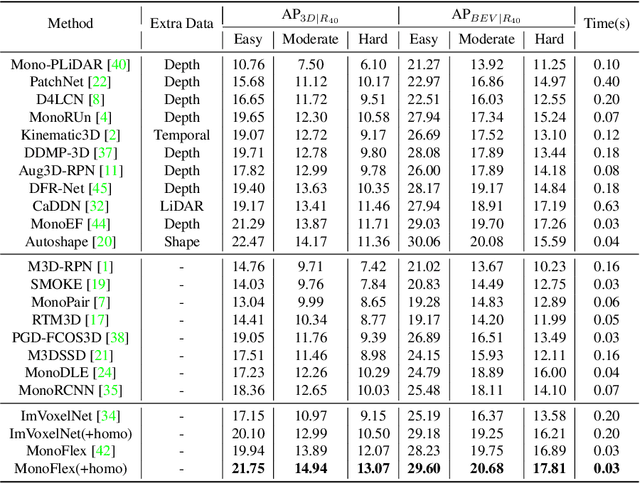
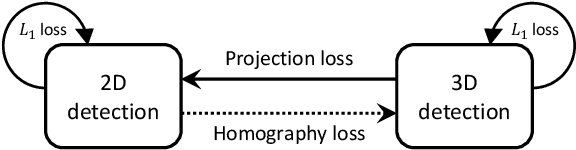
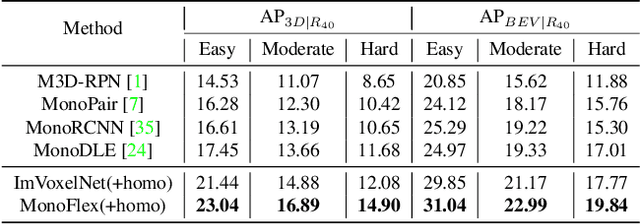
Monocular 3D object detection is an essential task in autonomous driving. However, most current methods consider each 3D object in the scene as an independent training sample, while ignoring their inherent geometric relations, thus inevitably resulting in a lack of leveraging spatial constraints. In this paper, we propose a novel method that takes all the objects into consideration and explores their mutual relationships to help better estimate the 3D boxes. Moreover, since 2D detection is more reliable currently, we also investigate how to use the detected 2D boxes as guidance to globally constrain the optimization of the corresponding predicted 3D boxes. To this end, a differentiable loss function, termed as Homography Loss, is proposed to achieve the goal, which exploits both 2D and 3D information, aiming at balancing the positional relationships between different objects by global constraints, so as to obtain more accurately predicted 3D boxes. Thanks to the concise design, our loss function is universal and can be plugged into any mature monocular 3D detector, while significantly boosting the performance over their baseline. Experiments demonstrate that our method yields the best performance (Nov. 2021) compared with the other state-of-the-arts by a large margin on KITTI 3D datasets.
Disentangled Representation Learning for Text-Video Retrieval
Mar 14, 2022

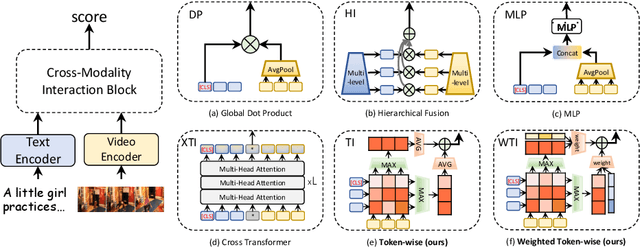
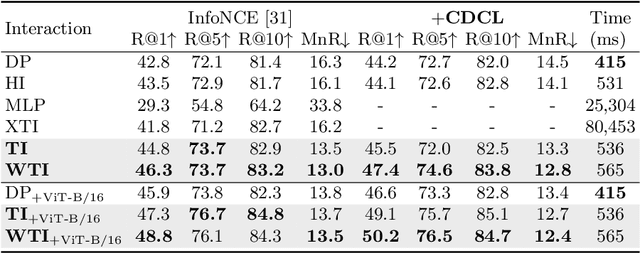
Cross-modality interaction is a critical component in Text-Video Retrieval (TVR), yet there has been little examination of how different influencing factors for computing interaction affect performance. This paper first studies the interaction paradigm in depth, where we find that its computation can be split into two terms, the interaction contents at different granularity and the matching function to distinguish pairs with the same semantics. We also observe that the single-vector representation and implicit intensive function substantially hinder the optimization. Based on these findings, we propose a disentangled framework to capture a sequential and hierarchical representation. Firstly, considering the natural sequential structure in both text and video inputs, a Weighted Token-wise Interaction (WTI) module is performed to decouple the content and adaptively exploit the pair-wise correlations. This interaction can form a better disentangled manifold for sequential inputs. Secondly, we introduce a Channel DeCorrelation Regularization (CDCR) to minimize the redundancy between the components of the compared vectors, which facilitate learning a hierarchical representation. We demonstrate the effectiveness of the disentangled representation on various benchmarks, e.g., surpassing CLIP4Clip largely by +2.9%, +3.1%, +7.9%, +2.3%, +2.8% and +6.5% R@1 on the MSR-VTT, MSVD, VATEX, LSMDC, AcitivityNet, and DiDeMo, respectively.
