 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnrolled Decomposed Unpaired Learning for Controllable Low-Light Video Enhancement
Aug 22, 2024



Obtaining pairs of low/normal-light videos, with motions, is more challenging than still images, which raises technical issues and poses the technical route of unpaired learning as a critical role. This paper makes endeavors in the direction of learning for low-light video enhancement without using paired ground truth. Compared to low-light image enhancement, enhancing low-light videos is more difficult due to the intertwined effects of noise, exposure, and contrast in the spatial domain, jointly with the need for temporal coherence. To address the above challenge, we propose the Unrolled Decomposed Unpaired Network (UDU-Net) for enhancing low-light videos by unrolling the optimization functions into a deep network to decompose the signal into spatial and temporal-related factors, which are updated iteratively. Firstly, we formulate low-light video enhancement as a Maximum A Posteriori estimation (MAP) problem with carefully designed spatial and temporal visual regularization. Then, via unrolling the problem, the optimization of the spatial and temporal constraints can be decomposed into different steps and updated in a stage-wise manner. From the spatial perspective, the designed Intra subnet leverages unpair prior information from expert photography retouched skills to adjust the statistical distribution. Additionally, we introduce a novel mechanism that integrates human perception feedback to guide network optimization, suppressing over/under-exposure conditions. Meanwhile, to address the issue from the temporal perspective, the designed Inter subnet fully exploits temporal cues in progressive optimization, which helps achieve improved temporal consistency in enhancement results. Consequently, the proposed method achieves superior performance to state-of-the-art methods in video illumination, noise suppression, and temporal consistency across outdoor and indoor scenes.
Unlearnable Examples Detection via Iterative Filtering
Aug 15, 2024



Deep neural networks are proven to be vulnerable to data poisoning attacks. Recently, a specific type of data poisoning attack known as availability attacks has led to the failure of data utilization for model learning by adding imperceptible perturbations to images. Consequently, it is quite beneficial and challenging to detect poisoned samples, also known as Unlearnable Examples (UEs), from a mixed dataset. In response, we propose an Iterative Filtering approach for UEs identification. This method leverages the distinction between the inherent semantic mapping rules and shortcuts, without the need for any additional information. We verify that when training a classifier on a mixed dataset containing both UEs and clean data, the model tends to quickly adapt to the UEs compared to the clean data. Due to the accuracy gaps between training with clean/poisoned samples, we employ a model to misclassify clean samples while correctly identifying the poisoned ones. The incorporation of additional classes and iterative refinement enhances the model's ability to differentiate between clean and poisoned samples. Extensive experiments demonstrate the superiority of our method over state-of-the-art detection approaches across various attacks, datasets, and poison ratios, significantly reducing the Half Total Error Rate (HTER) compared to existing methods.
Large Models for Aerial Edges: An Edge-Cloud Model Evolution and Communication Paradigm
Aug 09, 2024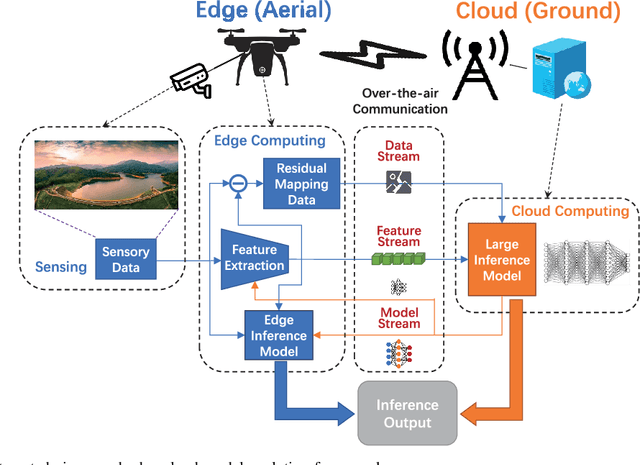
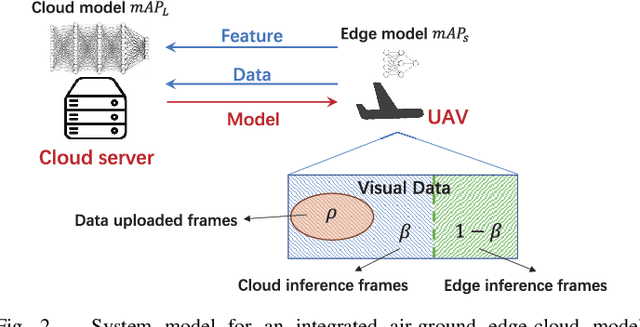
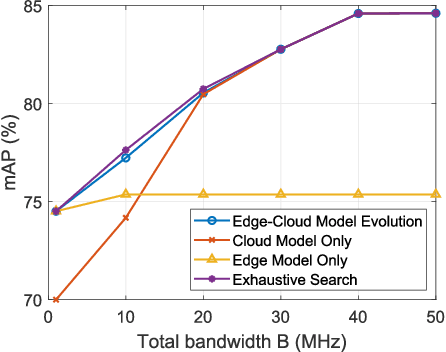
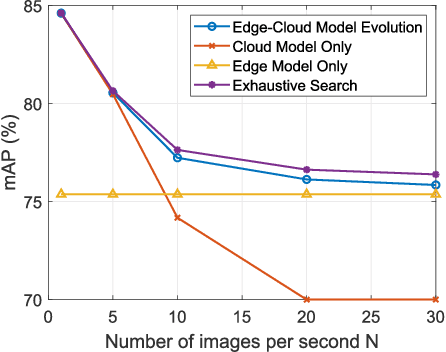
The future sixth-generation (6G) of wireless networks is expected to surpass its predecessors by offering ubiquitous coverage through integrated air-ground facility deployments in both communication and computing domains. In this network, aerial facilities, such as unmanned aerial vehicles (UAVs), conduct artificial intelligence (AI) computations based on multi-modal data to support diverse applications including surveillance and environment construction. However, these multi-domain inference and content generation tasks require large AI models, demanding powerful computing capabilities, thus posing significant challenges for UAVs. To tackle this problem, we propose an integrated edge-cloud model evolution framework, where UAVs serve as edge nodes for data collection and edge model computation. Through wireless channels, UAVs collaborate with ground cloud servers, providing cloud model computation and model updating for edge UAVs. With limited wireless communication bandwidth, the proposed framework faces the challenge of information exchange scheduling between the edge UAVs and the cloud server. To tackle this, we present joint task allocation, transmission resource allocation, transmission data quantization design, and edge model update design to enhance the inference accuracy of the integrated air-ground edge-cloud model evolution framework by mean average precision (mAP) maximization. A closed-form lower bound on the mAP of the proposed framework is derived, and the solution to the mAP maximization problem is optimized accordingly. Simulations, based on results from vision-based classification experiments, consistently demonstrate that the mAP of the proposed framework outperforms both a centralized cloud model framework and a distributed edge model framework across various communication bandwidths and data sizes.
Memory-efficient Training of LLMs with Larger Mini-batches
Jul 28, 2024



