 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Semantic Atomic Skills for Multi-Task Robotic Manipulation
Dec 20, 2025While imitation learning has shown impressive results in single-task robot manipulation, scaling it to multi-task settings remains a fundamental challenge due to issues such as suboptimal demonstrations, trajectory noise, and behavioral multi-modality. Existing skill-based methods attempt to address this by decomposing actions into reusable abstractions, but they often rely on fixed-length segmentation or environmental priors that limit semantic consistency and cross-task generalization. In this work, we propose AtomSkill, a novel multi-task imitation learning framework that learns and leverages a structured Atomic Skill Space for composable robot manipulation. Our approach is built on two key technical contributions. First, we construct a Semantically Grounded Atomic Skill Library by partitioning demonstrations into variable-length skills using gripper-state keyframe detection and vision-language model annotation. A contrastive learning objective ensures the resulting skill embeddings are both semantically consistent and temporally coherent. Second, we propose an Action Generation module with Keypose Imagination, which jointly predicts a skill's long-horizon terminal keypose and its immediate action sequence. This enables the policy to reason about overarching motion goals and fine-grained control simultaneously, facilitating robust skill chaining. Extensive experiments in simulated and real-world environments show that AtomSkill consistently outperforms state-of-the-art methods across diverse manipulation tasks.
Explain Before You Answer: A Survey on Compositional Visual Reasoning
Aug 24, 2025



Compositional visual reasoning has emerged as a key research frontier in multimodal AI, aiming to endow machines with the human-like ability to decompose visual scenes, ground intermediate concepts, and perform multi-step logical inference. While early surveys focus on monolithic vision-language models or general multimodal reasoning, a dedicated synthesis of the rapidly expanding compositional visual reasoning literature is still missing. We fill this gap with a comprehensive survey spanning 2023 to 2025 that systematically reviews 260+ papers from top venues (CVPR, ICCV, NeurIPS, ICML, ACL, etc.). We first formalize core definitions and describe why compositional approaches offer advantages in cognitive alignment, semantic fidelity, robustness, interpretability, and data efficiency. Next, we trace a five-stage paradigm shift: from prompt-enhanced language-centric pipelines, through tool-enhanced LLMs and tool-enhanced VLMs, to recently minted chain-of-thought reasoning and unified agentic VLMs, highlighting their architectural designs, strengths, and limitations. We then catalog 60+ benchmarks and corresponding metrics that probe compositional visual reasoning along dimensions such as grounding accuracy, chain-of-thought faithfulness, and high-resolution perception. Drawing on these analyses, we distill key insights, identify open challenges (e.g., limitations of LLM-based reasoning, hallucination, a bias toward deductive reasoning, scalable supervision, tool integration, and benchmark limitations), and outline future directions, including world-model integration, human-AI collaborative reasoning, and richer evaluation protocols. By offering a unified taxonomy, historical roadmap, and critical outlook, this survey aims to serve as a foundational reference and inspire the next generation of compositional visual reasoning research.
SPGISpeech 2.0: Transcribed multi-speaker financial audio for speaker-tagged transcription
Aug 07, 2025
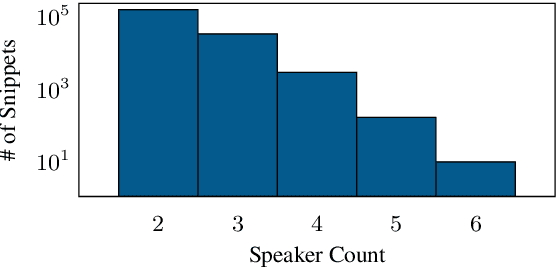
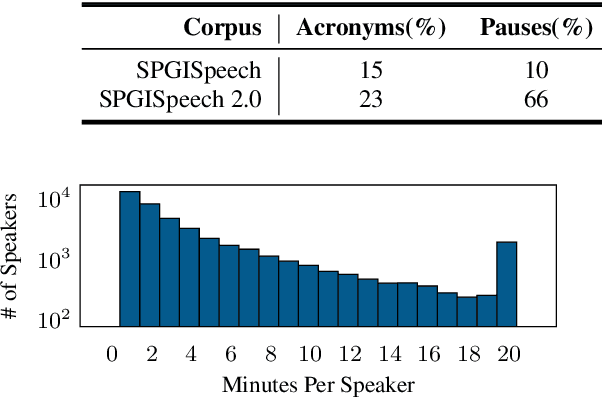
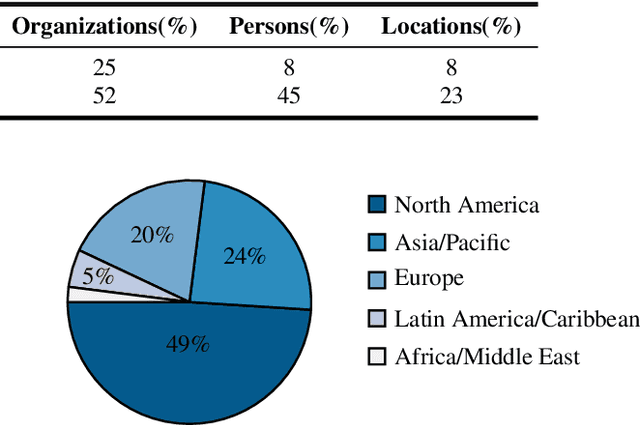
We introduce SPGISpeech 2.0, a dataset suitable for speaker-tagged transcription in the financial domain. SPGISpeech 2.0 improves the diversity of applicable modeling tasks while maintaining the core characteristic of the original SPGISpeech dataset: audio snippets and their corresponding fully formatted text transcriptions, usable for end-to-end automatic speech recognition (ASR). SPGISpeech 2.0 consists of 3,780 additional hours of professionally transcribed earnings calls. Furthermore, the dataset contains call and speaker information for each audio snippet facilitating multi-talker ASR. We validate the utility of SPGISpeech 2.0 through improvements in speaker-tagged ASR performance of popular speech recognition models after fine-tuning on SPGISpeech 2.0. Released free for non-commercial use, we expect SPGISpeech 2.0 to foster advancements in speech recognition technologies and inspire a wide range of research applications.
MoTime: A Dataset Suite for Multimodal Time Series Forecasting
May 21, 2025While multimodal data sources are increasingly available from real-world forecasting, most existing research remains on unimodal time series. In this work, we present MoTime, a suite of multimodal time series forecasting datasets that pair temporal signals with external modalities such as text, metadata, and images. Covering diverse domains, MoTime supports structured evaluation of modality utility under two scenarios: 1) the common forecasting task, where varying-length history is available, and 2) cold-start forecasting, where no historical data is available. Experiments show that external modalities can improve forecasting performance in both scenarios, with particularly strong benefits for short series in some datasets, though the impact varies depending on data characteristics. By making datasets and findings publicly available, we aim to support more comprehensive and realistic benchmarks in future multimodal time series forecasting research.
DWIM: Towards Tool-aware Visual Reasoning via Discrepancy-aware Workflow Generation & Instruct-Masking Tuning
Mar 25, 2025



