 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoGen: Can Past Experience Improve Future Text-to-Image Generation?
Jun 02, 2026Modern text-to-image models have achieved strong visual synthesis, yet remain unreliable when prompts require implicit visual constraints, relational reasoning, or external knowledge. Existing retrieval-augmented and agentic generation methods mitigate this issue by acquiring external knowledge, references, or refined prompts for the current request, yet they typically treat each generation as an isolated episode and do not systematically preserve past successes or failures for future use. In this work, we ask whether a text-to-image system can continually improve from its own generation experience without updating the underlying generator. We propose MemoGen, a training-free framework that augments existing image generators with an agentic evolution layer. For each task, MemoGen explicitly infers visual requirements, retrieves external evidence and references when necessary, translates them into executable generation constraints, evaluates the generated result, and stores task understanding, reference choices, visual feedback, successful strategies, and failure lessons as reusable experience memory. Across evolution rounds, the agent retrieves relevant experience to improve similar future generations, selectively repairing previously failed cases while preserving successful ones, thereby enabling test-time self-evolution without parameter updates. Extensive experiments on knowledge-intensive and reasoning-oriented benchmarks demonstrate the effectiveness of this paradigm: after only two evolution rounds, MemoGen built upon the open-source Qwen-Image backbone surpasses strong proprietary systems such as Nano Banana Pro and GPT-Image-1 on WISE and Mind-Bench, showing that explicit experience memory can serve as a powerful continual learning signal for reliable text-to-image generation.
Learning to Think in Physics: Breaking Shortcut Learning in Scientific Diffusion via Representation Alignment
May 20, 2026Physics-informed diffusion models typically enforce PDE constraints only on final outputs, leaving intermediate representations unconstrained and prone to shortcut learning under shifted boundary conditions. We introduce **REPA-P**, a teacher-free, architecture-agnostic framework that aligns intermediate features with physical states using first-principles residuals. REPA-P attaches lightweight $1{\times}1$ projection heads to selected layers, decodes hidden activations into physical quantities, and applies PDE residual losses during training. These heads are discarded at inference, introducing **zero overhead**. Across four PDE tasks, including Darcy flow, topology optimization, electrostatic potential, and turbulent channel flow, REPA-P accelerates convergence by up to $2{\times}$, reduces physics residuals by up to $66.4\%$, and improves out-of-distribution robustness by up to $49.3\%$, with consistent gains on both U-Net and Diffusion Transformer backbones. Ablations show that supervising a small set of intermediate layers captures most benefits and complements output-level physics losses. Code is available at [https://github.com/Hxxxz0/REPA-P](https://github.com/Hxxxz0/REPA-P).
Before the Body Moves: Learning Anticipatory Joint Intent for Language-Conditioned Humanoid Control
May 14, 2026Natural language is an intuitive interface for humanoid robots, yet streaming whole-body control requires control representations that are executable now and anticipatory of future physical transitions. Existing language-conditioned humanoid systems typically generate kinematic references that a low-level tracker must repair reactively, or use latent/action policies whose outputs do not explicitly encode upcoming contact changes, support transfers, and balance preparation. We propose \textbf{DAJI} (\emph{Dynamics-Aligned Joint Intent}), a hierarchical framework that learns an anticipatory joint-intent interface between language generation and closed-loop control. DAJI-Act distills a future-aware teacher into a deployable diffusion action policy through student-driven rollouts, while DAJI-Flow autoregressively generates future intent chunks from language and intent history. Experiments show that DAJI achieves strong results in anticipatory latent learning, single-instruction generation, and streaming instruction following, reaching 94.42\% rollout success on HumanML3D-style generation and 0.152 subsequence FID on BABEL.