Training with larger mini-batches improves the performance and convergence rate of training machine learning models. However, training with large mini-batches becomes prohibitive for Large Language Models (LLMs) with billions of parameters, due to the large GPU memory requirement. To address this problem, we propose finding small mini-batches that simulate the dynamics of training with larger mini-batches. Specifically, we formulate selecting smaller mini-batches of examples that closely capture gradients of large mini-batches as a submodular maximization problem. Nevertheless, the very large dimensionality of the gradients makes the problem very challenging to solve. To address this, we leverage ideas from zeroth-order optimization and neural network pruning to find lower-dimensional gradient estimates that allow finding high-quality subsets effectively with a limited amount of memory. We prove the superior convergence rate of training on the small mini-batches found by our method and empirically show its effectiveness. Our method can effectively reduce the memory requirement by 2x and speed up training by 1.3x, as we confirm for fine-tuning Phi-2 on MathInstruct. Our method can be easily stacked with LoRA and other memory-efficient methods to further reduce the memory requirements of training LLMs.
Single-Image Shadow Removal Using Deep Learning: A Comprehensive Survey
Jul 11, 2024



Shadow removal aims at restoring the image content within shadow regions, pursuing a uniform distribution of illumination that is consistent between shadow and non-shadow regions. {Comparing to other image restoration tasks, there are two unique challenges in shadow removal:} 1) The patterns of shadows are arbitrary, varied, and often have highly complex trace structures, making ``trace-less'' image recovery difficult. 2) The degradation caused by shadows is spatially non-uniform, resulting in inconsistencies in illumination and color between shadow and non-shadow areas. Recent developments in this field are primarily driven by deep learning-based solutions, employing a variety of learning strategies, network architectures, loss functions, and training data. Nevertheless, a thorough and insightful review of deep learning-based shadow removal techniques is still lacking. In this paper, we are the first to provide a comprehensive survey to cover various aspects ranging from technical details to applications. We highlight the major advancements in deep learning-based single-image shadow removal methods, thoroughly review previous research across various categories, and provide insights into the historical progression of these developments. Additionally, we summarize performance comparisons both quantitatively and qualitatively. Beyond the technical aspects of shadow removal methods, we also explore potential future directions for this field.
Coding for Intelligence from the Perspective of Category
Jul 02, 2024



Coding, which targets compressing and reconstructing data, and intelligence, often regarded at an abstract computational level as being centered around model learning and prediction, interweave recently to give birth to a series of significant progress. The recent trends demonstrate the potential homogeneity of these two fields, especially when deep-learning models aid these two categories for better probability modeling. For better understanding and describing from a unified perspective, inspired by the basic generally recognized principles in cognitive psychology, we formulate a novel problem of Coding for Intelligence from the category theory view. Based on the three axioms: existence of ideal coding, existence of practical coding, and compactness promoting generalization, we derive a general framework to understand existing methodologies, namely that, coding captures the intrinsic relationships of objects as much as possible, while ignoring information irrelevant to downstream tasks. This framework helps identify the challenges and essential elements in solving the specific derived Minimal Description Length (MDL) optimization problem from a broader range, providing opportunities to build a more intelligent system for handling multiple tasks/applications with coding ideas/tools. Centering on those elements, we systematically review recent processes of towards optimizing the MDL problem in more comprehensive ways from data, model, and task perspectives, and reveal their impacts on the potential CfI technical routes. After that, we also present new technique paths to fulfill CfI and provide potential solutions with preliminary experimental evidence. Last, further directions and remaining issues are discussed as well. The discussion shows our theory can reveal many phenomena and insights about large foundation models, which mutually corroborate with recent practices in feature learning.
DDR: Exploiting Deep Degradation Response as Flexible Image Descriptor
Jun 12, 2024