Class Re-Activation Maps for Weakly-Supervised Semantic Segmentation
Mar 02, 2022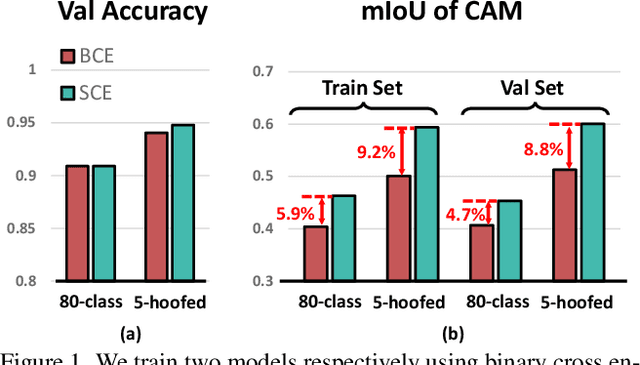
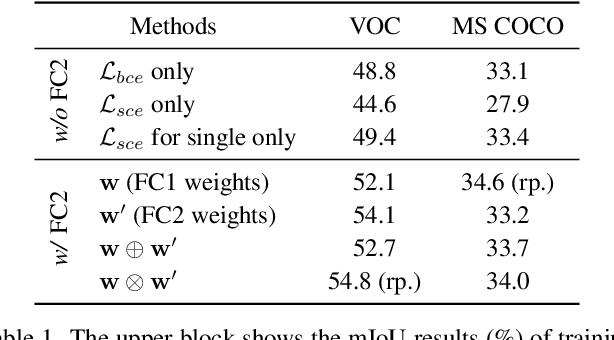
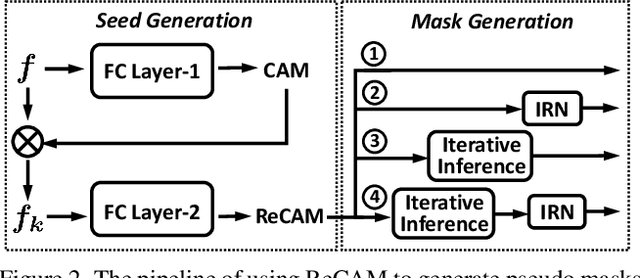
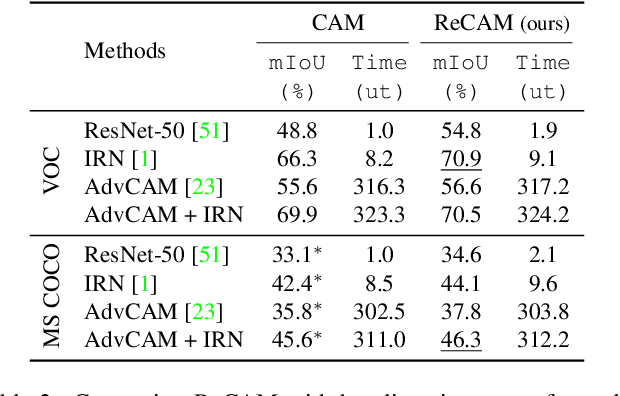
Extracting class activation maps (CAM) is arguably the most standard step of generating pseudo masks for weakly-supervised semantic segmentation (WSSS). Yet, we find that the crux of the unsatisfactory pseudo masks is the binary cross-entropy loss (BCE) widely used in CAM. Specifically, due to the sum-over-class pooling nature of BCE, each pixel in CAM may be responsive to multiple classes co-occurring in the same receptive field. As a result, given a class, its hot CAM pixels may wrongly invade the area belonging to other classes, or the non-hot ones may be actually a part of the class. To this end, we introduce an embarrassingly simple yet surprisingly effective method: Reactivating the converged CAM with BCE by using softmax cross-entropy loss (SCE), dubbed \textbf{ReCAM}. Given an image, we use CAM to extract the feature pixels of each single class, and use them with the class label to learn another fully-connected layer (after the backbone) with SCE. Once converged, we extract ReCAM in the same way as in CAM. Thanks to the contrastive nature of SCE, the pixel response is disentangled into different classes and hence less mask ambiguity is expected. The evaluation on both PASCAL VOC and MS~COCO shows that ReCAM not only generates high-quality masks, but also supports plug-and-play in any CAM variant with little overhead.
