 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Segmentation of Non-Rigid Surgical Tools based on Deep Learning and Tracking
Sep 07, 2020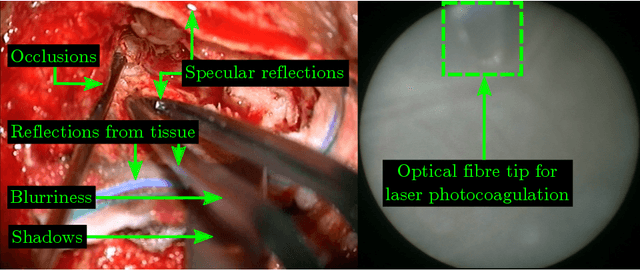

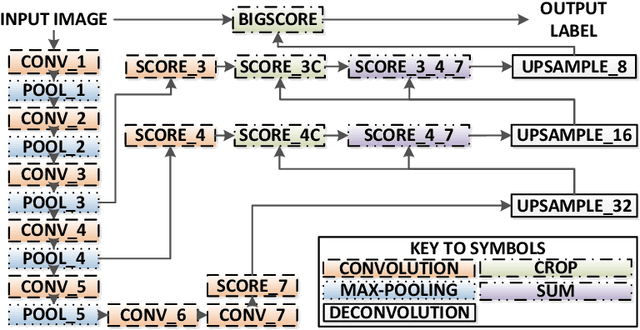
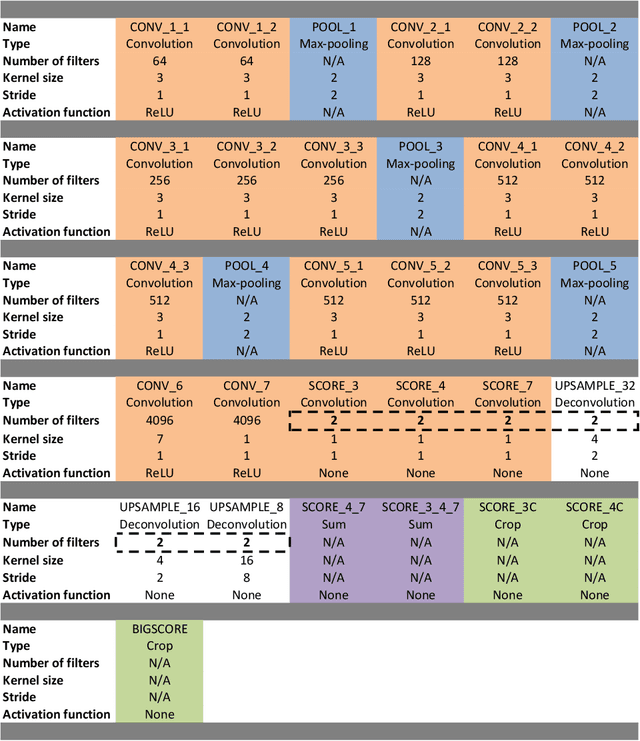
Real-time tool segmentation is an essential component in computer-assisted surgical systems. We propose a novel real-time automatic method based on Fully Convolutional Networks (FCN) and optical flow tracking. Our method exploits the ability of deep neural networks to produce accurate segmentations of highly deformable parts along with the high speed of optical flow. Furthermore, the pre-trained FCN can be fine-tuned on a small amount of medical images without the need to hand-craft features. We validated our method using existing and new benchmark datasets, covering both ex vivo and in vivo real clinical cases where different surgical instruments are employed. Two versions of the method are presented, non-real-time and real-time. The former, using only deep learning, achieves a balanced accuracy of 89.6% on a real clinical dataset, outperforming the (non-real-time) state of the art by 3.8% points. The latter, a combination of deep learning with optical flow tracking, yields an average balanced accuracy of 78.2% across all the validated datasets.
