 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human Mesh Estimation from Virtual Markers
Mar 27, 2023Inspired by the success of volumetric 3D pose estimation, some recent human mesh estimators propose to estimate 3D skeletons as intermediate representations, from which, the dense 3D meshes are regressed by exploiting the mesh topology. However, body shape information is lost in extracting skeletons, leading to mediocre performance. The advanced motion capture systems solve the problem by placing dense physical markers on the body surface, which allows to extract realistic meshes from their non-rigid motions. However, they cannot be applied to wild images without markers. In this work, we present an intermediate representation, named virtual markers, which learns 64 landmark keypoints on the body surface based on the large-scale mocap data in a generative style, mimicking the effects of physical markers. The virtual markers can be accurately detected from wild images and can reconstruct the intact meshes with realistic shapes by simple interpolation. Our approach outperforms the state-of-the-art methods on three datasets. In particular, it surpasses the existing methods by a notable margin on the SURREAL dataset, which has diverse body shapes. Code is available at https://github.com/ShirleyMaxx/VirtualMarker.
Selective Structured State-Spaces for Long-Form Video Understanding
Mar 25, 2023



Effective modeling of complex spatiotemporal dependencies in long-form videos remains an open problem. The recently proposed Structured State-Space Sequence (S4) model with its linear complexity offers a promising direction in this space. However, we demonstrate that treating all image-tokens equally as done by S4 model can adversely affect its efficiency and accuracy. To address this limitation, we present a novel Selective S4 (i.e., S5) model that employs a lightweight mask generator to adaptively select informative image tokens resulting in more efficient and accurate modeling of long-term spatiotemporal dependencies in videos. Unlike previous mask-based token reduction methods used in transformers, our S5 model avoids the dense self-attention calculation by making use of the guidance of the momentum-updated S4 model. This enables our model to efficiently discard less informative tokens and adapt to various long-form video understanding tasks more effectively. However, as is the case for most token reduction methods, the informative image tokens could be dropped incorrectly. To improve the robustness and the temporal horizon of our model, we propose a novel long-short masked contrastive learning (LSMCL) approach that enables our model to predict longer temporal context using shorter input videos. We present extensive comparative results using three challenging long-form video understanding datasets (LVU, COIN and Breakfast), demonstrating that our approach consistently outperforms the previous state-of-the-art S4 model by up to 9.6% accuracy while reducing its memory footprint by 23%.
Multiscale Audio Spectrogram Transformer for Efficient Audio Classification
Mar 19, 2023Audio event has a hierarchical architecture in both time and frequency and can be grouped together to construct more abstract semantic audio classes. In this work, we develop a multiscale audio spectrogram Transformer (MAST) that employs hierarchical representation learning for efficient audio classification. Specifically, MAST employs one-dimensional (and two-dimensional) pooling operators along the time (and frequency domains) in different stages, and progressively reduces the number of tokens and increases the feature dimensions. MAST significantly outperforms AST~\cite{gong2021ast} by 22.2\%, 4.4\% and 4.7\% on Kinetics-Sounds, Epic-Kitchens-100 and VGGSound in terms of the top-1 accuracy without external training data. On the downloaded AudioSet dataset, which has over 20\% missing audios, MAST also achieves slightly better accuracy than AST. In addition, MAST is 5x more efficient in terms of multiply-accumulates (MACs) with 42\% reduction in the number of parameters compared to AST. Through clustering metrics and visualizations, we demonstrate that the proposed MAST can learn semantically more separable feature representations from audio signals.
