 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbe Before You Edit: Probing-Guided Molecular Optimization for LLM Agents in Structure-Based Drug Design
May 30, 2026Structure-based drug design increasingly employs LLM agents to iteratively refine ligands against a target pocket, yet a viable ligand must satisfy two often-conflicting objectives -- binding affinity and druggability -- which single optimization steps rarely improve together. To quantify this difficulty, we introduce two diagnostic metrics: the first measures how often a single edit improves both objectives, and the second measures how often a gain on one objective comes with a loss on the other. Applying these diagnostics to current LLM-agent pipelines exposes a consistent failure mode: the agent performs molecular editing without knowing how the pocket-ligand complex responds to local modifications, thus rarely achieving joint improvement. Inspired by medicinal chemists, who probe the pocket-ligand complex with controlled analog edits before choosing an optimization direction, we propose \textbf{PROBE}, an optimization framework built around edit-response probing. PROBE first decomposes the ligand into editable sites and builds a pocket-specific \textbf{site map} that flags where joint gains are plausible, where the two objectives are likely in tension, and where liability substructures should be changed; it then performs controlled probe edits whose responses are distilled into an \textbf{EditManual}. Guided by the site map and EditManual, PROBE runs an iterative multi-agent loop in which an affinity agent, a druggability agent, and a co-optimization agent jointly produce edits. On the CrossDocked2020 benchmark, PROBE achieves state-of-the-art performance and substantially mitigates the failure modes exposed by our diagnostics metrics.
CausalVAE as a Plug-in for World Models: Towards Reliable Counterfactual Dynamics
Apr 09, 2026In this work, CausalVAE is introduced as a plug-in structural module for latent world models and is attached to diverse encoder-transition backbones. Across the reported benchmarks, competitive factual prediction is preserved and intervention-aware counterfactual retrieval is improved after the plug-in is added, suggesting stronger robustness under distribution shift and interventions. The largest gains are observed on the Physics benchmark: when averaged over 8 paired baselines, CF-H@1 is improved by +102.5%. In a representative GNN-NLL setting on Physics, CF-H@1 is increased from 11.0 to 41.0 (+272.7%). Through causal analysis, learned structural dependencies are shown to recover meaningful first-order physical interaction trends, supporting the interpretability of the learned latent causal structure.
Fluid-Antenna-aided AAV Secure Communications in Eavesdropper Uncertain Location
Sep 10, 2025For autonomous aerial vehicle (AAV) secure communications, traditional designs based on fixed position antenna (FPA) lack sufficient spatial degrees of freedom (DoF), which leaves the line-of-sight-dominated AAV links vulnerable to eavesdropping. To overcome this problem, this paper proposes a framework that effectively incorporates the fluid antenna (FA) and the artificial noise (AN) techniques. Specifically, the minimum secrecy rate (MSR) among multiple eavesdroppers is maximized by jointly optimizing AAV deployment, signal and AN precoders, and FA positions. In particular, the worst-case MSR is considered by taking the channel uncertainties due to the uncertainty about eavesdropping locations into account. To tackle the highly coupled optimization variables and the channel uncertainties in the formulated problem, an efficient and robust algorithm is proposed. Particularly, the uncertain regions of eavesdroppers, whose shapes can be arbitrary, are disposed by constructing convex hull. In addition, two movement modes of FAs are considered, namely, free movement mode and zonal movement mode, for which different optimization techniques are applied, respectively. Numerical results show that, the proposed FA schemes boost security by exploiting additional spatial DoF rather than transmit power, while AN provides remarkable gains under high transmit power. Furthermore, the synergy between FA and AN results in a secure advantage that exceeds the sum of their individual contributions, achieving a balance between security and reliability under limited resources.