Offline-Online Associated Camera-Aware Proxies for Unsupervised Person Re-identification
Jan 15, 2022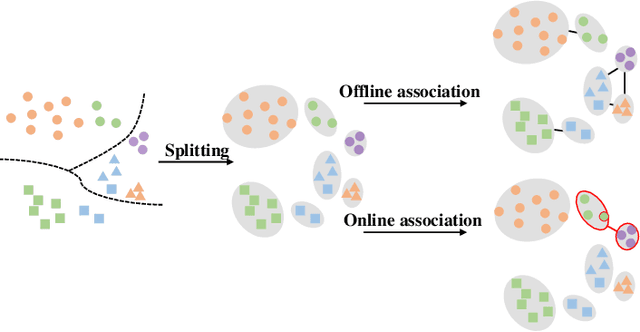


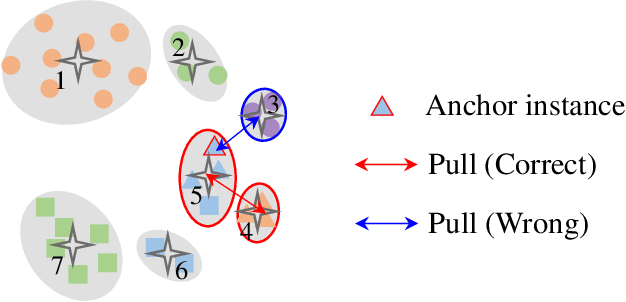
Recently, unsupervised person re-identification (Re-ID) has received increasing research attention due to its potential for label-free applications. A promising way to address unsupervised Re-ID is clustering-based, which generates pseudo labels by clustering and uses the pseudo labels to train a Re-ID model iteratively. However, most clustering-based methods take each cluster as a pseudo identity class, neglecting the intra-cluster variance mainly caused by the change of cameras. To address this issue, we propose to split each single cluster into multiple proxies according to camera views. The camera-aware proxies explicitly capture local structures within clusters, by which the intra-ID variance and inter-ID similarity can be better tackled. Assisted with the camera-aware proxies, we design two proxy-level contrastive learning losses that are, respectively, based on offline and online association results. The offline association directly associates proxies according to the clustering and splitting results, while the online strategy dynamically associates proxies in terms of up-to-date features to reduce the noise caused by the delayed update of pseudo labels. The combination of two losses enable us to train a desirable Re-ID model. Extensive experiments on three person Re-ID datasets and one vehicle Re-ID dataset show that our proposed approach demonstrates competitive performance with state-of-the-art methods. Code will be available at: https://github.com/Terminator8758/O2CAP.