GFPose: Learning 3D Human Pose Prior with Gradient Fields
Dec 16, 2022Learning 3D human pose prior is essential to human-centered AI. Here, we present GFPose, a versatile framework to model plausible 3D human poses for various applications. At the core of GFPose is a time-dependent score network, which estimates the gradient on each body joint and progressively denoises the perturbed 3D human pose to match a given task specification. During the denoising process, GFPose implicitly incorporates pose priors in gradients and unifies various discriminative and generative tasks in an elegant framework. Despite the simplicity, GFPose demonstrates great potential in several downstream tasks. Our experiments empirically show that 1) as a multi-hypothesis pose estimator, GFPose outperforms existing SOTAs by 20% on Human3.6M dataset. 2) as a single-hypothesis pose estimator, GFPose achieves comparable results to deterministic SOTAs, even with a vanilla backbone. 3) GFPose is able to produce diverse and realistic samples in pose denoising, completion and generation tasks. Project page https://sites.google.com/view/gfpose/
Intelligent Computing: The Latest Advances, Challenges and Future
Nov 21, 2022Computing is a critical driving force in the development of human civilization. In recent years, we have witnessed the emergence of intelligent computing, a new computing paradigm that is reshaping traditional computing and promoting digital revolution in the era of big data, artificial intelligence and internet-of-things with new computing theories, architectures, methods, systems, and applications. Intelligent computing has greatly broadened the scope of computing, extending it from traditional computing on data to increasingly diverse computing paradigms such as perceptual intelligence, cognitive intelligence, autonomous intelligence, and human-computer fusion intelligence. Intelligence and computing have undergone paths of different evolution and development for a long time but have become increasingly intertwined in recent years: intelligent computing is not only intelligence-oriented but also intelligence-driven. Such cross-fertilization has prompted the emergence and rapid advancement of intelligent computing. Intelligent computing is still in its infancy and an abundance of innovations in the theories, systems, and applications of intelligent computing are expected to occur soon. We present the first comprehensive survey of literature on intelligent computing, covering its theory fundamentals, the technological fusion of intelligence and computing, important applications, challenges, and future perspectives. We believe that this survey is highly timely and will provide a comprehensive reference and cast valuable insights into intelligent computing for academic and industrial researchers and practitioners.
MONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
MotionBERT: Unified Pretraining for Human Motion Analysis
Oct 12, 2022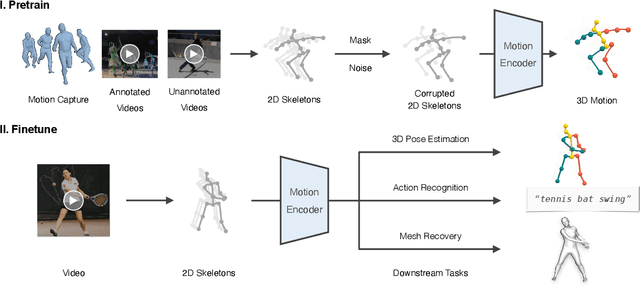
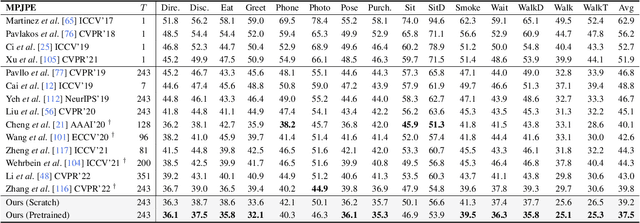
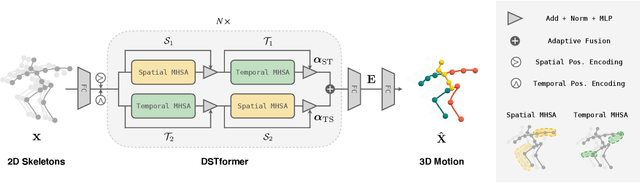
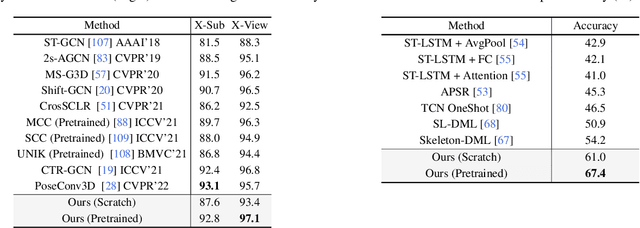
We present MotionBERT, a unified pretraining framework, to tackle different sub-tasks of human motion analysis including 3D pose estimation, skeleton-based action recognition, and mesh recovery. The proposed framework is capable of utilizing all kinds of human motion data resources, including motion capture data and in-the-wild videos. During pretraining, the pretext task requires the motion encoder to recover the underlying 3D motion from noisy partial 2D observations. The pretrained motion representation thus acquires geometric, kinematic, and physical knowledge about human motion and therefore can be easily transferred to multiple downstream tasks. We implement the motion encoder with a novel Dual-stream Spatio-temporal Transformer (DSTformer) neural network. It could capture long-range spatio-temporal relationships among the skeletal joints comprehensively and adaptively, exemplified by the lowest 3D pose estimation error so far when trained from scratch. More importantly, the proposed framework achieves state-of-the-art performance on all three downstream tasks by simply finetuning the pretrained motion encoder with 1-2 linear layers, which demonstrates the versatility of the learned motion representations.