Visual reasoning (VR), which is crucial in many fields for enabling human-like visual understanding, remains highly challenging. Recently, compositional visual reasoning approaches, which leverage the reasoning abilities of large language models (LLMs) with integrated tools to solve problems, have shown promise as more effective strategies than end-to-end VR methods. However, these approaches face limitations, as frozen LLMs lack tool awareness in VR, leading to performance bottlenecks. While leveraging LLMs for reasoning is widely used in other domains, they are not directly applicable to VR due to limited training data, imperfect tools that introduce errors and reduce data collection efficiency in VR, and challenging in fine-tuning on noisy workflows. To address these challenges, we propose DWIM: i) Discrepancy-aware training Workflow generation, which assesses tool usage and extracts more viable workflows for training; and ii) Instruct-Masking fine-tuning, which guides the model to only clone effective actions, enabling the generation of more practical solutions. Our experiments demonstrate that DWIM achieves state-of-the-art performance across various VR tasks, exhibiting strong generalization on multiple widely-used datasets.
Unveiling the Potential of Text in High-Dimensional Time Series Forecasting
Jan 13, 2025


Time series forecasting has traditionally focused on univariate and multivariate numerical data, often overlooking the benefits of incorporating multimodal information, particularly textual data. In this paper, we propose a novel framework that integrates time series models with Large Language Models to improve high-dimensional time series forecasting. Inspired by multimodal models, our method combines time series and textual data in the dual-tower structure. This fusion of information creates a comprehensive representation, which is then processed through a linear layer to generate the final forecast. Extensive experiments demonstrate that incorporating text enhances high-dimensional time series forecasting performance. This work paves the way for further research in multimodal time series forecasting.
Scalable and Effective Negative Sample Generation for Hyperedge Prediction
Nov 19, 2024