Safe Delta: Consistently Preserving Safety when Fine-Tuning LLMs on Diverse Datasets
May 17, 2025Large language models (LLMs) have shown great potential as general-purpose AI assistants across various domains. To fully leverage this potential in specific applications, many companies provide fine-tuning API services, enabling users to upload their own data for LLM customization. However, fine-tuning services introduce a new safety threat: user-uploaded data, whether harmful or benign, can break the model's alignment, leading to unsafe outputs. Moreover, existing defense methods struggle to address the diversity of fine-tuning datasets (e.g., varying sizes, tasks), often sacrificing utility for safety or vice versa. To address this issue, we propose Safe Delta, a safety-aware post-training defense method that adjusts the delta parameters (i.e., the parameter change before and after fine-tuning). Specifically, Safe Delta estimates the safety degradation, selects delta parameters to maximize utility while limiting overall safety loss, and applies a safety compensation vector to mitigate residual safety loss. Through extensive experiments on four diverse datasets with varying settings, our approach consistently preserves safety while ensuring that the utility gain from benign datasets remains unaffected.
Gradient-Based Multi-Objective Deep Learning: Algorithms, Theories, Applications, and Beyond
Jan 19, 2025



Multi-objective optimization (MOO) in deep learning aims to simultaneously optimize multiple conflicting objectives, a challenge frequently encountered in areas like multi-task learning and multi-criteria learning. Recent advancements in gradient-based MOO methods have enabled the discovery of diverse types of solutions, ranging from a single balanced solution to finite or even infinite Pareto sets, tailored to user needs. These developments have broad applications across domains such as reinforcement learning, computer vision, recommendation systems, and large language models. This survey provides the first comprehensive review of gradient-based MOO in deep learning, covering algorithms, theories, and practical applications. By unifying various approaches and identifying critical challenges, it serves as a foundational resource for driving innovation in this evolving field. A comprehensive list of MOO algorithms in deep learning is available at \url{https://github.com/Baijiong-Lin/Awesome-Multi-Objective-Deep-Learning}.
Findings of the WMT 2024 Shared Task on Discourse-Level Literary Translation
Dec 16, 2024Following last year, we have continued to host the WMT translation shared task this year, the second edition of the Discourse-Level Literary Translation. We focus on three language directions: Chinese-English, Chinese-German, and Chinese-Russian, with the latter two ones newly added. This year, we totally received 10 submissions from 5 academia and industry teams. We employ both automatic and human evaluations to measure the performance of the submitted systems. The official ranking of the systems is based on the overall human judgments. We release data, system outputs, and leaderboard at https://www2.statmt.org/wmt24/literary-translation-task.html.
You Only Merge Once: Learning the Pareto Set of Preference-Aware Model Merging
Aug 22, 2024Model merging, which combines multiple models into a single model, has gained increasing popularity in recent years. By efficiently integrating the capabilities of various models without their original training data, this significantly reduces the parameter count and memory usage. However, current methods can only produce one single merged model. This necessitates a performance trade-off due to conflicts among the various models, and the resultant one-size-fits-all model may not align with the preferences of different users who may prioritize certain models over others. To address this issue, we propose preference-aware model merging, and formulate this as a multi-objective optimization problem in which the performance of the merged model on each base model's task is treated as an objective. In only one merging process, the proposed parameter-efficient structure can generate the whole Pareto set of merged models, each representing the Pareto-optimal model for a given user-specified preference. Merged models can also be selected from the learned Pareto set that are tailored to different user preferences. Experimental results on a number of benchmark datasets demonstrate that the proposed preference-aware Pareto Merging can obtain a diverse set of trade-off models and outperforms state-of-the-art model merging baselines.
Efficient Pareto Manifold Learning with Low-Rank Structure
Jul 30, 2024Multi-task learning, which optimizes performance across multiple tasks, is inherently a multi-objective optimization problem. Various algorithms are developed to provide discrete trade-off solutions on the Pareto front. Recently, continuous Pareto front approximations using a linear combination of base networks have emerged as a compelling strategy. However, it suffers from scalability issues when the number of tasks is large. To address this issue, we propose a novel approach that integrates a main network with several low-rank matrices to efficiently learn the Pareto manifold. It significantly reduces the number of parameters and facilitates the extraction of shared features. We also introduce orthogonal regularization to further bolster performance. Extensive experimental results demonstrate that the proposed approach outperforms state-of-the-art baselines, especially on datasets with a large number of tasks.
