 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Cross-Modal Knowledge Exploration for Video Recognition with Pre-trained Vision-Language Models
Dec 31, 2022



Vision-language models (VLMs) that are pre-trained on large-scale image-text pairs have demonstrated impressive transferability on a wide range of visual tasks. Transferring knowledge from such powerful pre-trained VLMs is emerging as a promising direction for building effective video recognition models. However, the current exploration is still limited. In our opinion, the greatest charm of pre-trained vision-language models is to build a bridge between visual and textual domains. In this paper, we present a novel framework called BIKE which utilizes the cross-modal bridge to explore bidirectional knowledge: i) We propose a Video Attribute Association mechanism which leverages the Video-to-Text knowledge to generate textual auxiliary attributes to complement video recognition. ii) We also present a Temporal Concept Spotting mechanism which uses the Text-to-Video expertise to capture temporal saliency in a parameter-free manner to yield enhanced video representation. The extensive studies on popular video datasets (ie, Kinetics-400 & 600, UCF-101, HMDB-51 and ActivityNet) show that our method achieves state-of-the-art performance in most recognition scenarios, eg, general, zero-shot, and few-shot video recognition. To the best of our knowledge, our best model achieves a state-of-the-art accuracy of 88.4% on challenging Kinetics-400 with the released CLIP pre-trained model.
Cap4Video: What Can Auxiliary Captions Do for Text-Video Retrieval?
Dec 31, 2022



Most existing text-video retrieval methods focus on cross-modal matching between the visual content of offline videos and textual query sentences. However, in real scenarios, online videos are frequently accompanied by relevant text information such as titles, tags, and even subtitles, which can be utilized to match textual queries. This inspires us to generate associated captions from offline videos to help with existing text-video retrieval methods. To do so, we propose to use the zero-shot video captioner with knowledge of pre-trained web-scale models (e.g., CLIP and GPT-2) to generate captions for offline videos without any training. Given the captions, one question naturally arises: what can auxiliary captions do for text-video retrieval? In this paper, we present a novel framework Cap4Video, which makes use of captions from three aspects: i) Input data: The video and captions can form new video-caption pairs as data augmentation for training. ii) Feature interaction: We perform feature interaction between video and caption to yield enhanced video representations. iii) Output score: The Query-Caption matching branch can be complementary to the original Query-Video matching branch for text-video retrieval. We conduct thorough ablation studies to demonstrate the effectiveness of our method. Without any post-processing, our Cap4Video achieves state-of-the-art performance on MSR-VTT (51.4%), VATEX (66.6%), MSVD (51.8%), and DiDeMo (52.0%).
WeCheck: Strong Factual Consistency Checker via Weakly Supervised Learning
Dec 20, 2022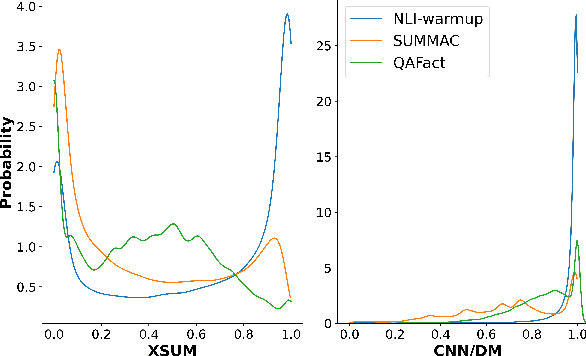
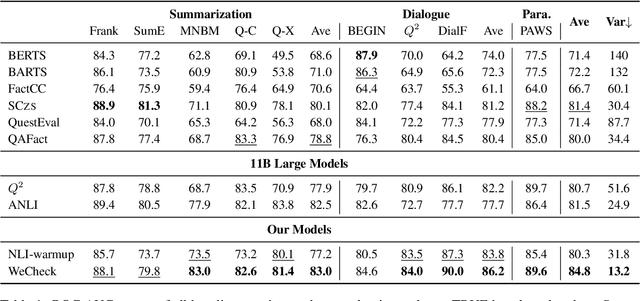
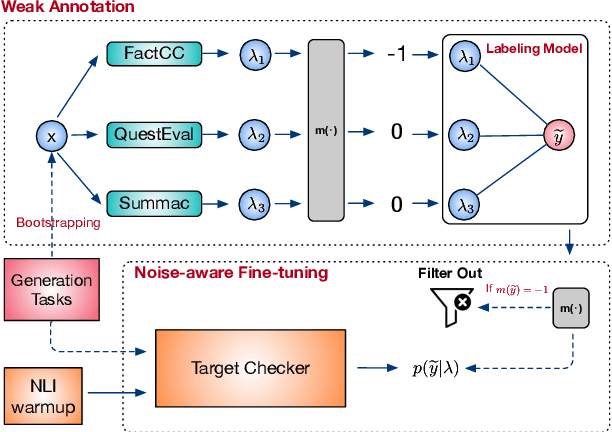
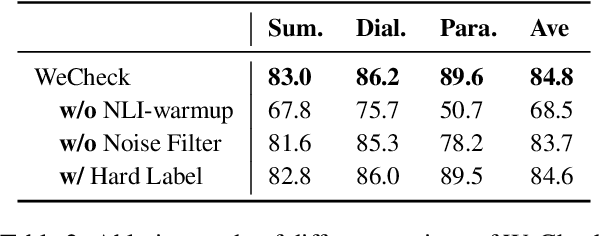
