 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceSIR: A Multi-Agent Framework for Structured Analysis and Reporting of Agentic Execution Traces
Feb 28, 2026Agentic systems augment large language models with external tools and iterative decision making, enabling complex tasks such as deep research, function calling, and coding. However, their long and intricate execution traces make failure diagnosis and root cause analysis extremely challenging. Manual inspection does not scale, while directly applying LLMs to raw traces is hindered by input length limits and unreliable reasoning. Focusing solely on final task outcomes further discards critical behavioral information required for accurate issue localization. To address these issues, we propose TraceSIR, a multi-agent framework for structured analysis and reporting of agentic execution traces. TraceSIR coordinates three specialized agents: (1) StructureAgent, which introduces a novel abstraction format, TraceFormat, to compress execution traces while preserving essential behavioral information; (2) InsightAgent, which performs fine-grained diagnosis including issue localization, root cause analysis, and optimization suggestions; (3) ReportAgent, which aggregates insights across task instances and generates comprehensive analysis reports. To evaluate TraceSIR, we construct TraceBench, covering three real-world agentic scenarios, and introduce ReportEval, an evaluation protocol for assessing the quality and usability of analysis reports aligned with industry needs. Experiments show that TraceSIR consistently produces coherent, informative, and actionable reports, significantly outperforming existing approaches across all evaluation dimensions. Our project and video are publicly available at https://github.com/SHU-XUN/TraceSIR.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
AlignBench: Benchmarking Chinese Alignment of Large Language Models
Dec 05, 2023



Alignment has become a critical step for instruction-tuned Large Language Models (LLMs) to become helpful assistants. However, effective evaluation of alignment for emerging Chinese LLMs is still significantly lacking, calling for real-scenario grounded, open-ended, challenging and automatic evaluations tailored for alignment. To fill in this gap, we introduce AlignBench, a comprehensive multi-dimensional benchmark for evaluating LLMs' alignment in Chinese. Equipped with a human-in-the-loop data curation pipeline, our benchmark employs a rule-calibrated multi-dimensional LLM-as-Judge with Chain-of-Thought to generate explanations and final ratings as evaluations, ensuring high reliability and interpretability. Furthermore, we report AlignBench evaluated by CritiqueLLM, a dedicated Chinese evaluator LLM that recovers 95% of GPT-4's evaluation ability. We will provide public APIs for evaluating AlignBench with CritiqueLLM to facilitate the evaluation of LLMs' Chinese alignment. All evaluation codes, data, and LLM generations are available at \url{https://github.com/THUDM/AlignBench}.
CritiqueLLM: Scaling LLM-as-Critic for Effective and Explainable Evaluation of Large Language Model Generation
Nov 30, 2023Since the natural language processing (NLP) community started to make large language models (LLMs), such as GPT-4, act as a critic to evaluate the quality of generated texts, most of them only train a critique generation model of a specific scale on specific datasets. We argue that a comprehensive investigation on the key factor of LLM-based evaluation models, such as scaling properties, is lacking, so that it is still inconclusive whether these models have potential to replace GPT-4's evaluation in practical scenarios. In this paper, we propose a new critique generation model called CritiqueLLM, which includes a dialogue-based prompting method for high-quality referenced / reference-free evaluation data. Experimental results show that our model can achieve comparable evaluation performance to GPT-4 especially in system-level correlations, and even outperform GPT-4 in 3 out of 8 tasks in a challenging reference-free setting. We conduct detailed analysis to show promising scaling properties of our model in the quality of generated critiques. We also demonstrate that our generated critiques can act as scalable feedback to directly improve the generation quality of LLMs.
LOT: A Benchmark for Evaluating Chinese Long Text Understanding and Generation
Aug 30, 2021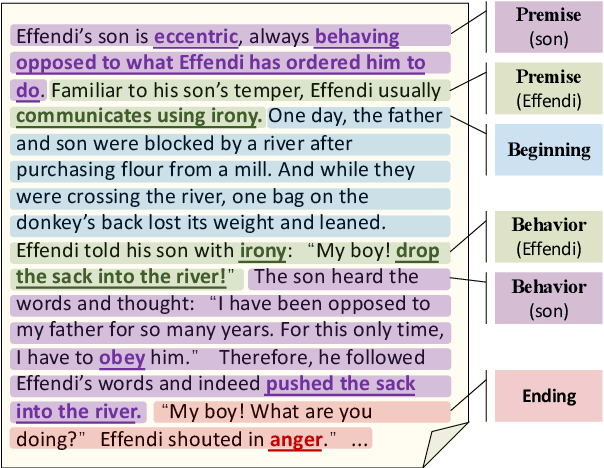