LAMP: Large Deep Nets with Automated Model Parallelism for Image Segmentation
Jun 26, 2020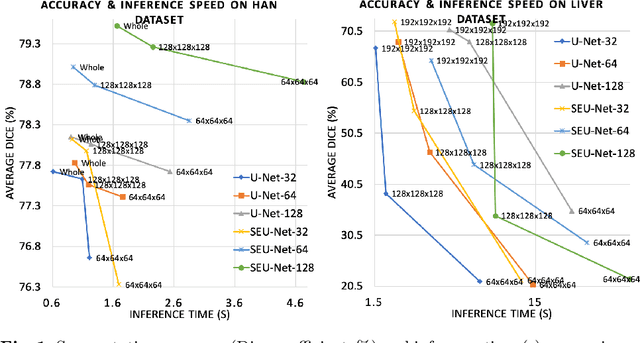
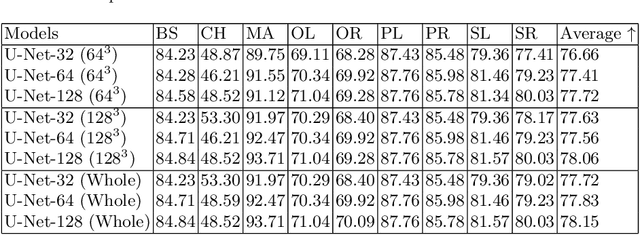
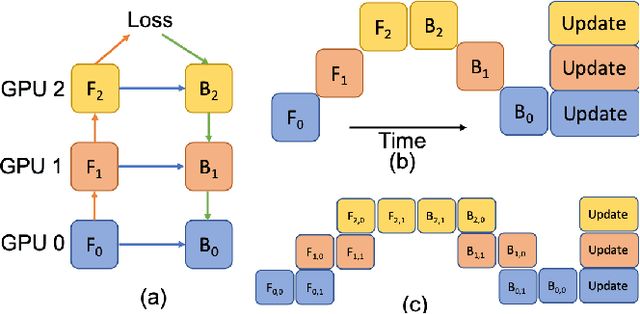
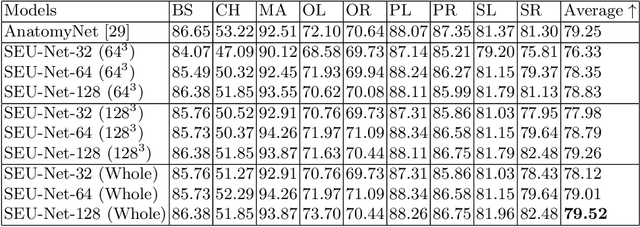
Deep Learning (DL) models are becoming larger, because the increase in model size might offer significant accuracy gain. To enable the training of large deep networks, data parallelism and model parallelism are two well-known approaches for parallel training. However, data parallelism does not help reduce memory footprint per device. In this work, we introduce Large deep 3D ConvNets with Automated Model Parallelism (LAMP) and investigate the impact of both input's and deep 3D ConvNets' size on segmentation accuracy. Through automated model parallelism, it is feasible to train large deep 3D ConvNets with a large input patch, even the whole image. Extensive experiments demonstrate that, facilitated by the automated model parallelism, the segmentation accuracy can be improved through increasing model size and input context size, and large input yields significant inference speedup compared with sliding window of small patches in the inference. Code is available\footnote{https://monai.io/research/lamp-automated-model-parallelism}.
The Future of Digital Health with Federated Learning
Mar 18, 2020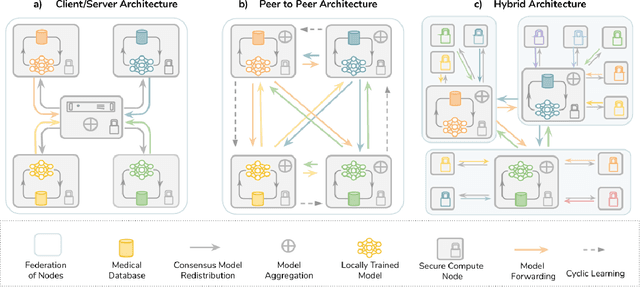
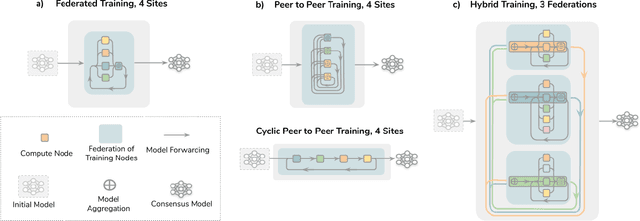
Data-driven Machine Learning has emerged as a promising approach for building accurate and robust statistical models from medical data, which is collected in huge volumes by modern healthcare systems. Existing medical data is not fully exploited by ML primarily because it sits in data silos and privacy concerns restrict access to this data. However, without access to sufficient data, ML will be prevented from reaching its full potential and, ultimately, from making the transition from research to clinical practice. This paper considers key factors contributing to this issue, explores how Federated Learning (FL) may provide a solution for the future of digital health and highlights the challenges and considerations that need to be addressed.