A crucial issue of current text generation models is that they often uncontrollably generate factually inconsistent text with respective of their inputs. Limited by the lack of annotated data, existing works in evaluating factual consistency directly transfer the reasoning ability of models trained on other data-rich upstream tasks like question answering (QA) and natural language inference (NLI) without any further adaptation. As a result, they perform poorly on the real generated text and are biased heavily by their single-source upstream tasks. To alleviate this problem, we propose a weakly supervised framework that aggregates multiple resources to train a precise and efficient factual metric, namely WeCheck. WeCheck first utilizes a generative model to accurately label a real generated sample by aggregating its weak labels, which are inferred from multiple resources. Then, we train the target metric model with the weak supervision while taking noises into consideration. Comprehensive experiments on a variety of tasks demonstrate the strong performance of WeCheck, which achieves a 3.4\% absolute improvement over previous state-of-the-art methods on TRUE benchmark on average.
AdaCM: Adaptive ColorMLP for Real-Time Universal Photo-realistic Style Transfer
Dec 03, 2022Photo-realistic style transfer aims at migrating the artistic style from an exemplar style image to a content image, producing a result image without spatial distortions or unrealistic artifacts. Impressive results have been achieved by recent deep models. However, deep neural network based methods are too expensive to run in real-time. Meanwhile, bilateral grid based methods are much faster but still contain artifacts like overexposure. In this work, we propose the \textbf{Adaptive ColorMLP (AdaCM)}, an effective and efficient framework for universal photo-realistic style transfer. First, we find the complex non-linear color mapping between input and target domain can be efficiently modeled by a small multi-layer perceptron (ColorMLP) model. Then, in \textbf{AdaCM}, we adopt a CNN encoder to adaptively predict all parameters for the ColorMLP conditioned on each input content and style image pair. Experimental results demonstrate that AdaCM can generate vivid and high-quality stylization results. Meanwhile, our AdaCM is ultrafast and can process a 4K resolution image in 6ms on one V100 GPU.
FRSUM: Towards Faithful Abstractive Summarization via Enhancing Factual Robustness
Nov 01, 2022Despite being able to generate fluent and grammatical text, current Seq2Seq summarization models still suffering from the unfaithful generation problem. In this paper, we study the faithfulness of existing systems from a new perspective of factual robustness which is the ability to correctly generate factual information over adversarial unfaithful information. We first measure a model's factual robustness by its success rate to defend against adversarial attacks when generating factual information. The factual robustness analysis on a wide range of current systems shows its good consistency with human judgments on faithfulness. Inspired by these findings, we propose to improve the faithfulness of a model by enhancing its factual robustness. Specifically, we propose a novel training strategy, namely FRSUM, which teaches the model to defend against both explicit adversarial samples and implicit factual adversarial perturbations. Extensive automatic and human evaluation results show that FRSUM consistently improves the faithfulness of various Seq2Seq models, such as T5, BART.
