 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Jun 18, 2024



We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3) matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as measured by AlignBench. The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) touse -- including web browser, Python interpreter, text-to-image model, and user-defined functions -- to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter. Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone. The open models can be accessed through https://github.com/THUDM and https://huggingface.co/THUDM.
OAG-Bench: A Human-Curated Benchmark for Academic Graph Mining
Feb 24, 2024



With the rapid proliferation of scientific literature, versatile academic knowledge services increasingly rely on comprehensive academic graph mining. Despite the availability of public academic graphs, benchmarks, and datasets, these resources often fall short in multi-aspect and fine-grained annotations, are constrained to specific task types and domains, or lack underlying real academic graphs. In this paper, we present OAG-Bench, a comprehensive, multi-aspect, and fine-grained human-curated benchmark based on the Open Academic Graph (OAG). OAG-Bench covers 10 tasks, 20 datasets, 70+ baselines, and 120+ experimental results to date. We propose new data annotation strategies for certain tasks and offer a suite of data pre-processing codes, algorithm implementations, and standardized evaluation protocols to facilitate academic graph mining. Extensive experiments reveal that even advanced algorithms like large language models (LLMs) encounter difficulties in addressing key challenges in certain tasks, such as paper source tracing and scholar profiling. We also introduce the Open Academic Graph Challenge (OAG-Challenge) to encourage community input and sharing. We envisage that OAG-Bench can serve as a common ground for the community to evaluate and compare algorithms in academic graph mining, thereby accelerating algorithm development and advancement in this field. OAG-Bench is accessible at https://www.aminer.cn/data/.
AlignBench: Benchmarking Chinese Alignment of Large Language Models
Dec 05, 2023



Alignment has become a critical step for instruction-tuned Large Language Models (LLMs) to become helpful assistants. However, effective evaluation of alignment for emerging Chinese LLMs is still significantly lacking, calling for real-scenario grounded, open-ended, challenging and automatic evaluations tailored for alignment. To fill in this gap, we introduce AlignBench, a comprehensive multi-dimensional benchmark for evaluating LLMs' alignment in Chinese. Equipped with a human-in-the-loop data curation pipeline, our benchmark employs a rule-calibrated multi-dimensional LLM-as-Judge with Chain-of-Thought to generate explanations and final ratings as evaluations, ensuring high reliability and interpretability. Furthermore, we report AlignBench evaluated by CritiqueLLM, a dedicated Chinese evaluator LLM that recovers 95% of GPT-4's evaluation ability. We will provide public APIs for evaluating AlignBench with CritiqueLLM to facilitate the evaluation of LLMs' Chinese alignment. All evaluation codes, data, and LLM generations are available at \url{https://github.com/THUDM/AlignBench}.
Are Intermediate Layers and Labels Really Necessary? A General Language Model Distillation Method
Jun 11, 2023



The large scale of pre-trained language models poses a challenge for their deployment on various devices, with a growing emphasis on methods to compress these models, particularly knowledge distillation. However, current knowledge distillation methods rely on the model's intermediate layer features and the golden labels (also called hard labels), which usually require aligned model architecture and enough labeled data respectively. Moreover, the parameters of vocabulary are usually neglected in existing methods. To address these problems, we propose a general language model distillation (GLMD) method that performs two-stage word prediction distillation and vocabulary compression, which is simple and surprisingly shows extremely strong performance. Specifically, GLMD supports more general application scenarios by eliminating the constraints of dimension and structure between models and the need for labeled datasets through the absence of intermediate layers and golden labels. Meanwhile, based on the long-tailed distribution of word frequencies in the data, GLMD designs a strategy of vocabulary compression through decreasing vocabulary size instead of dimensionality. Experimental results show that our method outperforms 25 state-of-the-art methods on the SuperGLUE benchmark, achieving an average score that surpasses the best method by 3%.
GKD: A General Knowledge Distillation Framework for Large-scale Pre-trained Language Model
Jun 11, 2023



Currently, the reduction in the parameter scale of large-scale pre-trained language models (PLMs) through knowledge distillation has greatly facilitated their widespread deployment on various devices. However, the deployment of knowledge distillation systems faces great challenges in real-world industrial-strength applications, which require the use of complex distillation methods on even larger-scale PLMs (over 10B), limited by memory on GPUs and the switching of methods. To overcome these challenges, we propose GKD, a general knowledge distillation framework that supports distillation on larger-scale PLMs using various distillation methods. With GKD, developers can build larger distillation models on memory-limited GPUs and easily switch and combine different distillation methods within a single framework. Experimental results show that GKD can support the distillation of at least 100B-scale PLMs and 25 mainstream methods on 8 NVIDIA A100 (40GB) GPUs.
GLM-130B: An Open Bilingual Pre-trained Model
Oct 05, 2022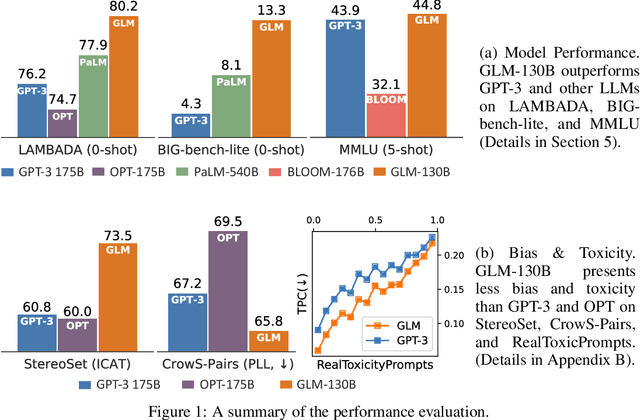
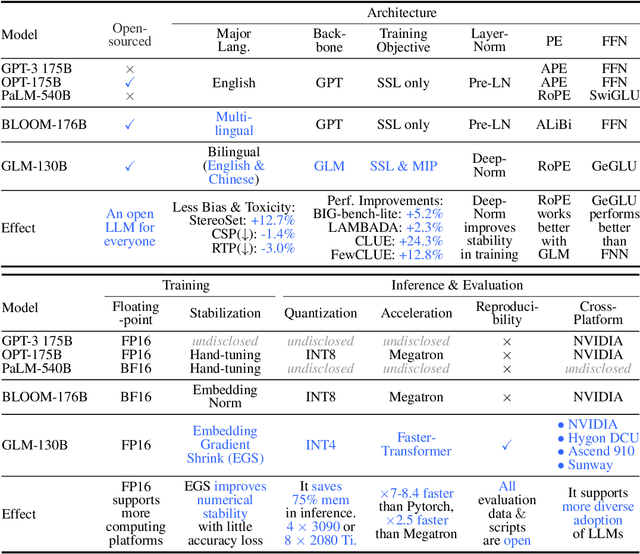