Overview of the CCKS 2019 Knowledge Graph Evaluation Track: Entity, Relation, Event and QA
Mar 09, 2020Knowledge graph models world knowledge as concepts, entities, and the relationships between them, which has been widely used in many real-world tasks. CCKS 2019 held an evaluation track with 6 tasks and attracted more than 1,600 teams. In this paper, we give an overview of the knowledge graph evaluation tract at CCKS 2019. By reviewing the task definition, successful methods, useful resources, good strategies and research challenges associated with each task in CCKS 2019, this paper can provide a helpful reference for developing knowledge graph applications and conducting future knowledge graph researches.
NeurReg: Neural Registration and Its Application to Image Segmentation
Oct 04, 2019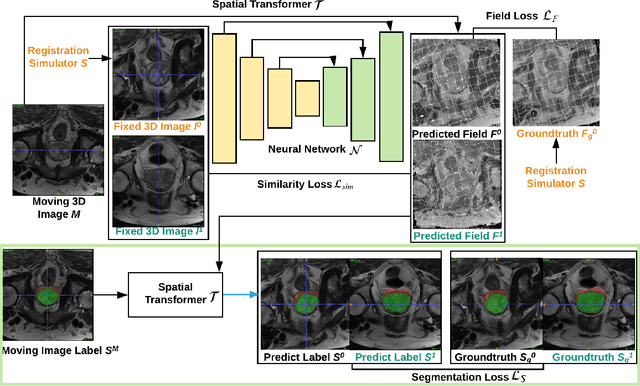
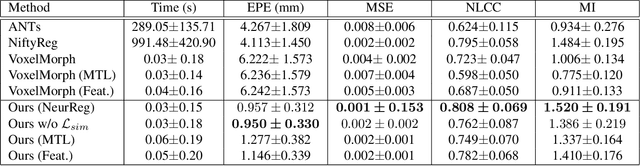
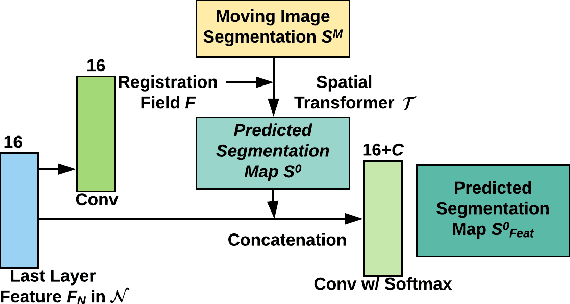
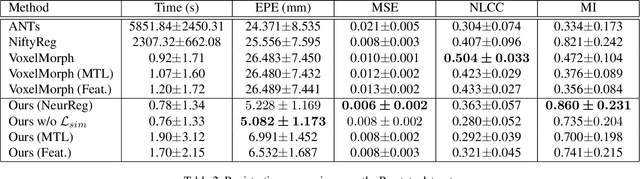
Registration is a fundamental task in medical image analysis which can be applied to several tasks including image segmentation, intra-operative tracking, multi-modal image alignment, and motion analysis. Popular registration tools such as ANTs and NiftyReg optimize an objective function for each pair of images from scratch which is time-consuming for large images with complicated deformation. Facilitated by the rapid progress of deep learning, learning-based approaches such as VoxelMorph have been emerging for image registration. These approaches can achieve competitive performance in a fraction of a second on advanced GPUs. In this work, we construct a neural registration framework, called NeurReg, with a hybrid loss of displacement fields and data similarity, which substantially improves the current state-of-the-art of registrations. Within the framework, we simulate various transformations by a registration simulator which generates fixed image and displacement field ground truth for training. Furthermore, we design three segmentation frameworks based on the proposed registration framework: 1) atlas-based segmentation, 2) joint learning of both segmentation and registration tasks, and 3) multi-task learning with atlas-based segmentation as an intermediate feature. Extensive experimental results validate the effectiveness of the proposed NeurReg framework based on various metrics: the endpoint error (EPE) of the predicted displacement field, mean square error (MSE), normalized local cross-correlation (NLCC), mutual information (MI), Dice coefficient, uncertainty estimation, and the interpretability of the segmentation. The proposed NeurReg improves registration accuracy with fast inference speed, which can greatly accelerate related medical image analysis tasks.