It Takes Two: Masked Appearance-Motion Modeling for Self-supervised Video Transformer Pre-training
Oct 11, 2022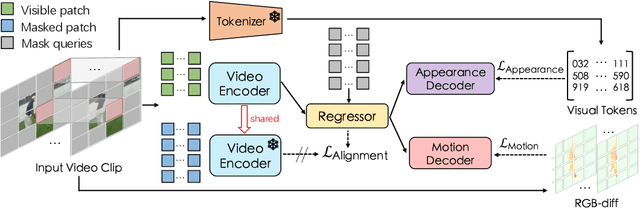

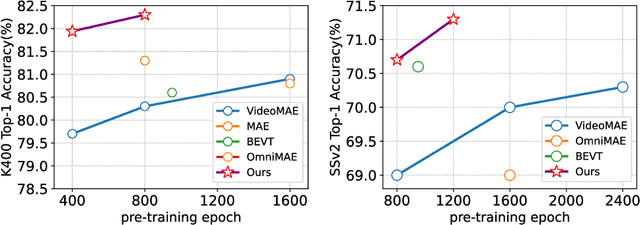
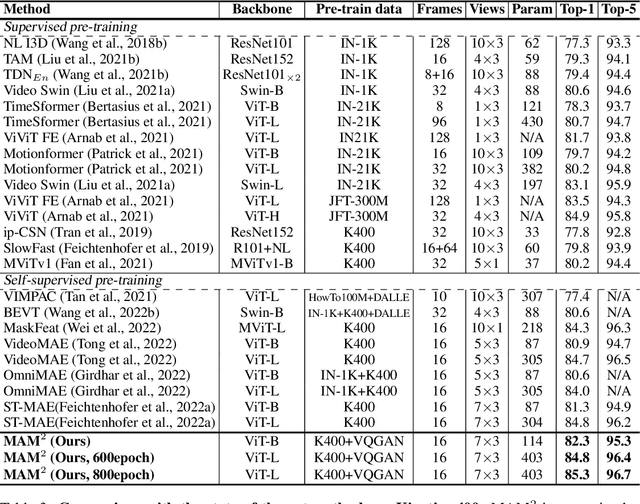
Self-supervised video transformer pre-training has recently benefited from the mask-and-predict pipeline. They have demonstrated outstanding effectiveness on downstream video tasks and superior data efficiency on small datasets. However, temporal relation is not fully exploited by these methods. In this work, we explicitly investigate motion cues in videos as extra prediction target and propose our Masked Appearance-Motion Modeling (MAM2) framework. Specifically, we design an encoder-regressor-decoder pipeline for this task. The regressor separates feature encoding and pretext tasks completion, such that the feature extraction process is completed adequately by the encoder. In order to guide the encoder to fully excavate spatial-temporal features, two separate decoders are used for two pretext tasks of disentangled appearance and motion prediction. We explore various motion prediction targets and figure out RGB-difference is simple yet effective. As for appearance prediction, VQGAN codes are leveraged as prediction target. With our pre-training pipeline, convergence can be remarkably speed up, e.g., we only require half of epochs than state-of-the-art VideoMAE (400 v.s. 800) to achieve the competitive performance. Extensive experimental results prove that our method learns generalized video representations. Notably, our MAM2 with ViT-B achieves 82.3% on Kinects-400, 71.3% on Something-Something V2, 91.5% on UCF101, and 62.5% on HMDB51.