$Z^2$-Sampling: Zero-Cost Zigzag Trajectories for Semantic Alignment in Diffusion Models
Apr 26, 2026Diffusion models have achieved unprecedented success in text-aligned generation, largely driven by Classifier-Free Guidance (CFG). However, standard CFG operates strictly on instantaneous gradients, omitting the intrinsic curvature of the data manifold. Recent methods like Zigzag-sampling (Z-Sampling) explicitly traverse multi-step forward-backward trajectories to probe this curvature, significantly improving semantic alignment. Yet, these explicit traversals triple the Neural Function Evaluation (NFE) cost and introduce unconstrained truncation errors from off-manifold evaluations, causing cumulative drift from the true marginal distribution. In this paper, we theoretically demonstrate that the explicit zigzag sequence is topologically reducible. We propose Implicit Z-Sampling, rigorously proving that intermediate states can be algebraically annihilated via operator dualities, physically eliminating off-manifold approximation errors. To push sampling efficiency to its theoretical lower bound, we introduce $Z^2$-Sampling (Zero-cost Zigzag Sampling). Exploiting the Probability Flow ODE's temporal coherence, $Z^2$-Sampling couples implicit algebraic collapse with a dynamically cached Temporal Semantic Surrogate. This restores the standard 2-NFE baseline without sacrificing semantic exploration. We formally prove via Backward Error Analysis that this discrete collapse inherently synthesizes a directional derivative curvature penalty. Finally, extensive evaluations demonstrate that $Z^2$-Sampling structurally shatters the performance-efficiency Pareto frontier. We validate its universal applicability across diverse architectures (U-Nets, DiTs) and modalities (image/video), establishing seamless orthogonality with advanced alignment frameworks (AYS, Diffusion-DPO).
Oracle Noise: Faster Semantic Spherical Alignment for Interpretable Latent Optimization
Apr 26, 2026Text-to-image diffusion models have achieved remarkable generative capabilities, yet accurately aligning complex textual prompts with synthesized layouts remains an ongoing challenge. In these models, the initial Gaussian noise acts as a critical structural seed dictating the macroscopic layout. Recent online optimization and search methods attempt to refine this noise to enhance text-image alignment. However, relying on unconstrained Euclidean gradient ascent mathematically inflates the latent norm and destroys the standard Gaussian prior, causing severe visual artifacts like color over-saturation. Furthermore, these methods suffer from inefficient semantic routing and easily fall into the ``reward hacking'' trap of external proxy models. To address these intertwined bottlenecks, we propose Oracle Noise, a zero-shot framework reframing noise initialization as semantic-driven optimization strictly confined to a Riemannian hypersphere. Instead of relying on complex external parsers, we directly identify the most impactful structural words in the prompt to efficiently route optimization energy. By updating the noise strictly along a spherical path, we mathematically preserve the original Gaussian distribution. This geometric constraint eliminates norm inflation and unlocks aggressive step sizes for rapid convergence. Extensive experiments demonstrate that Oracle Noise significantly accelerates semantic alignment and achieves superior aesthetics without black-box models. It completely mitigates Euclidean-induced degradation, establishing state-of-the-art performance across human preference metrics (e.g., HPSv2, ImageReward), semantic alignment (CLIP Score), and sample diversity, all within a strict 2-second optimization budget.
WaterVideoQA: ASV-Centric Perception and Rule-Compliant Reasoning via Multi-Modal Agents
Feb 26, 2026While autonomous navigation has achieved remarkable success in passive perception (e.g., object detection and segmentation), it remains fundamentally constrained by a void in knowledge-driven, interactive environmental cognition. In the high-stakes domain of maritime navigation, the ability to bridge the gap between raw visual perception and complex cognitive reasoning is not merely an enhancement but a critical prerequisite for Autonomous Surface Vessels to execute safe and precise maneuvers. To this end, we present WaterVideoQA, the first large-scale, comprehensive Video Question Answering benchmark specifically engineered for all-waterway environments. This benchmark encompasses 3,029 video clips across six distinct waterway categories, integrating multifaceted variables such as volatile lighting and dynamic weather to rigorously stress-test ASV capabilities across a five-tier hierarchical cognitive framework. Furthermore, we introduce NaviMind, a pioneering multi-agent neuro-symbolic system designed for open-ended maritime reasoning. By synergizing Adaptive Semantic Routing, Situation-Aware Hierarchical Reasoning, and Autonomous Self-Reflective Verification, NaviMind transitions ASVs from superficial pattern matching to regulation-compliant, interpretable decision-making. Experimental results demonstrate that our framework significantly transcends existing baselines, establishing a new paradigm for intelligent, trustworthy interaction in dynamic maritime environments.