Cross-Domain Empirical Risk Minimization for Unbiased Long-tailed Classification
Dec 29, 2021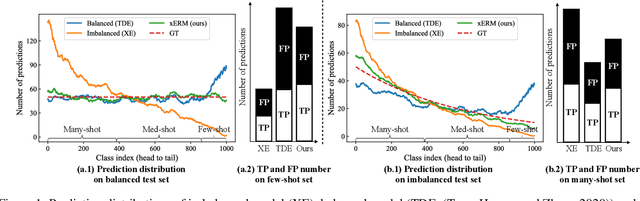
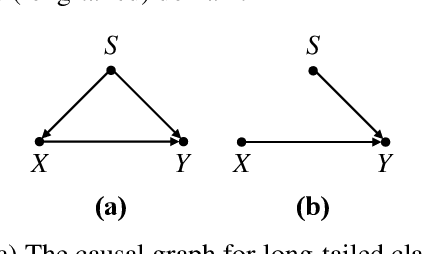
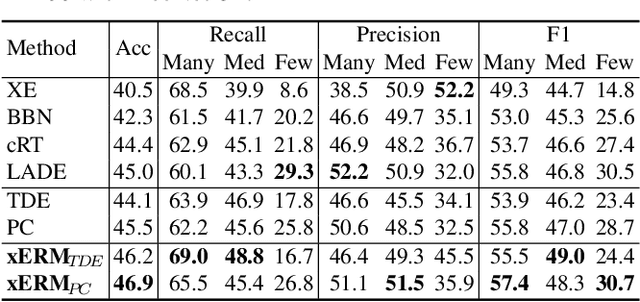
We address the overlooked unbiasedness in existing long-tailed classification methods: we find that their overall improvement is mostly attributed to the biased preference of tail over head, as the test distribution is assumed to be balanced; however, when the test is as imbalanced as the long-tailed training data -- let the test respect Zipf's law of nature -- the tail bias is no longer beneficial overall because it hurts the head majorities. In this paper, we propose Cross-Domain Empirical Risk Minimization (xERM) for training an unbiased model to achieve strong performances on both test distributions, which empirically demonstrates that xERM fundamentally improves the classification by learning better feature representation rather than the head vs. tail game. Based on causality, we further theoretically explain why xERM achieves unbiasedness: the bias caused by the domain selection is removed by adjusting the empirical risks on the imbalanced domain and the balanced but unseen domain. Codes are available at https://github.com/BeierZhu/xERM.
Meta Clustering Learning for Large-scale Unsupervised Person Re-identification
Nov 19, 2021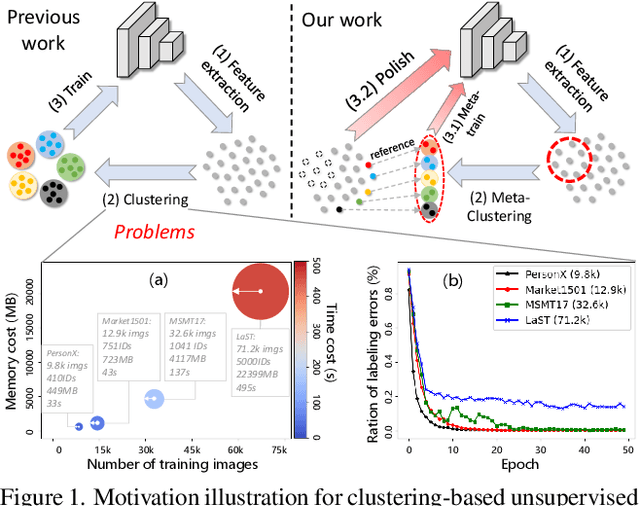
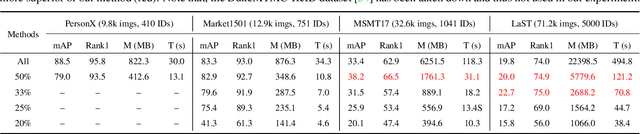
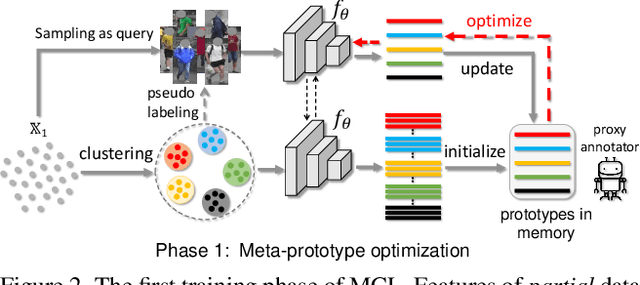
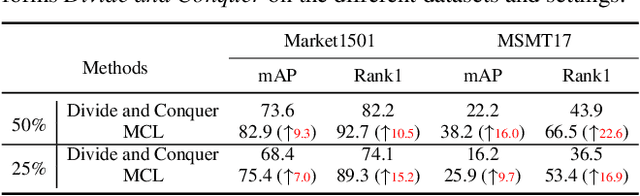
Unsupervised Person Re-identification (U-ReID) with pseudo labeling recently reaches a competitive performance compared to fully-supervised ReID methods based on modern clustering algorithms. However, such clustering-based scheme becomes computationally prohibitive for large-scale datasets. How to efficiently leverage endless unlabeled data with limited computing resources for better U-ReID is under-explored. In this paper, we make the first attempt to the large-scale U-ReID and propose a "small data for big task" paradigm dubbed Meta Clustering Learning (MCL). MCL only pseudo-labels a subset of the entire unlabeled data via clustering to save computing for the first-phase training. After that, the learned cluster centroids, termed as meta-prototypes in our MCL, are regarded as a proxy annotator to softly annotate the rest unlabeled data for further polishing the model. To alleviate the potential noisy labeling issue in the polishment phase, we enforce two well-designed loss constraints to promise intra-identity consistency and inter-identity strong correlation. For multiple widely-used U-ReID benchmarks, our method significantly saves computational cost while achieving a comparable or even better performance compared to prior works.
