 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Data-driven Joint-level Calibration of Cable-driven Surgical Robots
Aug 02, 2024Knowing accurate joint positions is crucial for safe and precise control of laparoscopic surgical robots, especially for the automation of surgical sub-tasks. These robots have often been designed with cable-driven arms and tools because cables allow for larger motors to be placed at the base of the robot, further from the operating area where space is at a premium. However, by connecting the joint to its motor with a cable, any stretch in the cable can lead to errors in kinematic estimation from encoders at the motor, which can result in difficulties for accurate control of the surgical tool. In this work, we propose an efficient data-driven calibration of positioning joints of such robots, in this case the RAVEN-II surgical robotics research platform. While the calibration takes only 8-21 minutes, the accuracy of the calibrated joints remains high during a 6-hour heavily loaded operation, suggesting desirable feasibility in real practice. The calibration models take original robot states as input and are trained using zig-zag trajectories within a desired sparsity, requiring no additional sensors after training. Compared to fixed offset compensation, the Deep Neural Network calibration model can further reduce 76 percent of error and achieve accuracy of 0.104 deg, 0.120 deg, and 0.118 mm in joints 1, 2, and 3, respectively. In contrast to end-to-end models, experiments suggest that the DNN model achieves better accuracy and faster convergence when outputting the error to correct original inaccurate joint positions. Furthermore, a linear regression model is shown to have 160 times faster inference speed than DNN models for application within the 1000 Hz servo control loop, with slightly compromised accuracy.
Reducing Annotating Load: Active Learning with Synthetic Images in Surgical Instrument Segmentation
Aug 07, 2021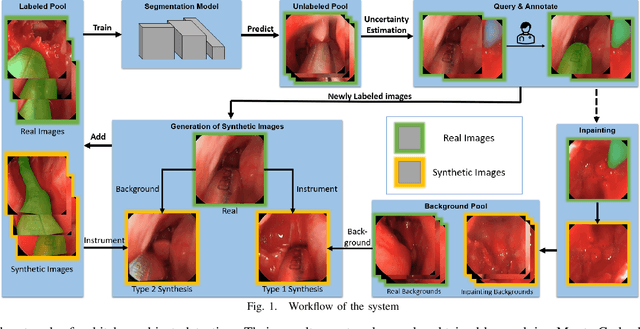
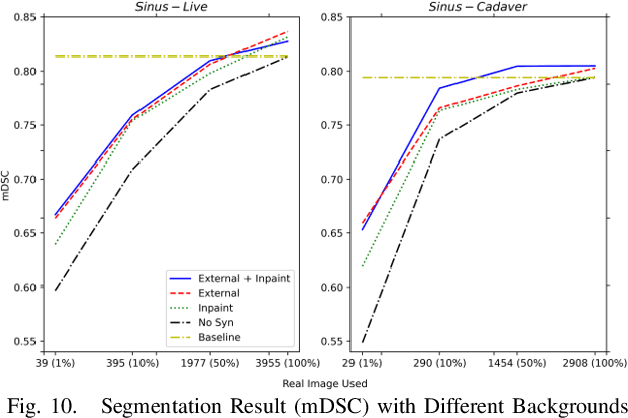
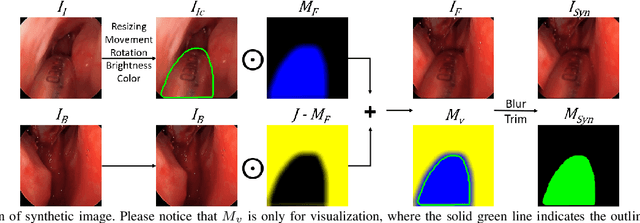
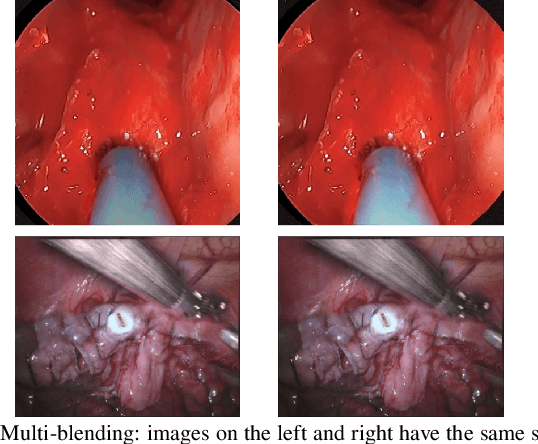
Accurate instrument segmentation in endoscopic vision of robot-assisted surgery is challenging due to reflection on the instruments and frequent contacts with tissue. Deep neural networks (DNN) show competitive performance and are in favor in recent years. However, the hunger of DNN for labeled data poses a huge workload of annotation. Motivated by alleviating this workload, we propose a general embeddable method to decrease the usage of labeled real images, using active generated synthetic images. In each active learning iteration, the most informative unlabeled images are first queried by active learning and then labeled. Next, synthetic images are generated based on these selected images. The instruments and backgrounds are cropped out and randomly combined with each other with blending and fusion near the boundary. The effectiveness of the proposed method is validated on 2 sinus surgery datasets and 1 intraabdominal surgery dataset. The results indicate a considerable improvement in performance, especially when the budget for annotation is small. The effectiveness of different types of synthetic images, blending methods, and external background are also studied. All the code is open-sourced at: https://github.com/HaonanPeng/active_syn_generator.