Guided Path Sampling: Steering Diffusion Models Back on Track with Principled Path Guidance
Dec 28, 2025Iterative refinement methods based on a denoising-inversion cycle are powerful tools for enhancing the quality and control of diffusion models. However, their effectiveness is critically limited when combined with standard Classifier-Free Guidance (CFG). We identify a fundamental limitation: CFG's extrapolative nature systematically pushes the sampling path off the data manifold, causing the approximation error to diverge and undermining the refinement process. To address this, we propose Guided Path Sampling (GPS), a new paradigm for iterative refinement. GPS replaces unstable extrapolation with a principled, manifold-constrained interpolation, ensuring the sampling path remains on the data manifold. We theoretically prove that this correction transforms the error series from unbounded amplification to strictly bounded, guaranteeing stability. Furthermore, we devise an optimal scheduling strategy that dynamically adjusts guidance strength, aligning semantic injection with the model's natural coarse-to-fine generation process. Extensive experiments on modern backbones like SDXL and Hunyuan-DiT show that GPS outperforms existing methods in both perceptual quality and complex prompt adherence. For instance, GPS achieves a superior ImageReward of 0.79 and HPS v2 of 0.2995 on SDXL, while improving overall semantic alignment accuracy on GenEval to 57.45%. Our work establishes that path stability is a prerequisite for effective iterative refinement, and GPS provides a robust framework to achieve it.
Wavelet-based Multi-View Fusion of 4D Radar Tensor and Camera for Robust 3D Object Detection
Dec 28, 20254D millimeter-wave (mmWave) radar has been widely adopted in autonomous driving and robot perception due to its low cost and all-weather robustness. However, its inherent sparsity and limited semantic richness significantly constrain perception capability. Recently, fusing camera data with 4D radar has emerged as a promising cost effective solution, by exploiting the complementary strengths of the two modalities. Nevertheless, point-cloud-based radar often suffer from information loss introduced by multi-stage signal processing, while directly utilizing raw 4D radar data incurs prohibitive computational costs. To address these challenges, we propose WRCFormer, a novel 3D object detection framework that fuses raw radar cubes with camera inputs via multi-view representations of the decoupled radar cube. Specifically, we design a Wavelet Attention Module as the basic module of wavelet-based Feature Pyramid Network (FPN) to enhance the representation of sparse radar signals and image data. We further introduce a two-stage query-based, modality-agnostic fusion mechanism termed Geometry-guided Progressive Fusion to efficiently integrate multi-view features from both modalities. Extensive experiments demonstrate that WRCFormer achieves state-of-the-art performance on the K-Radar benchmarks, surpassing the best model by approximately 2.4% in all scenarios and 1.6% in the sleet scenario, highlighting its robustness under adverse weather conditions.
