 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutlier-Robust Diffusion Solvers for Inverse Problems
May 10, 2026Methods based on diffusion models (DMs) for solving inverse problems (IPs) have recently achieved remarkable performance. However, DM-based methods typically struggle against outliers, which are common in real-world measurements. In this work, to tackle IPs with outliers, we first refine the measurement via explicit noise estimation to mitigate the effect of noise. Subsequently, we formulate an iteratively reweighted least squares objective based on the Huber loss to address the outliers. We propose a method utilizing gradient descent to approximately solve the corresponding optimization problem for the robust objective. To avoid delicate tuning of the learning rate required by the gradient descent method, we further employ the conjugate gradient method with an efficient strategy for updating. Extensive experiments on multiple image datasets for linear and nonlinear tasks under various conditions demonstrate that our proposed methods exhibit robustness to outliers and outperform recent DM-based methods in most cases.
Fish Audio S2 Technical Report
Mar 11, 2026We introduce Fish Audio S2, an open-sourced text-to-speech system featuring multi-speaker, multi-turn generation, and, most importantly, instruction-following control via natural-language descriptions. To scale training, we develop a multi-stage training recipe together with a staged data pipeline covering video captioning and speech captioning, voice-quality assessment, and reward modeling. To push the frontier of open-source TTS, we release our model weights, fine-tuning code, and an SGLang-based inference engine. The inference engine is production-ready for streaming, achieving an RTF of 0.195 and a time-to-first-audio below 100 ms.Our code and weights are available on GitHub (https://github.com/fishaudio/fish-speech) and Hugging Face (https://huggingface.co/fishaudio/s2-pro). We highly encourage readers to visit https://fish.audio to try custom voices.
Parameter-Efficient Prompt Tuning Makes Generalized and Calibrated Neural Text Retrievers
Jul 14, 2022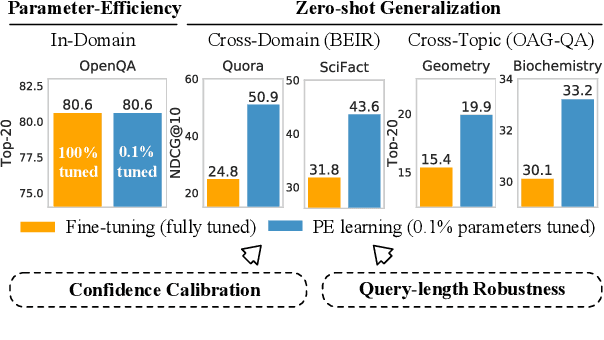
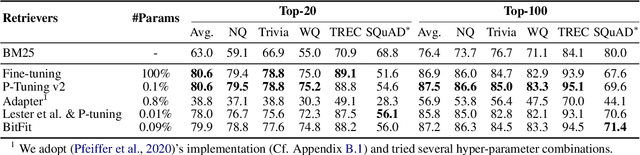
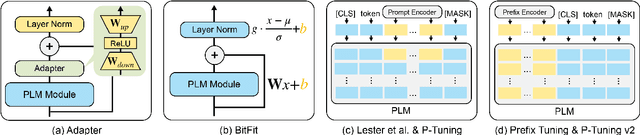

Prompt tuning attempts to update few task-specific parameters in pre-trained models. It has achieved comparable performance to fine-tuning of the full parameter set on both language understanding and generation tasks. In this work, we study the problem of prompt tuning for neural text retrievers. We introduce parameter-efficient prompt tuning for text retrieval across in-domain, cross-domain, and cross-topic settings. Through an extensive analysis, we show that the strategy can mitigate the two issues -- parameter-inefficiency and weak generalizability -- faced by fine-tuning based retrieval methods. Notably, it can significantly improve the out-of-domain zero-shot generalization of the retrieval models. By updating only 0.1% of the model parameters, the prompt tuning strategy can help retrieval models achieve better generalization performance than traditional methods in which all parameters are updated. Finally, to facilitate research on retrievers' cross-topic generalizability, we curate and release an academic retrieval dataset with 18K query-results pairs in 87 topics, making it the largest topic-specific one to date.