Findings of the WMT 2023 Shared Task on Discourse-Level Literary Translation: A Fresh Orb in the Cosmos of LLMs
Nov 06, 2023Translating literary works has perennially stood as an elusive dream in machine translation (MT), a journey steeped in intricate challenges. To foster progress in this domain, we hold a new shared task at WMT 2023, the first edition of the Discourse-Level Literary Translation. First, we (Tencent AI Lab and China Literature Ltd.) release a copyrighted and document-level Chinese-English web novel corpus. Furthermore, we put forth an industry-endorsed criteria to guide human evaluation process. This year, we totally received 14 submissions from 7 academia and industry teams. We employ both automatic and human evaluations to measure the performance of the submitted systems. The official ranking of the systems is based on the overall human judgments. In addition, our extensive analysis reveals a series of interesting findings on literary and discourse-aware MT. We release data, system outputs, and leaderboard at http://www2.statmt.org/wmt23/literary-translation-task.html.
HV-Net: Hypervolume Approximation based on DeepSets
Mar 04, 2022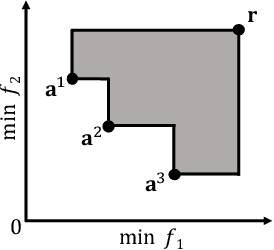
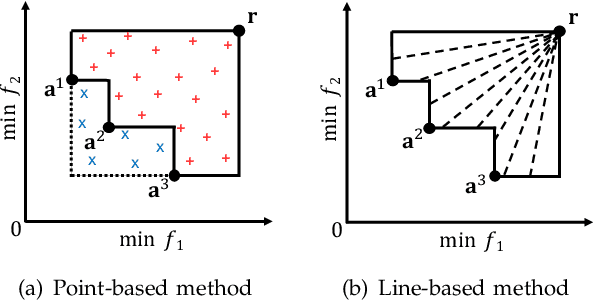
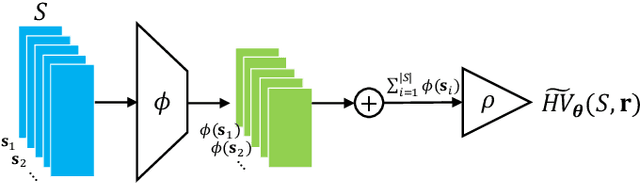
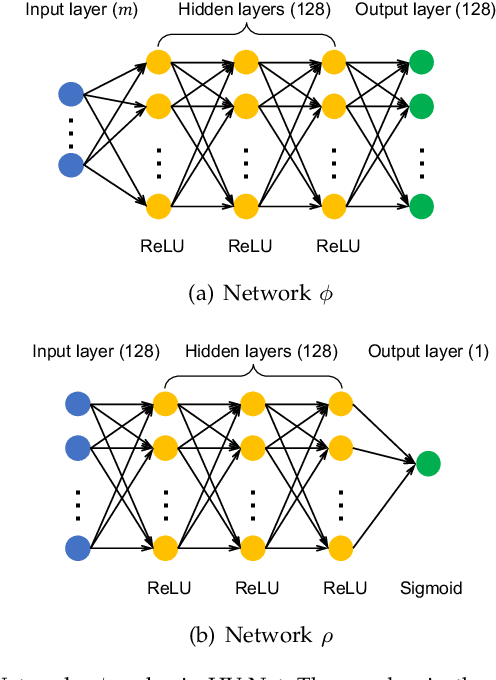
In this letter, we propose HV-Net, a new method for hypervolume approximation in evolutionary multi-objective optimization. The basic idea of HV-Net is to use DeepSets, a deep neural network with permutation invariant property, to approximate the hypervolume of a non-dominated solution set. The input of HV-Net is a non-dominated solution set in the objective space, and the output is an approximated hypervolume value of this solution set. The performance of HV-Net is evaluated through computational experiments by comparing it with two commonly-used hypervolume approximation methods (i.e., point-based method and line-based method). Our experimental results show that HV-Net outperforms the other two methods in terms of both the approximation error and the runtime, which shows the potential of using deep learning technique for hypervolume approximation.