MMDrive: Interactive Scene Understanding Beyond Vision with Multi-representational Fusion
Dec 16, 2025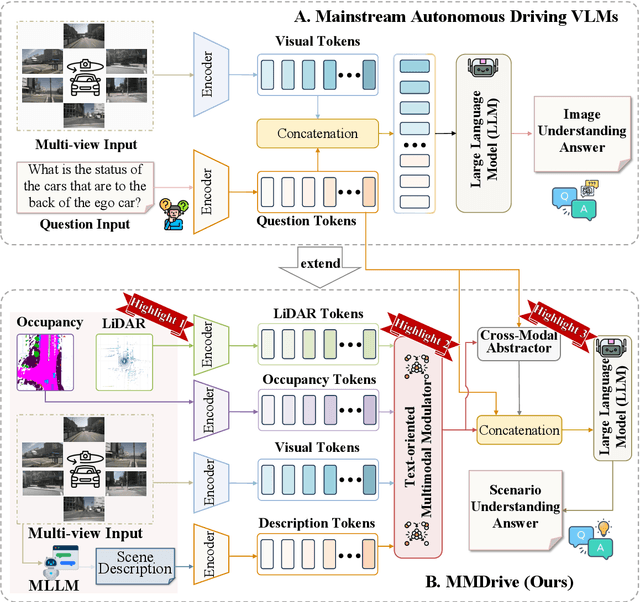
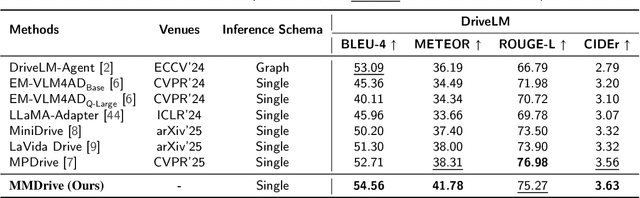


Vision-language models enable the understanding and reasoning of complex traffic scenarios through multi-source information fusion, establishing it as a core technology for autonomous driving. However, existing vision-language models are constrained by the image understanding paradigm in 2D plane, which restricts their capability to perceive 3D spatial information and perform deep semantic fusion, resulting in suboptimal performance in complex autonomous driving environments. This study proposes MMDrive, an multimodal vision-language model framework that extends traditional image understanding to a generalized 3D scene understanding framework. MMDrive incorporates three complementary modalities, including occupancy maps, LiDAR point clouds, and textual scene descriptions. To this end, it introduces two novel components for adaptive cross-modal fusion and key information extraction. Specifically, the Text-oriented Multimodal Modulator dynamically weights the contributions of each modality based on the semantic cues in the question, guiding context-aware feature integration. The Cross-Modal Abstractor employs learnable abstract tokens to generate compact, cross-modal summaries that highlight key regions and essential semantics. Comprehensive evaluations on the DriveLM and NuScenes-QA benchmarks demonstrate that MMDrive achieves significant performance gains over existing vision-language models for autonomous driving, with a BLEU-4 score of 54.56 and METEOR of 41.78 on DriveLM, and an accuracy score of 62.7% on NuScenes-QA. MMDrive effectively breaks the traditional image-only understanding barrier, enabling robust multimodal reasoning in complex driving environments and providing a new foundation for interpretable autonomous driving scene understanding.
Da Yu: Towards USV-Based Image Captioning for Waterway Surveillance and Scene Understanding
Jun 24, 2025Automated waterway environment perception is crucial for enabling unmanned surface vessels (USVs) to understand their surroundings and make informed decisions. Most existing waterway perception models primarily focus on instance-level object perception paradigms (e.g., detection, segmentation). However, due to the complexity of waterway environments, current perception datasets and models fail to achieve global semantic understanding of waterways, limiting large-scale monitoring and structured log generation. With the advancement of vision-language models (VLMs), we leverage image captioning to introduce WaterCaption, the first captioning dataset specifically designed for waterway environments. WaterCaption focuses on fine-grained, multi-region long-text descriptions, providing a new research direction for visual geo-understanding and spatial scene cognition. Exactly, it includes 20.2k image-text pair data with 1.8 million vocabulary size. Additionally, we propose Da Yu, an edge-deployable multi-modal large language model for USVs, where we propose a novel vision-to-language projector called Nano Transformer Adaptor (NTA). NTA effectively balances computational efficiency with the capacity for both global and fine-grained local modeling of visual features, thereby significantly enhancing the model's ability to generate long-form textual outputs. Da Yu achieves an optimal balance between performance and efficiency, surpassing state-of-the-art models on WaterCaption and several other captioning benchmarks.