Privacy-preserving Federated Brain Tumour Segmentation
Oct 02, 2019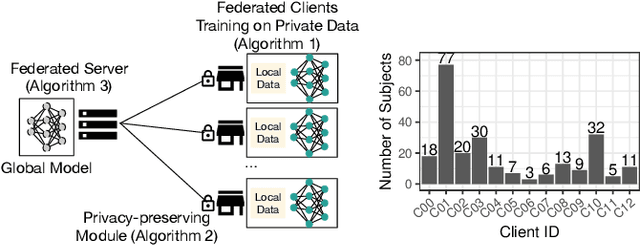
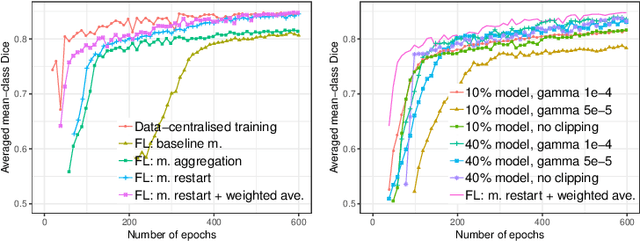
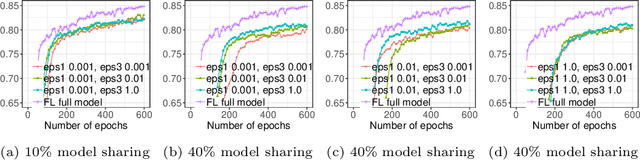
Due to medical data privacy regulations, it is often infeasible to collect and share patient data in a centralised data lake. This poses challenges for training machine learning algorithms, such as deep convolutional networks, which often require large numbers of diverse training examples. Federated learning sidesteps this difficulty by bringing code to the patient data owners and only sharing intermediate model training updates among them. Although a high-accuracy model could be achieved by appropriately aggregating these model updates, the model shared could indirectly leak the local training examples. In this paper, we investigate the feasibility of applying differential-privacy techniques to protect the patient data in a federated learning setup. We implement and evaluate practical federated learning systems for brain tumour segmentation on the BraTS dataset. The experimental results show that there is a trade-off between model performance and privacy protection costs.
Learning joint lesion and tissue segmentation from task-specific hetero-modal datasets
Jul 07, 2019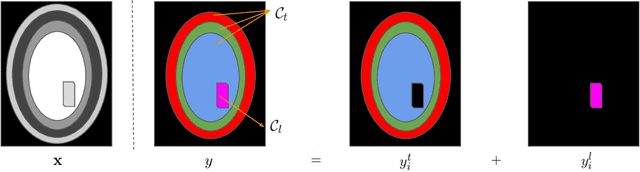
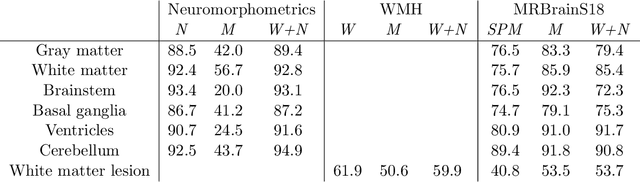
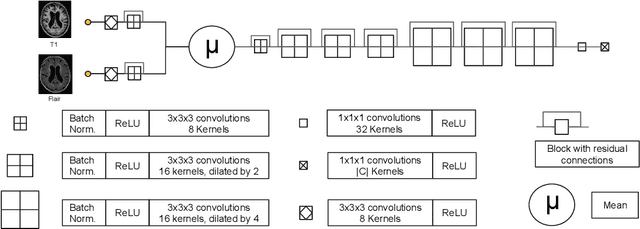
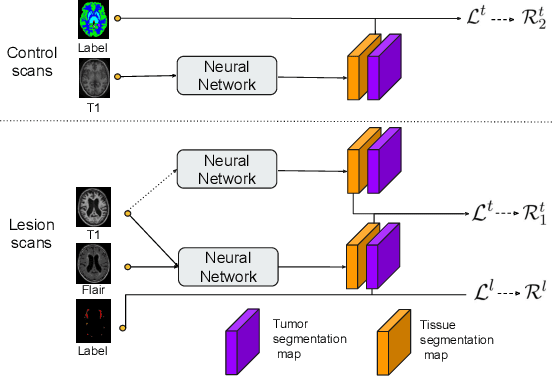
Brain tissue segmentation from multimodal MRI is a key building block of many neuroscience analysis pipelines. It could also play an important role in many clinical imaging scenarios. Established tissue segmentation approaches have however not been developed to cope with large anatomical changes resulting from pathology. The effect of the presence of brain lesions, for example, on their performance is thus currently uncontrolled and practically unpredictable. Contrastingly, with the advent of deep neural networks (DNNs), segmentation of brain lesions has matured significantly and is achieving performance levels making it of interest for clinical use. However, few existing approaches allow for jointly segmenting normal tissue and brain lesions. Developing a DNN for such joint task is currently hampered by the fact that annotated datasets typically address only one specific task and rely on a task-specific hetero-modal imaging protocol. In this work, we propose a novel approach to build a joint tissue and lesion segmentation model from task-specific hetero-modal and partially annotated datasets. Starting from a variational formulation of the joint problem, we show how the expected risk can be decomposed and optimised empirically. We exploit an upper-bound of the risk to deal with missing imaging modalities. For each task, our approach reaches comparable performance than task-specific and fully-supervised models.