Effective Invertible Arbitrary Image Rescaling
Sep 26, 2022
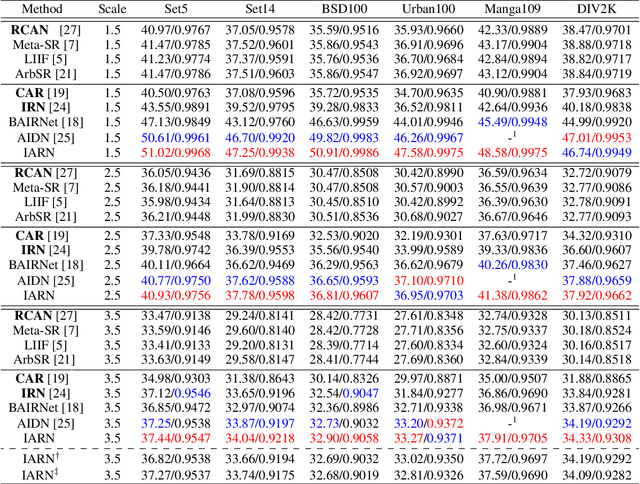
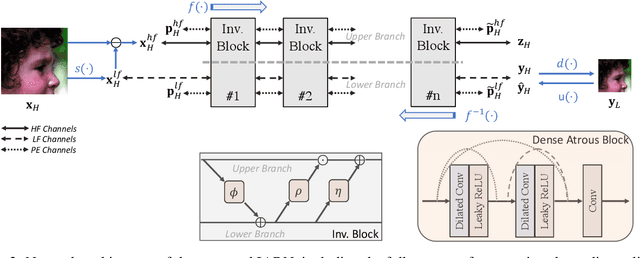
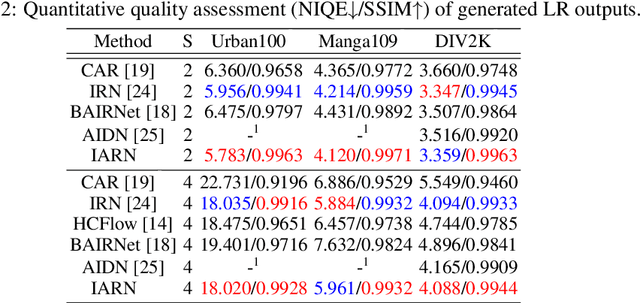
Great successes have been achieved using deep learning techniques for image super-resolution (SR) with fixed scales. To increase its real world applicability, numerous models have also been proposed to restore SR images with arbitrary scale factors, including asymmetric ones where images are resized to different scales along horizontal and vertical directions. Though most models are only optimized for the unidirectional upscaling task while assuming a predefined downscaling kernel for low-resolution (LR) inputs, recent models based on Invertible Neural Networks (INN) are able to increase upscaling accuracy significantly by optimizing the downscaling and upscaling cycle jointly. However, limited by the INN architecture, it is constrained to fixed integer scale factors and requires one model for each scale. Without increasing model complexity, a simple and effective invertible arbitrary rescaling network (IARN) is proposed to achieve arbitrary image rescaling by training only one model in this work. Using innovative components like position-aware scale encoding and preemptive channel splitting, the network is optimized to convert the non-invertible rescaling cycle to an effectively invertible process. It is shown to achieve a state-of-the-art (SOTA) performance in bidirectional arbitrary rescaling without compromising perceptual quality in LR outputs. It is also demonstrated to perform well on tests with asymmetric scales using the same network architecture.
CODER: Coupled Diversity-Sensitive Momentum Contrastive Learning for Image-Text Retrieval
Aug 21, 2022
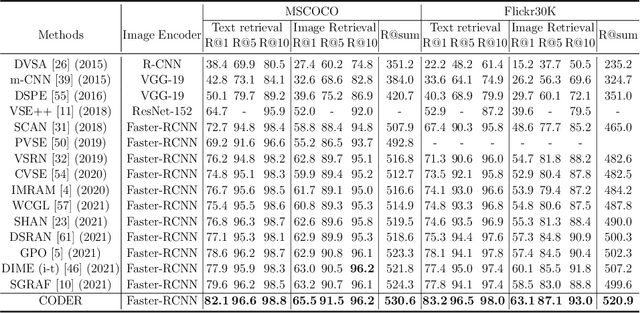
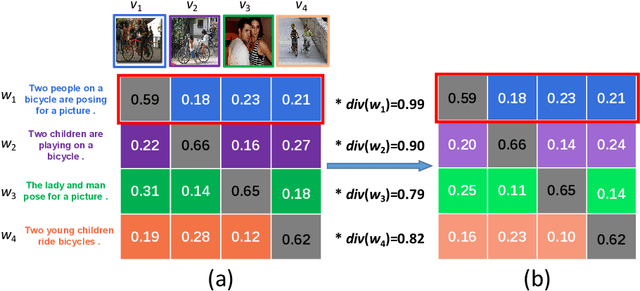
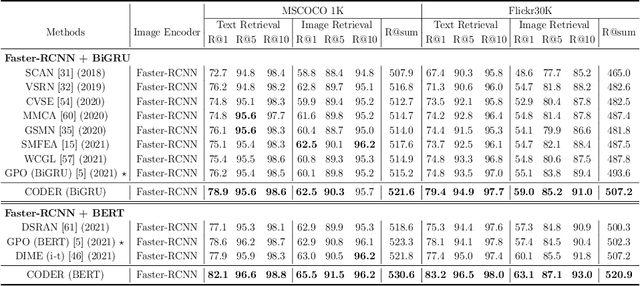
Image-Text Retrieval (ITR) is challenging in bridging visual and lingual modalities. Contrastive learning has been adopted by most prior arts. Except for limited amount of negative image-text pairs, the capability of constrastive learning is restricted by manually weighting negative pairs as well as unawareness of external knowledge. In this paper, we propose our novel Coupled Diversity-Sensitive Momentum Constrastive Learning (CODER) for improving cross-modal representation. Firstly, a novel diversity-sensitive contrastive learning (DCL) architecture is invented. We introduce dynamic dictionaries for both modalities to enlarge the