Anti-Retroactive Interference for Lifelong Learning
Aug 27, 2022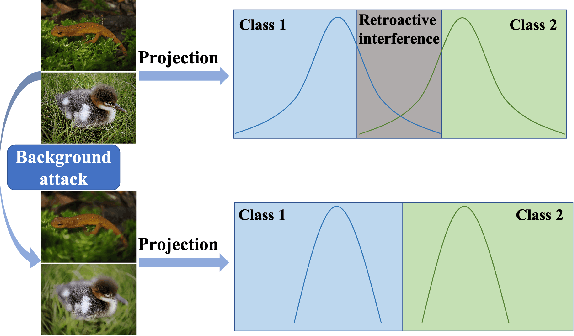
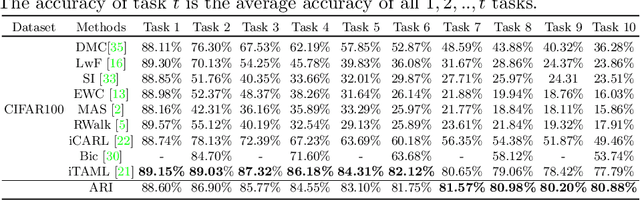
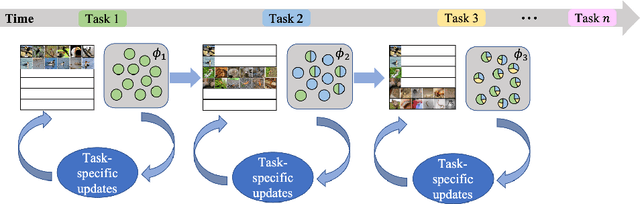

Humans can continuously learn new knowledge. However, machine learning models suffer from drastic dropping in performance on previous tasks after learning new tasks. Cognitive science points out that the competition of similar knowledge is an important cause of forgetting. In this paper, we design a paradigm for lifelong learning based on meta-learning and associative mechanism of the brain. It tackles the problem from two aspects: extracting knowledge and memorizing knowledge. First, we disrupt the sample's background distribution through a background attack, which strengthens the model to extract the key features of each task. Second, according to the similarity between incremental knowledge and base knowledge, we design an adaptive fusion of incremental knowledge, which helps the model allocate capacity to the knowledge of different difficulties. It is theoretically analyzed that the proposed learning paradigm can make the models of different tasks converge to the same optimum. The proposed method is validated on the MNIST, CIFAR100, CUB200 and ImageNet100 datasets.
CelebV-HQ: A Large-Scale Video Facial Attributes Dataset
Jul 25, 2022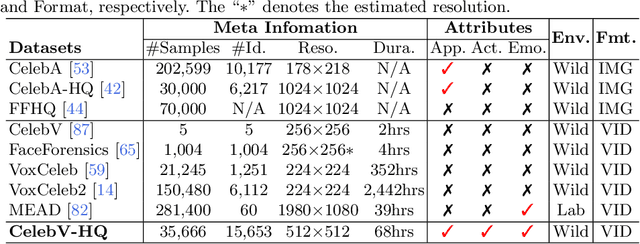
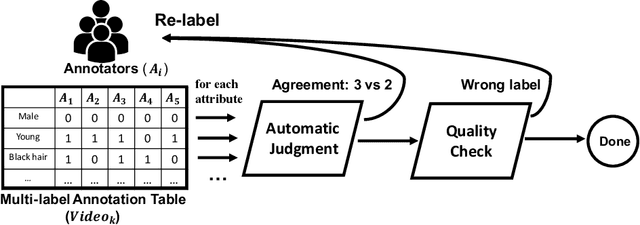

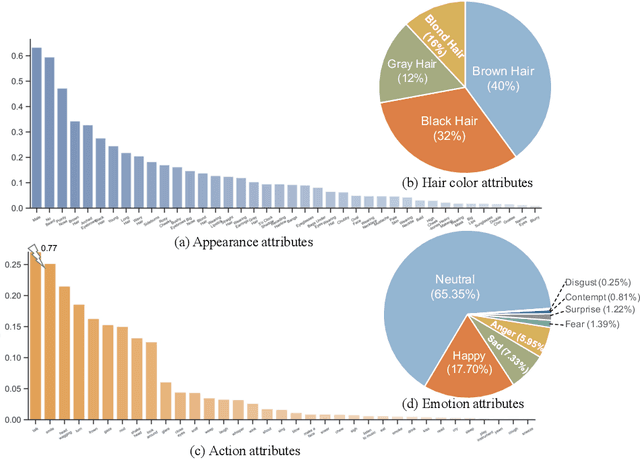
Large-scale datasets have played indispensable roles in the recent success of face generation/editing and significantly facilitated the advances of emerging research fields. However, the academic community still lacks a video dataset with diverse facial attribute annotations, which is crucial for the research on face-related videos. In this work, we propose a large-scale, high-quality, and diverse video dataset with rich facial attribute annotations, named the High-Quality Celebrity Video Dataset (CelebV-HQ). CelebV-HQ contains 35,666 video clips with the resolution of 512x512 at least, involving 15,653 identities. All clips are labeled manually with 83 facial attributes, covering appearance, action, and emotion. We conduct a comprehensive analysis in terms of age, ethnicity, brightness stability, motion smoothness, head pose diversity, and data quality to demonstrate the diversity and temporal coherence of CelebV-HQ. Besides, its versatility and potential are validated on two representative tasks, i.e., unconditional video generation and video facial attribute editing. Furthermore, we envision the future potential of CelebV-HQ, as well as the new opportunities and challenges it would bring to related research directions. Data, code, and models are publicly available. Project page: https://celebv-hq.github.io.
Faster VoxelPose: Real-time 3D Human Pose Estimation by Orthographic Projection
Jul 22, 2022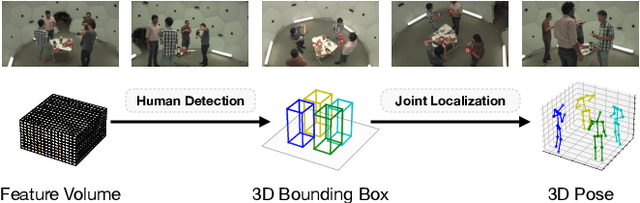

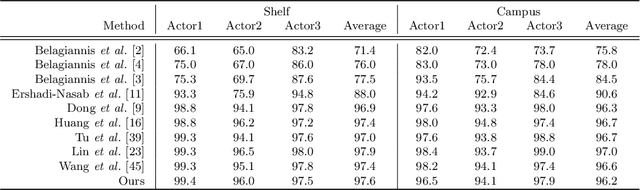
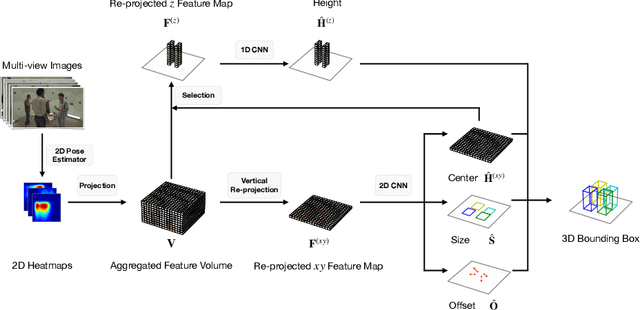
While the voxel-based methods have achieved promising results for multi-person 3D pose estimation from multi-cameras, they suffer from heavy computation burdens, especially for large scenes. We present Faster VoxelPose to address the challenge by re-projecting the feature volume to the three two-dimensional coordinate planes and estimating X, Y, Z coordinates from them separately. To that end, we first localize each person by a 3D bounding box by estimating a 2D box and its height based on the volume features projected to the xy-plane and z-axis, respectively. Then for each person, we estimate partial joint coordinates from the three coordinate planes separately which are then fused to obtain the final 3D pose. The method is free from costly 3D-CNNs and improves the speed of VoxelPose by ten times and meanwhile achieves competitive accuracy as the state-of-the-art methods, proving its potential in real-time applications.