Automatic Segmentation of Vestibular Schwannoma from T2-Weighted MRI by Deep Spatial Attention with Hardness-Weighted Loss
Jun 10, 2019
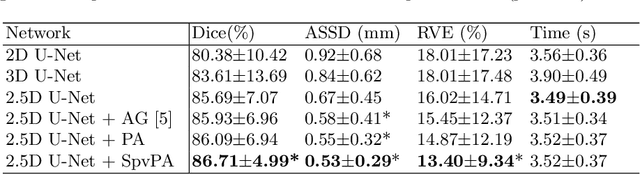
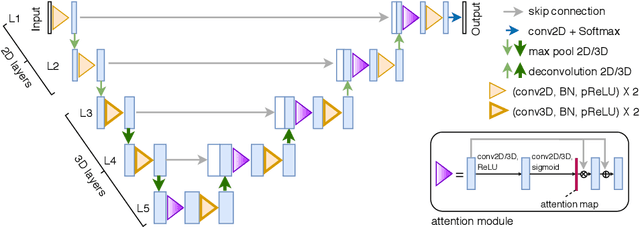

Automatic segmentation of vestibular schwannoma (VS) tumors from magnetic resonance imaging (MRI) would facilitate efficient and accurate volume measurement to guide patient management and improve clinical workflow. The accuracy and robustness is challenged by low contrast, small target region and low through-plane resolution. We introduce a 2.5D convolutional neural network (CNN) able to exploit the different in-plane and through-plane resolutions encountered in standard of care imaging protocols. We use an attention module to enable the CNN to focus on the small target and propose a supervision on the learning of attention maps for more accurate segmentation. Additionally, we propose a hardness-weighted Dice loss function that gives higher weights to harder voxels to boost the training of CNNs. Experiments with ablation studies on the VS tumor segmentation task show that: 1) the proposed 2.5D CNN outperforms its 2D and 3D counterparts, 2) our supervised attention mechanism outperforms unsupervised attention, 3) the voxel-level hardness-weighted Dice loss can improve the performance of CNNs. Our method achieved an average Dice score and ASSD of 0.87 and 0.43~mm respectively. This will facilitate patient management decisions in clinical practice.