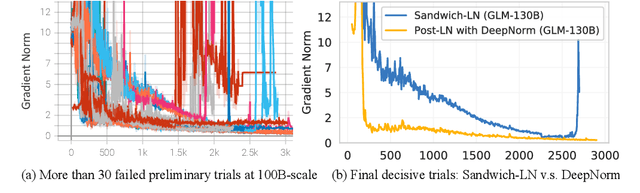
We introduce GLM-130B, a bilingual (English and Chinese) pre-trained language model with 130 billion parameters. It is an attempt to open-source a 100B-scale model at least as good as GPT-3 and unveil how models of such a scale can be successfully pre-trained. Over the course of this effort, we face numerous unexpected technical and engineering challenges, particularly on loss spikes and disconvergence. In this paper, we introduce the training process of GLM-130B including its design choices, training strategies for both efficiency and stability, and engineering efforts. The resultant GLM-130B model offers significant outperformance over GPT-3 175B on a wide range of popular English benchmarks while the performance advantage is not observed in OPT-175B and BLOOM-176B. It also consistently and significantly outperforms ERNIE TITAN 3.0 260B -- the largest Chinese language model -- across related benchmarks. Finally, we leverage a unique scaling property of GLM-130B to reach INT4 quantization, without quantization aware training and with almost no performance loss, making it the first among 100B-scale models. More importantly, the property allows its effective inference on 4$\times$RTX 3090 (24G) or 8$\times$RTX 2080 Ti (11G) GPUs, the most ever affordable GPUs required for using 100B-scale models. The GLM-130B model weights are publicly accessible and its code, training logs, related toolkit, and lessons learned are open-sourced at https://github.com/THUDM/GLM-130B .
Parameter-Efficient Prompt Tuning Makes Generalized and Calibrated Neural Text Retrievers
Jul 14, 2022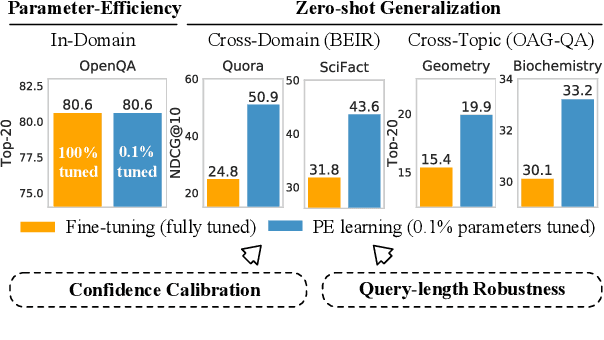
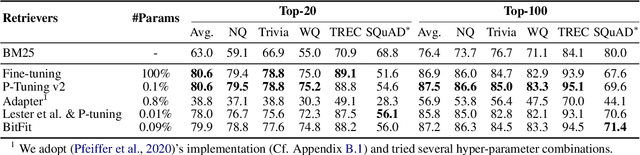
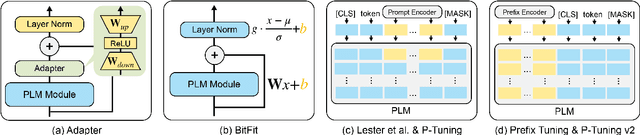

Prompt tuning attempts to update few task-specific parameters in pre-trained models. It has achieved comparable performance to fine-tuning of the full parameter set on both language understanding and generation tasks. In this work, we study the problem of prompt tuning for neural text retrievers. We introduce parameter-efficient prompt tuning for text retrieval across in-domain, cross-domain, and cross-topic settings. Through an extensive analysis, we show that the strategy can mitigate the two issues -- parameter-inefficiency and weak generalizability -- faced by fine-tuning based retrieval methods. Notably, it can significantly improve the out-of-domain zero-shot generalization of the retrieval models. By updating only 0.1% of the model parameters, the prompt tuning strategy can help retrieval models achieve better generalization performance than traditional methods in which all parameters are updated. Finally, to facilitate research on retrievers' cross-topic generalizability, we curate and release an academic retrieval dataset with 18K query-results pairs in 87 topics, making it the largest topic-specific one to date.