SpineOne: A One-Stage Detection Framework for Degenerative Discs and Vertebrae
Nov 10, 2021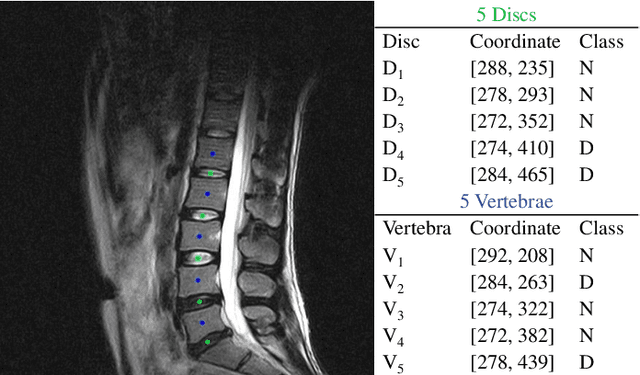
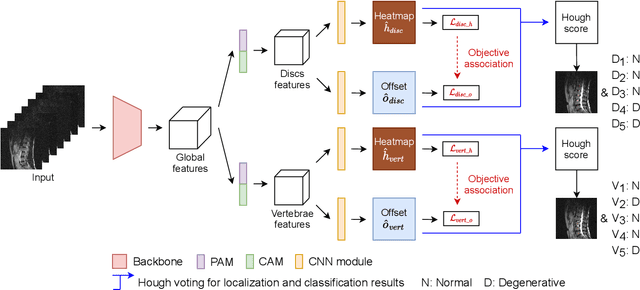
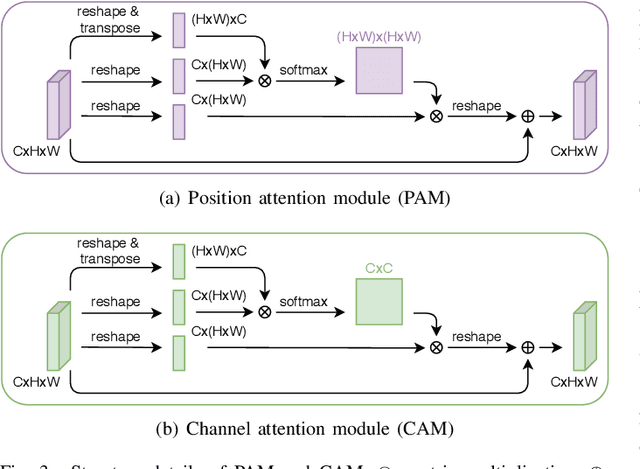
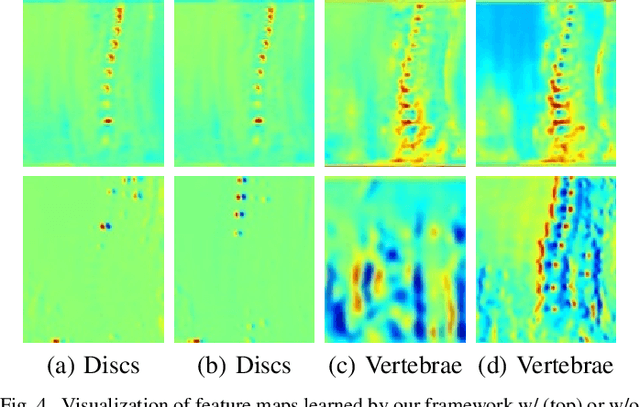
Spinal degeneration plagues many elders, office workers, and even the younger generations. Effective pharmic or surgical interventions can help relieve degenerative spine conditions. However, the traditional diagnosis procedure is often too laborious. Clinical experts need to detect discs and vertebrae from spinal magnetic resonance imaging (MRI) or computed tomography (CT) images as a preliminary step to perform pathological diagnosis or preoperative evaluation. Machine learning systems have been developed to aid this procedure generally following a two-stage methodology: first perform anatomical localization, then pathological classification. Towards more efficient and accurate diagnosis, we propose a one-stage detection framework termed SpineOne to simultaneously localize and classify degenerative discs and vertebrae from MRI slices. SpineOne is built upon the following three key techniques: 1) a new design of the keypoint heatmap to facilitate simultaneous keypoint localization and classification; 2) the use of attention modules to better differentiate the representations between discs and vertebrae; and 3) a novel gradient-guided objective