2017 Robotic Instrument Segmentation Challenge
Feb 21, 2019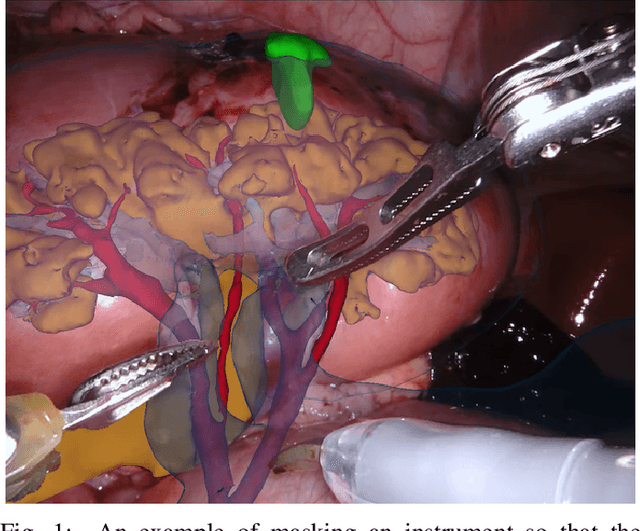
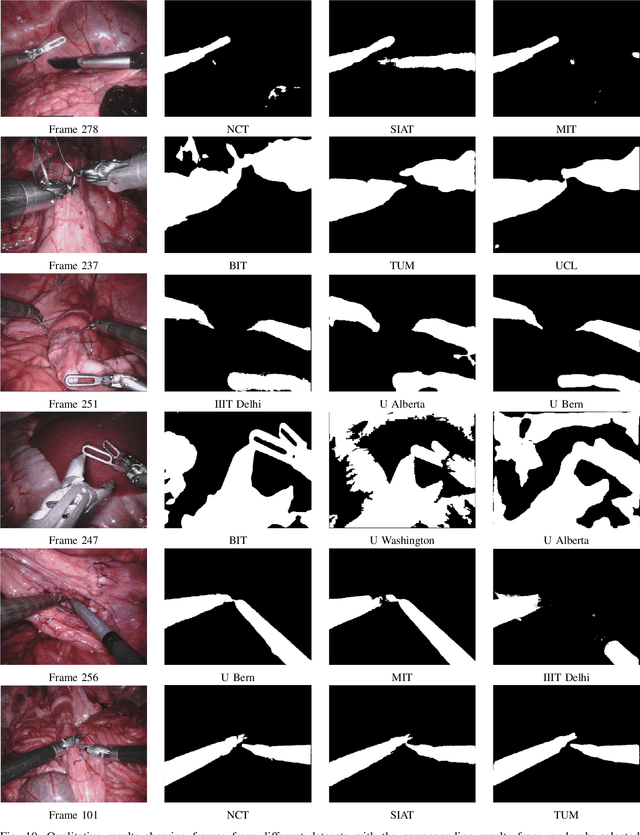
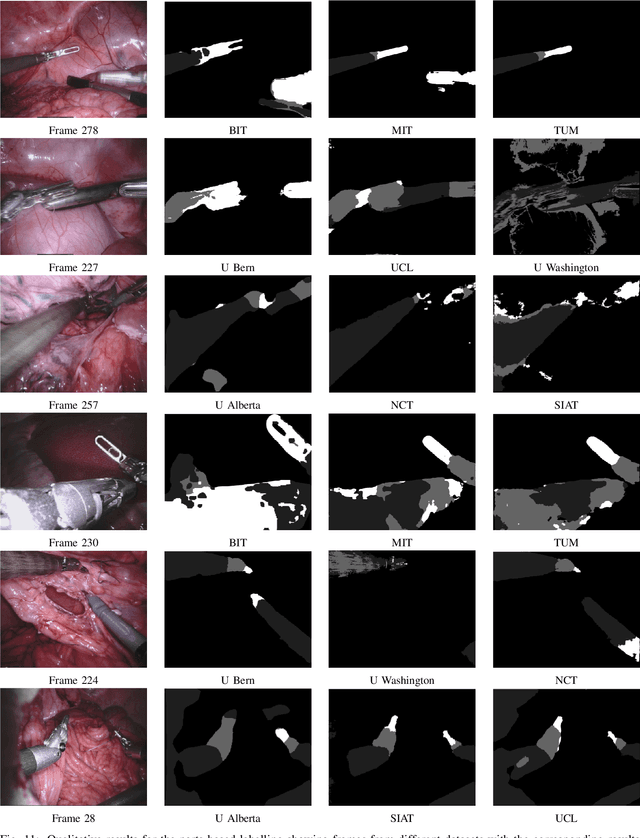

In mainstream computer vision and machine learning, public datasets such as ImageNet, COCO and KITTI have helped drive enormous improvements by enabling researchers to understand the strengths and limitations of different algorithms via performance comparison. However, this type of approach has had limited translation to problems in robotic assisted surgery as this field has never established the same level of common datasets and benchmarking methods. In 2015 a sub-challenge was introduced at the EndoVis workshop where a set of robotic images were provided with automatically generated annotations from robot forward kinematics. However, there were issues with this dataset due to the limited background variation, lack of complex motion and inaccuracies in the annotation. In this work we present the results of the 2017 challenge on robotic instrument segmentation which involved 10 teams participating in binary, parts and type based segmentation of articulated da Vinci robotic instruments.