scale of image-text pairs, and diversity-sensitiveness is achieved by adaptive negative pair weighting. Furthermore, two branches are designed in CODER. One learns instance-level embeddings from image/text, and it also generates pseudo online clustering labels for its input image/text based on their embeddings. Meanwhile, the other branch learns to query from commonsense knowledge graph to form concept-level descriptors for both modalities. Afterwards, both branches leverage DCL to align the cross-modal embedding spaces while an extra pseudo clustering label prediction loss is utilized to promote concept-level representation learning for the second branch. Extensive experiments conducted on two popular benchmarks, i.e. MSCOCO and Flicker30K, validate CODER remarkably outperforms the state-of-the-art approaches.
NSNet: Non-saliency Suppression Sampler for Efficient Video Recognition
Jul 21, 2022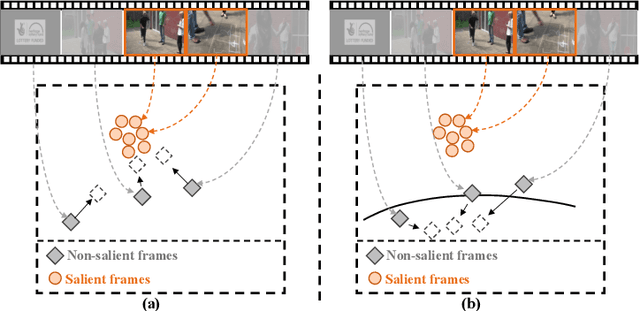
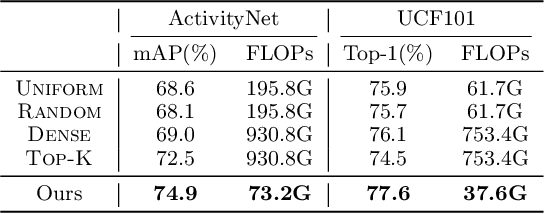

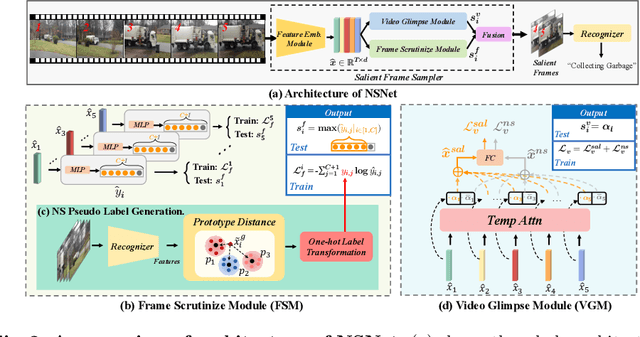
It is challenging for artificial intelligence systems to achieve accurate video recognition under the scenario of low computation costs. Adaptive inference based efficient video recognition methods typically preview videos and focus on salient parts to reduce computation costs. Most existing works focus on complex networks learning with video classification based objectives. Taking all frames as positive samples, few of them pay attention to the discrimination between positive samples (salient frames) and negative samples (non-salient frames) in supervisions. To fill this gap, in this paper, we propose a novel Non-saliency Suppression Network (NSNet), which effectively suppresses the responses of non-salient frames. Specifically, on the frame level, effective pseudo labels that can distinguish between salient and non-salient frames are generated to guide the frame saliency learning. On the video level, a temporal attention module is learned under dual video-level supervisions on both the salient and the non-salient representations. Saliency measurements from both two levels are combined for exploitation of multi-granularity complementary information. Extensive experiments conducted on four well-known benchmarks verify our NSNet not only achieves the state-of-the-art accuracy-efficiency trade-off but also present a significantly faster (2.4~4.3x) practical inference speed than state-of-the-art methods. Our project page is at https://lawrencexia2008.github.io/projects/nsnet .