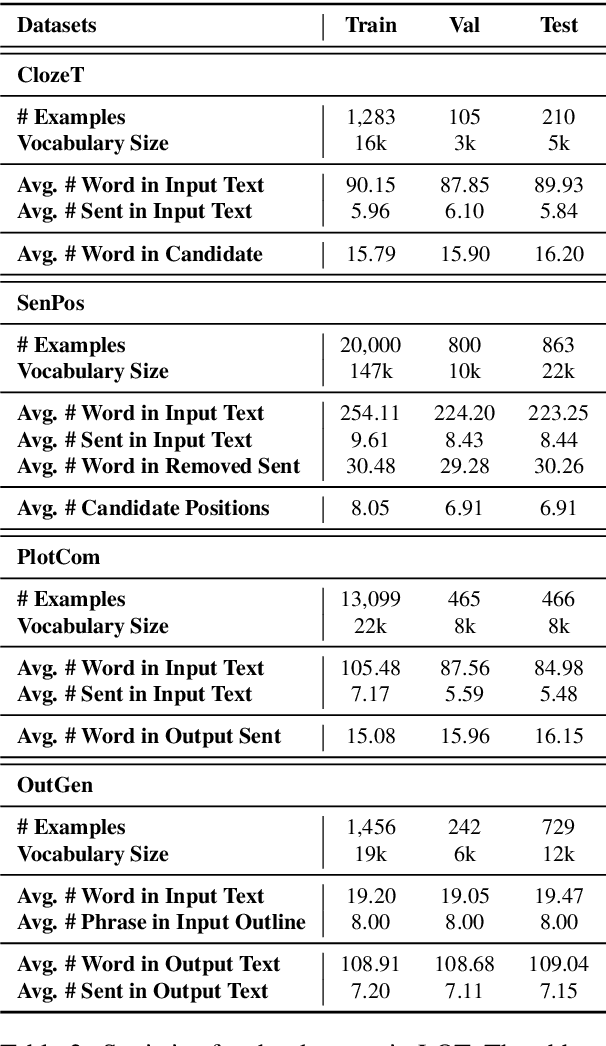

Standard multi-task benchmarks are essential for driving the progress of general pretraining models to generalize to various downstream tasks. However, existing benchmarks such as GLUE and GLGE tend to focus on short text understanding and generation tasks, without considering long text modeling, which requires many distinct capabilities such as modeling long-range commonsense and discourse relations, as well as the coherence and controllability of generation. The lack of standardized benchmarks makes it difficult to fully evaluate these capabilities of a model and fairly compare different models, especially Chinese pretraining models. Therefore, we propose LOT, a benchmark including two understanding and two generation tasks for Chinese long text modeling evaluation. We construct the datasets for the tasks based on various kinds of human-written Chinese stories. Besides, we release an encoder-decoder Chinese long text pretraining model named LongLM with up to 1 billion parameters. We pretrain LongLM on 120G Chinese novels with two generative tasks including text infilling and conditional continuation. Extensive experiments on LOT demonstrate that LongLM matches the performance of similar-sized pretraining models on the understanding tasks and outperforms strong baselines substantially on the generation tasks.
OpenMEVA: A Benchmark for Evaluating Open-ended Story Generation Metrics
May 19, 2021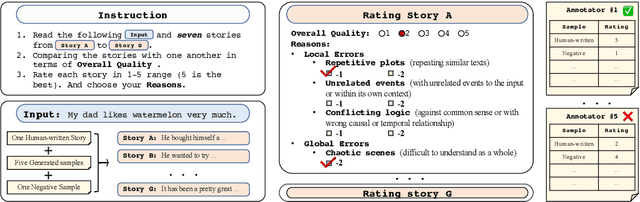
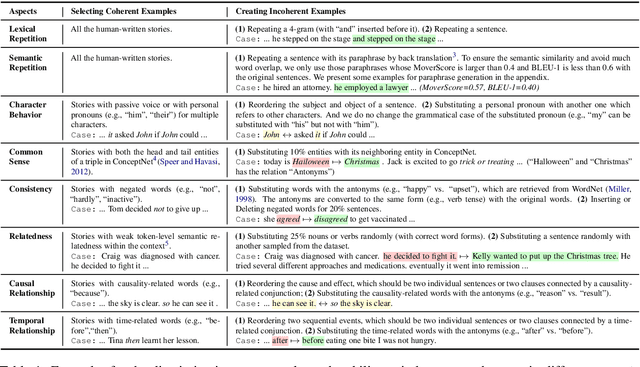
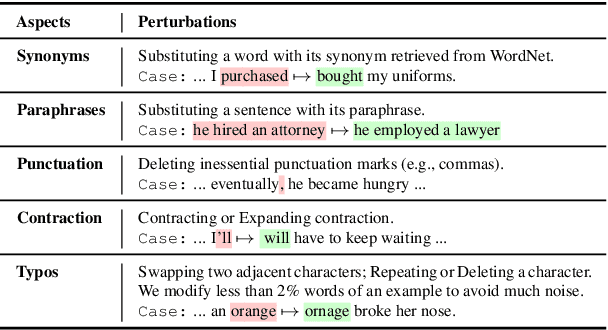
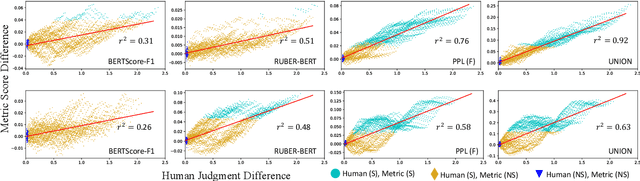
Automatic metrics are essential for developing natural language generation (NLG) models, particularly for open-ended language generation tasks such as story generation. However, existing automatic metrics are observed to correlate poorly with human evaluation. The lack of standardized benchmark datasets makes it difficult to fully evaluate the capabilities of a metric and fairly compare different metrics. Therefore, we propose OpenMEVA, a benchmark for evaluating open-ended story generation metrics. OpenMEVA provides a comprehensive test suite to assess the capabilities of metrics, including (a) the correlation with human judgments, (b) the generalization to different model outputs and datasets, (c) the ability to judge story coherence, and (d) the robustness to perturbations. To this end, OpenMEVA includes both manually annotated stories and auto-constructed test examples. We evaluate existing metrics on OpenMEVA and observe that they have poor correlation with human judgments, fail to recognize discourse-level incoherence, and lack inferential knowledge (e.g., causal order between events), the generalization ability and robustness. Our study presents insights for developing NLG models and metrics in further research.