Real-time Data Driven Precision Estimator for RAVEN-II Surgical Robot End Effector Position
Oct 14, 2019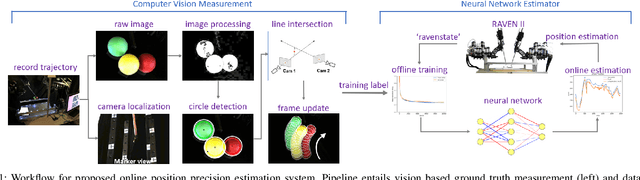
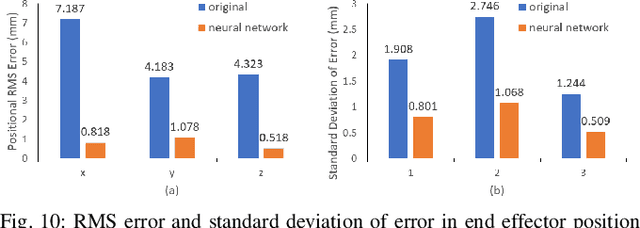
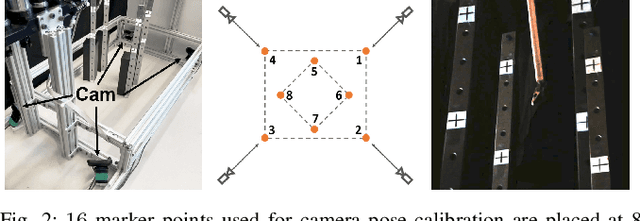

Surgical robots have been introduced to operating rooms over the past few decades due to their high sensitivity, small size, and remote controllability. The cable-driven nature of many surgical robots allows the systems to be dexterous and lightweight, with diameters as low as 5mm. However, due to the slack and stretch of the cables and the backlash of the gears, inevitable uncertainties are brought into the kinematics calculation. Since the reported end effector position of surgical robots like RAVEN-II is directly calculated using the motor encoder measurements and forward kinematics, it may contain relatively large error up to 10mm, whereas semi-autonomous functions being introduced into abdominal surgeries require position inaccuracy of at most 1mm. To resolve the problem, a cost-effective, real-time and data-driven pipeline for robot end effector position precision estimation is proposed and tested on RAVEN-II. Analysis shows an improved end effector position error of around 1mm RMS traversing through the entire robot workspace without high-resolution motion tracker.