Automatic Brain Tumor Segmentation using Convolutional Neural Networks with Test-Time Augmentation
Oct 18, 2018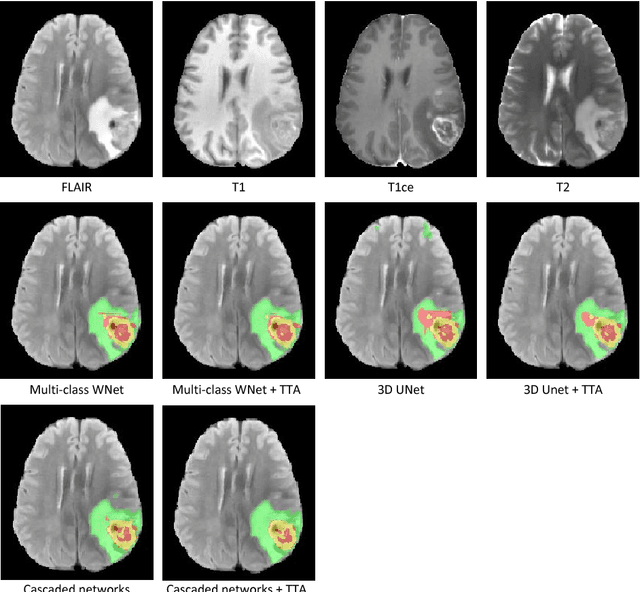
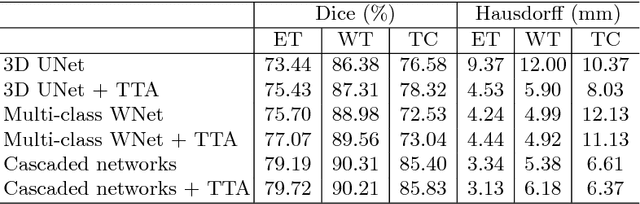
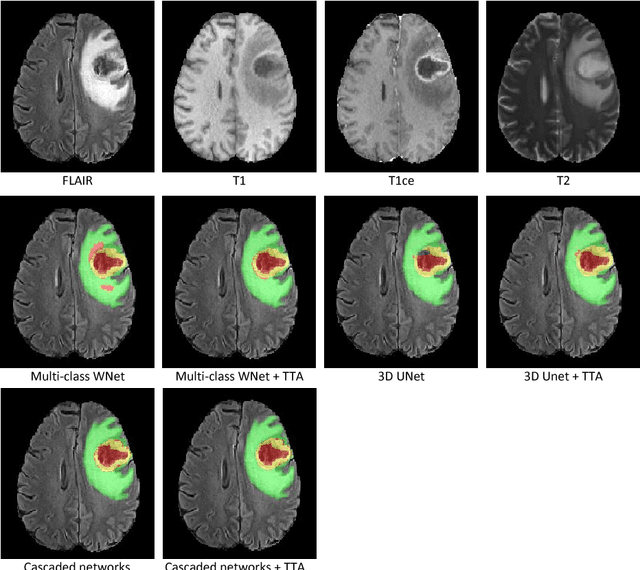
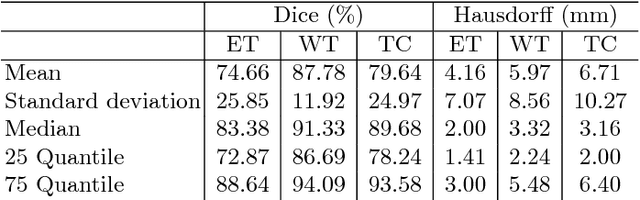
Automatic brain tumor segmentation plays an important role for diagnosis, surgical planning and treatment assessment of brain tumors. Deep convolutional neural networks (CNNs) have been widely used for this task. Due to the relatively small data set for training, data augmentation at training time has been commonly used for better performance of CNNs. Recent works also demonstrated the usefulness of using augmentation at test time, in addition to training time, for achieving more robust predictions. We investigate how test-time augmentation can improve CNNs' performance for brain tumor segmentation. We used different underpinning network structures and augmented the image by 3D rotation, flipping, scaling and adding random noise at both training and test time. Experiments with BraTS 2018 training and validation set show that test-time augmentation helps to improve the brain tumor segmentation accuracy and obtain uncertainty estimation of the segmentation results.