Image deep features extracted by pre-trained networks are known to contain rich and informative representations. In this paper, we present Deep Degradation Response (DDR), a method to quantify changes in image deep features under varying degradation conditions. Specifically, our approach facilitates flexible and adaptive degradation, enabling the controlled synthesis of image degradation through text-driven prompts. Extensive evaluations demonstrate the versatility of DDR as an image descriptor, with strong correlations observed with key image attributes such as complexity, colorfulness, sharpness, and overall quality. Moreover, we demonstrate the efficacy of DDR across a spectrum of applications. It excels as a blind image quality assessment metric, outperforming existing methodologies across multiple datasets. Additionally, DDR serves as an effective unsupervised learning objective in image restoration tasks, yielding notable advancements in image deblurring and single-image super-resolution. Our code will be made available.
DP-IQA: Utilizing Diffusion Prior for Blind Image Quality Assessment in the Wild
Jun 03, 2024



Image quality assessment (IQA) plays a critical role in selecting high-quality images and guiding compression and enhancement methods in a series of applications. The blind IQA, which assesses the quality of in-the-wild images containing complex authentic distortions without reference images, poses greater challenges. Existing methods are limited to modeling a uniform distribution with local patches and are bothered by the gap between low and high-level visions (caused by widely adopted pre-trained classification networks). In this paper, we propose a novel IQA method called diffusion priors-based IQA (DP-IQA), which leverages the prior knowledge from the pre-trained diffusion model with its excellent powers to bridge semantic gaps in the perception of the visual quality of images. Specifically, we use pre-trained stable diffusion as the backbone, extract multi-level features from the denoising U-Net during the upsampling process at a specified timestep, and decode them to estimate the image quality score. The text and image adapters are adopted to mitigate the domain gap for downstream tasks and correct the information loss caused by the variational autoencoder bottleneck. Finally, we distill the knowledge in the above model into a CNN-based student model, significantly reducing the parameter to enhance applicability, with the student model performing similarly or even better than the teacher model surprisingly. Experimental results demonstrate that our DP-IQA achieves state-of-the-art results on various in-the-wild datasets with better generalization capability, which shows the superiority of our method in global modeling and utilizing the hierarchical feature clues of diffusion for evaluating image quality.
ContextGS: Compact 3D Gaussian Splatting with Anchor Level Context Model
May 31, 2024Recently, 3D Gaussian Splatting (3DGS) has become a promising framework for novel view synthesis, offering fast rendering speeds and high fidelity. However, the large number of Gaussians and their associated attributes require effective compression techniques. Existing methods primarily compress neural Gaussians individually and independently, i.e., coding all the neural Gaussians at the same time, with little design for their interactions and spatial dependence. Inspired by the effectiveness of the context model in image compression, we propose the first autoregressive model at the anchor level for 3DGS compression in this work. We divide anchors into different levels and the anchors that are not coded yet can be predicted based on the already coded ones in all the coarser levels, leading to more accurate modeling and higher coding efficiency. To further improve the efficiency of entropy coding, e.g., to code the coarsest level with no already coded anchors, we propose to introduce a low-dimensional quantized feature as the hyperprior for each anchor, which can be effectively compressed. Our work pioneers the context model in the anchor level for 3DGS representation, yielding an impressive size reduction of over 100 times compared to vanilla 3DGS and 15 times compared to the most recent state-of-the-art work Scaffold-GS, while achieving comparable or even higher rendering quality.
Opinion-Unaware Blind Image Quality Assessment using Multi-Scale Deep Feature Statistics
May 29, 2024



Deep learning-based methods have significantly influenced the blind image quality assessment (BIQA) field, however, these methods often require training using large amounts of human rating data. In contrast, traditional knowledge-based methods are cost-effective for training but face challenges in effectively extracting features aligned with human visual perception. To bridge these gaps, we propose integrating deep features from pre-trained visual models with a statistical analysis model into a Multi-scale Deep Feature Statistics (MDFS) model for achieving opinion-unaware BIQA (OU-BIQA), thereby eliminating the reliance on human rating data and significantly improving training efficiency. Specifically, we extract patch-wise multi-scale features from pre-trained vision models, which are subsequently fitted into a multivariate Gaussian (MVG) model. The final quality score is determined by quantifying the distance between the MVG model derived from the test image and the benchmark MVG model derived from the high-quality image set. A comprehensive series of experiments conducted on various datasets show that our proposed model exhibits superior consistency with human visual perception compared to state-of-the-art BIQA models. Furthermore, it shows improved generalizability across diverse target-specific BIQA tasks. Our code is available at: https://github.com/eezkni/MDFS