association mechanism to associate multiple learning objectives at the later training stage. Empirical results on the Spinal Disease Intelligent Diagnosis Tianchi Competition (SDID-TC) dataset of 550 exams demonstrate that our approach surpasses existing methods by a large margin.
Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression
Oct 26, 2021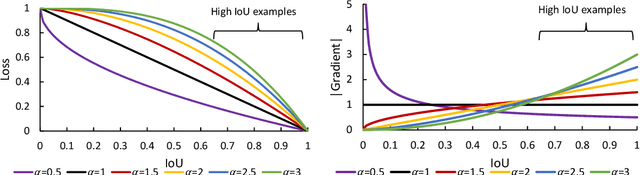
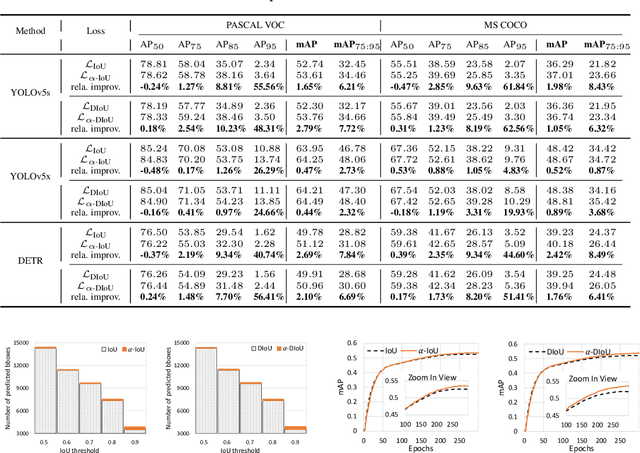
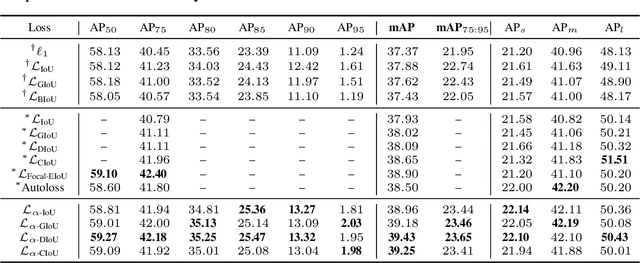
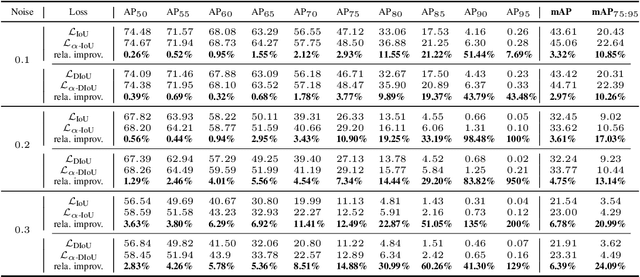
Bounding box (bbox) regression is a fundamental task in computer vision. So far, the most commonly used loss functions for bbox regression are the Intersection over Union (IoU) loss and its variants. In this paper, we generalize existing IoU-based losses to a new family of power IoU losses that have a power IoU term and an additional power regularization term with a single power parameter $\alpha$. We call this new family of losses the $\alpha$-IoU losses and analyze properties such as order preservingness and loss/gradient reweighting. Experiments on multiple object detection benchmarks and models demonstrate that $\alpha$-IoU losses, 1) can surpass existing IoU-based losses by a noticeable performance margin; 2) offer detectors more flexibility in achieving different levels of bbox regression accuracy by modulating $\alpha$; and 3) are more robust to small datasets and noisy bboxes.