Hyperedge prediction is crucial in hypergraph analysis for understanding complex multi-entity interactions in various web-based applications, including social networks and e-commerce systems. Traditional methods often face difficulties in generating high-quality negative samples due to the imbalance between positive and negative instances. To address this, we present the Scalable and Effective Negative Sample Generation for Hyperedge Prediction (SEHP) framework, which utilizes diffusion models to tackle these challenges. SEHP employs a boundary-aware loss function that iteratively refines negative samples, moving them closer to decision boundaries to improve classification performance. SEHP samples positive instances to form sub-hypergraphs for scalable batch processing. By using structural information from sub-hypergraphs as conditions within the diffusion process, SEHP effectively captures global patterns. To enhance efficiency, our approach operates directly in latent space, avoiding the need for discrete ID generation and resulting in significant speed improvements while preserving accuracy. Extensive experiments show that SEHP outperforms existing methods in accuracy, efficiency, and scalability, representing a substantial advancement in hyperedge prediction techniques. Our code is available here.
How Does A Text Preprocessing Pipeline Affect Ontology Syntactic Matching?
Nov 06, 2024The generic text preprocessing pipeline, comprising Tokenisation, Normalisation, Stop Words Removal, and Stemming/Lemmatisation, has been implemented in many ontology matching (OM) systems. However, the lack of standardisation in text preprocessing creates diversity in mapping results. In this paper, we investigate the effect of the text preprocessing pipeline on OM tasks at syntactic levels. Our experiments on 8 Ontology Alignment Evaluation Initiative (OAEI) track repositories with 49 distinct alignments indicate: (1) Tokenisation and Normalisation are currently more effective than Stop Words Removal and Stemming/Lemmatisation; and (2) The selection of Lemmatisation and Stemming is task-specific. We recommend standalone Lemmatisation or Stemming with post-hoc corrections. We find that (3) Porter Stemmer and Snowball Stemmer perform better than Lancaster Stemmer; and that (4) Part-of-Speech (POS) Tagging does not help Lemmatisation. To repair less effective Stop Words Removal and Stemming/Lemmatisation used in OM tasks, we propose a novel context-based pipeline repair approach that significantly improves matching correctness and overall matching performance. We also discuss the use of text preprocessing pipeline in the new era of large language models (LLMs).
WPFed: Web-based Personalized Federation for Decentralized Systems
Oct 15, 2024



Decentralized learning has become crucial for collaborative model training in environments where data privacy and trust are paramount. In web-based applications, clients are liberated from traditional fixed network topologies, enabling the establishment of arbitrary peer-to-peer (P2P) connections. While this flexibility is highly promising, it introduces a fundamental challenge: the optimal selection of neighbors to ensure effective collaboration. To address this, we introduce WPFed, a fully decentralized, web-based learning framework designed to enable globally optimal neighbor selection. WPFed employs a dynamic communication graph and a weighted neighbor selection mechanism. By assessing inter-client similarity through Locality-Sensitive Hashing (LSH) and evaluating model quality based on peer rankings, WPFed enables clients to identify personalized optimal neighbors on a global scale while preserving data privacy. To enhance security and deter malicious behavior, WPFed integrates verification mechanisms for both LSH codes and performance rankings, leveraging blockchain-driven announcements to ensure transparency and verifiability. Through extensive experiments on multiple real-world datasets, we demonstrate that WPFed significantly improves learning outcomes and system robustness compared to traditional federated learning methods. Our findings highlight WPFed's potential to facilitate effective and secure decentralized collaborative learning across diverse and interconnected web environments.
Scalable Frame-based Construction of Sociocultural NormBases for Socially-Aware Dialogues
Oct 04, 2024



Sociocultural norms serve as guiding principles for personal conduct in social interactions, emphasizing respect, cooperation, and appropriate behavior, which is able to benefit tasks including conversational information retrieval, contextual information retrieval and retrieval-enhanced machine learning. We propose a scalable approach for constructing a Sociocultural Norm (SCN) Base using Large Language Models (LLMs) for socially aware dialogues. We construct a comprehensive and publicly accessible Chinese Sociocultural NormBase. Our approach utilizes socially aware dialogues, enriched with contextual frames, as the primary data source to constrain the generating process and reduce the hallucinations. This enables extracting of high-quality and nuanced natural-language norm statements, leveraging the pragmatic implications of utterances with respect to the situation. As real dialogue annotated with gold frames are not readily available, we propose using synthetic data. Our empirical results show: (i) the quality of the SCNs derived from synthetic data is comparable to that from real dialogues annotated with gold frames, and (ii) the quality of the SCNs extracted from real data, annotated with either silver (predicted) or gold frames, surpasses that without the frame annotations. We further show the effectiveness of the extracted SCNs in a RAG-based (Retrieval-Augmented Generation) model to reason about multiple downstream dialogue tasks.
* 17 pages