2017 Robotic Instrument Segmentation Challenge
Feb 21, 2019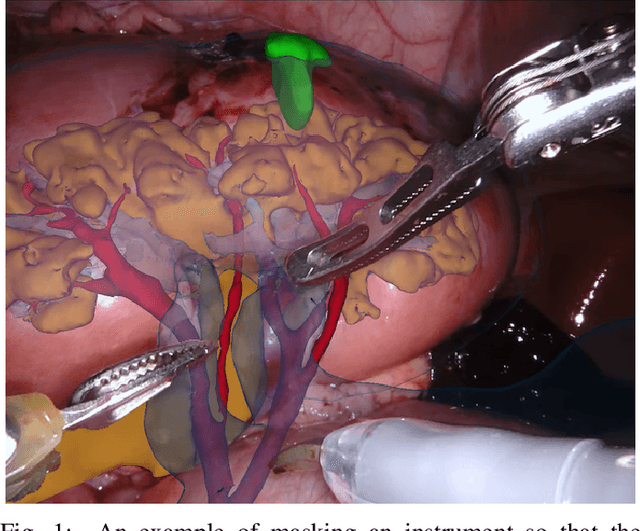
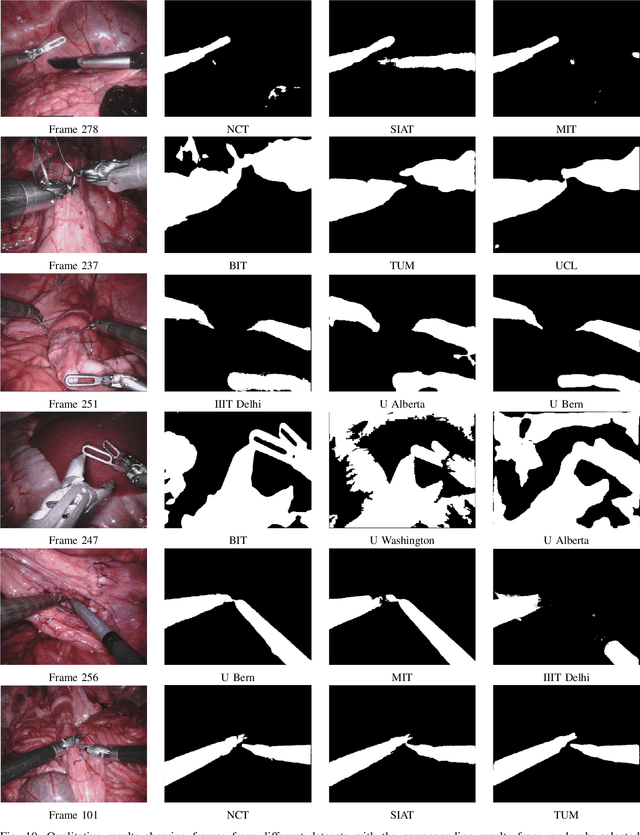
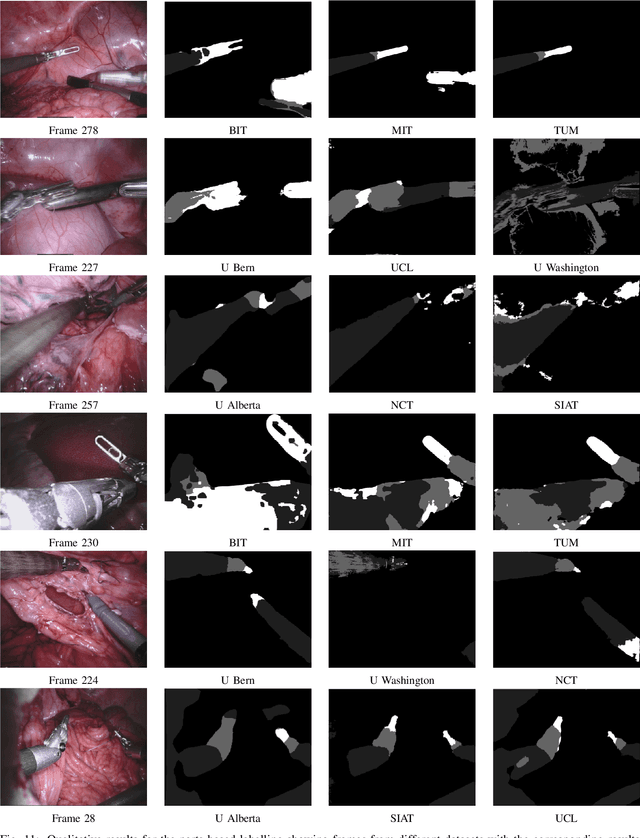

In mainstream computer vision and machine learning, public datasets such as ImageNet, COCO and KITTI have helped drive enormous improvements by enabling researchers to understand the strengths and limitations of different algorithms via performance comparison. However, this type of approach has had limited translation to problems in robotic assisted surgery as this field has never established the same level of common datasets and benchmarking methods. In 2015 a sub-challenge was introduced at the EndoVis workshop where a set of robotic images were provided with automatically generated annotations from robot forward kinematics. However, there were issues with this dataset due to the limited background variation, lack of complex motion and inaccuracies in the annotation. In this work we present the results of the 2017 challenge on robotic instrument segmentation which involved 10 teams participating in binary, parts and type based segmentation of articulated da Vinci robotic instruments.