Density-Based Clustering with Kernel Diffusion
Oct 14, 2021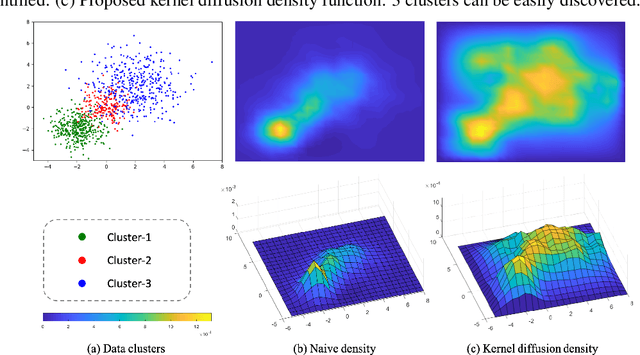
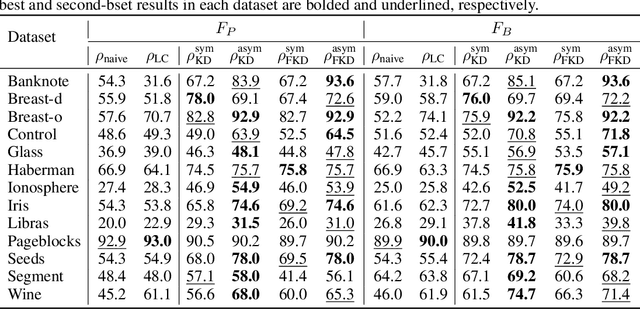
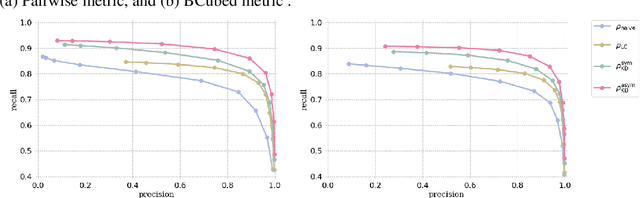
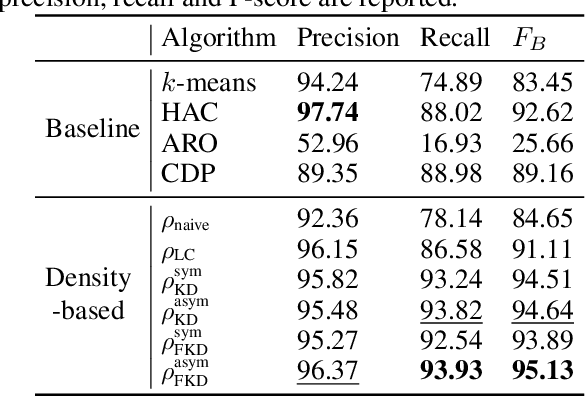
Finding a suitable density function is essential for density-based clustering algorithms such as DBSCAN and DPC. A naive density corresponding to the indicator function of a unit $d$-dimensional Euclidean ball is commonly used in these algorithms. Such density suffers from capturing local features in complex datasets. To tackle this issue, we propose a new kernel diffusion density function, which is adaptive to data of varying local distributional characteristics and smoothness. Furthermore, we develop a surrogate that can be efficiently computed in linear time and space and prove that it is asymptotically equivalent to the kernel diffusion density function. Extensive empirical experiments on benchmark and large-scale face image datasets show that the proposed approach not only achieves a significant improvement over classic density-based clustering algorithms but also outperforms the state-of-the-art face clustering methods by a large margin.