Temporal Saliency Query Network for Efficient Video Recognition
Jul 21, 2022
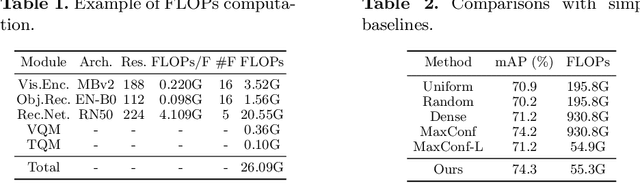
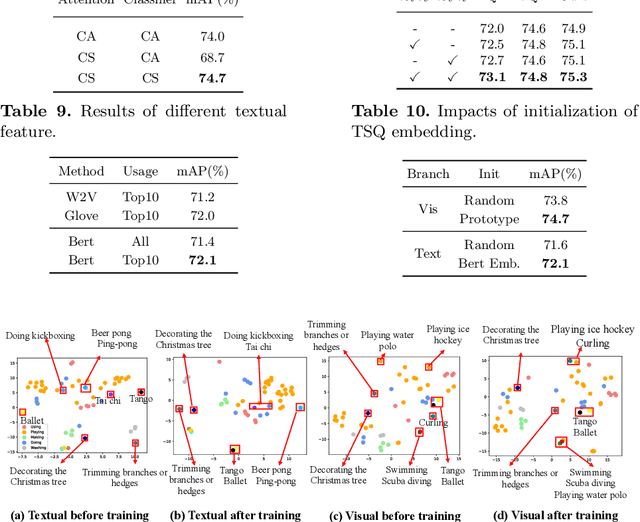
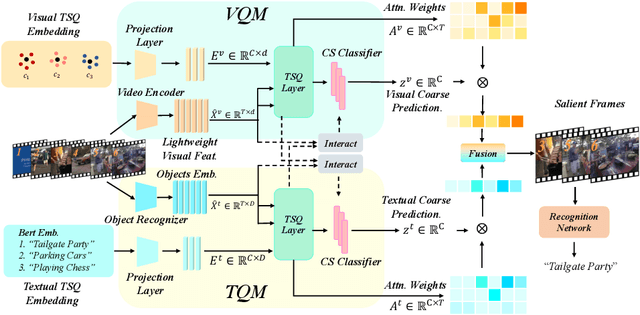
Efficient video recognition is a hot-spot research topic with the explosive growth of multimedia data on the Internet and mobile devices. Most existing methods select the salient frames without awareness of the class-specific saliency scores, which neglect the implicit association between the saliency of frames and its belonging category. To alleviate this issue, we devise a novel Temporal Saliency Query (TSQ) mechanism, which introduces class-specific information to provide fine-grained cues for saliency measurement. Specifically, we model the class-specific saliency measuring process as a query-response task. For each category, the common pattern of it is employed as a query and the most salient frames are responded to it. Then, the calculated similarities are adopted as the frame saliency scores. To achieve it, we propose a Temporal Saliency Query Network (TSQNet) that includes two instantiations of the TSQ mechanism based on visual appearance similarities and textual event-object relations. Afterward, cross-modality interactions are imposed to promote the information exchange between them. Finally, we use the class-specific saliencies of the most confident categories generated by two modalities to perform the selection of salient frames. Extensive experiments demonstrate the effectiveness of our method by achieving state-of-the-art results on ActivityNet, FCVID and Mini-Kinetics datasets. Our project page is at https://lawrencexia2008.github.io/projects/tsqnet .