Improving 3D Object Detection with Channel-wise Transformer
Aug 23, 2021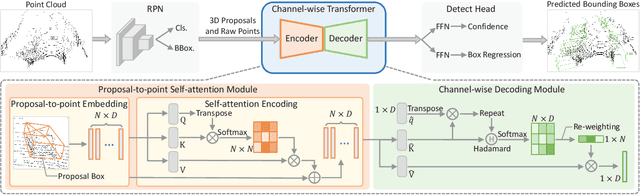
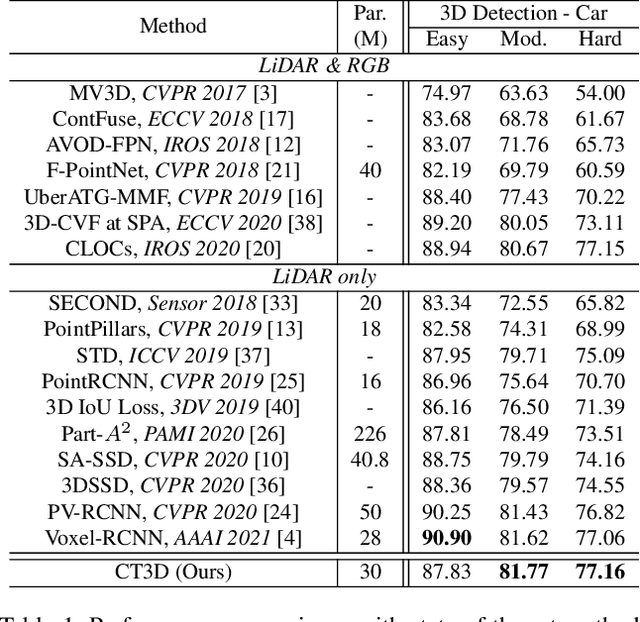
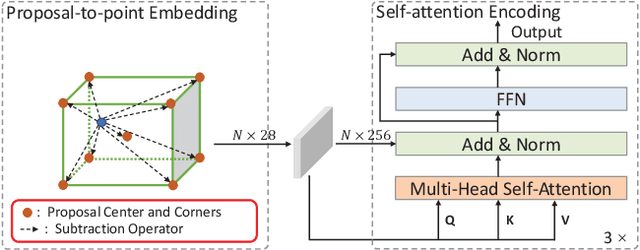
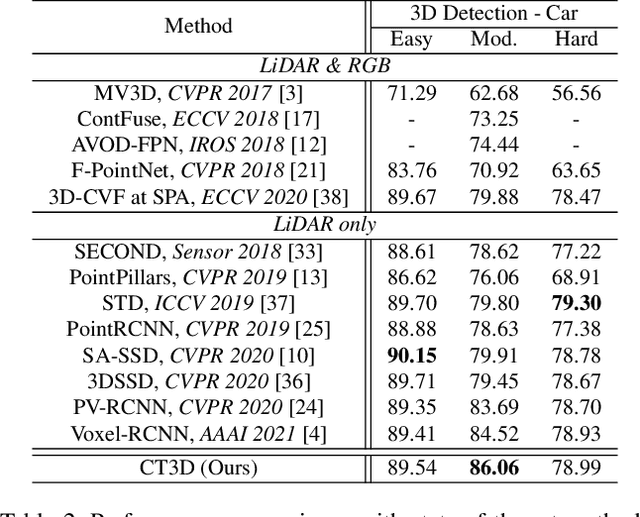
Though 3D object detection from point clouds has achieved rapid progress in recent years, the lack of flexible and high-performance proposal refinement remains a great hurdle for existing state-of-the-art two-stage detectors. Previous works on refining 3D proposals have relied on human-designed components such as keypoints sampling, set abstraction and multi-scale feature fusion to produce powerful 3D object representations. Such methods, however, have limited ability to capture rich contextual dependencies among points. In this paper, we leverage the high-quality region proposal network and a Channel-wise Transformer architecture to constitute our two-stage 3D object detection framework (CT3D) with minimal hand-crafted design. The proposed CT3D simultaneously performs proposal-aware embedding and channel-wise context aggregation for the point features within each proposal. Specifically, CT3D uses proposal's keypoints for spatial contextual modelling and learns attention propagation in the encoding module, mapping the proposal to point embeddings. Next, a new channel-wise decoding module enriches the query-key interaction via channel-wise re-weighting to effectively merge multi-level contexts, which contributes to more accurate object predictions. Extensive experiments demonstrate that our CT3D method has superior performance and excellent scalability. Remarkably, CT3D achieves the AP of 81.77% in the moderate car category on the KITTI test 3D detection benchmark, outperforms state-of-the-art 3D detectors.