 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptIQA: Boosting the Performance and Generalization for No-Reference Image Quality Assessment via Prompts
Mar 08, 2024Due to the diversity of assessment requirements in various application scenarios for the IQA task, existing IQA methods struggle to directly adapt to these varied requirements after training. Thus, when facing new requirements, a typical approach is fine-tuning these models on datasets specifically created for those requirements. However, it is time-consuming to establish IQA datasets. In this work, we propose a Prompt-based IQA (PromptIQA) that can directly adapt to new requirements without fine-tuning after training. On one hand, it utilizes a short sequence of Image-Score Pairs (ISP) as prompts for targeted predictions, which significantly reduces the dependency on the data requirements. On the other hand, PromptIQA is trained on a mixed dataset with two proposed data augmentation strategies to learn diverse requirements, thus enabling it to effectively adapt to new requirements. Experiments indicate that the PromptIQA outperforms SOTA methods with higher performance and better generalization. The code will be available.
Semantics-enhanced Cross-modal Masked Image Modeling for Vision-Language Pre-training
Mar 01, 2024In vision-language pre-training (VLP), masked image modeling (MIM) has recently been introduced for fine-grained cross-modal alignment. However, in most existing methods, the reconstruction targets for MIM lack high-level semantics, and text is not sufficiently involved in masked modeling. These two drawbacks limit the effect of MIM in facilitating cross-modal semantic alignment. In this work, we propose a semantics-enhanced cross-modal MIM framework (SemMIM) for vision-language representation learning. Specifically, to provide more semantically meaningful supervision for MIM, we propose a local semantics enhancing approach, which harvest high-level semantics from global image features via self-supervised agreement learning and transfer them to local patch encodings by sharing the encoding space. Moreover, to achieve deep involvement of text during the entire MIM process, we propose a text-guided masking strategy and devise an efficient way of injecting textual information in both masked modeling and reconstruction target acquisition. Experimental results validate that our method improves the effectiveness of the MIM task in facilitating cross-modal semantic alignment. Compared to previous VLP models with similar model size and data scale, our SemMIM model achieves state-of-the-art or competitive performance on multiple downstream vision-language tasks.
Unifying Latent and Lexicon Representations for Effective Video-Text Retrieval
Feb 26, 2024In video-text retrieval, most existing methods adopt the dual-encoder architecture for fast retrieval, which employs two individual encoders to extract global latent representations for videos and texts. However, they face challenges in capturing fine-grained semantic concepts. In this work, we propose the UNIFY framework, which learns lexicon representations to capture fine-grained semantics and combines the strengths of latent and lexicon representations for video-text retrieval. Specifically, we map videos and texts into a pre-defined lexicon space, where each dimension corresponds to a semantic concept. A two-stage semantics grounding approach is proposed to activate semantically relevant dimensions and suppress irrelevant dimensions. The learned lexicon representations can thus reflect fine-grained semantics of videos and texts. Furthermore, to leverage the complementarity between latent and lexicon representations, we propose a unified learning scheme to facilitate mutual learning via structure sharing and self-distillation. Experimental results show our UNIFY framework largely outperforms previous video-text retrieval methods, with 4.8% and 8.2% Recall@1 improvement on MSR-VTT and DiDeMo respectively.
GMC-IQA: Exploiting Global-correlation and Mean-opinion Consistency for No-reference Image Quality Assessment
Jan 19, 2024



Due to the subjective nature of image quality assessment (IQA), assessing which image has better quality among a sequence of images is more reliable than assigning an absolute mean opinion score for an image. Thus, IQA models are evaluated by global correlation consistency (GCC) metrics like PLCC and SROCC, rather than mean opinion consistency (MOC) metrics like MAE and MSE. However, most existing methods adopt MOC metrics to define their loss functions, due to the infeasible computation of GCC metrics during training. In this work, we construct a novel loss function and network to exploit Global-correlation and Mean-opinion Consistency, forming a GMC-IQA framework. Specifically, we propose a novel GCC loss by defining a pairwise preference-based rank estimation to solve the non-differentiable problem of SROCC and introducing a queue mechanism to reserve previous data to approximate the global results of the whole data. Moreover, we propose a mean-opinion network, which integrates diverse opinion features to alleviate the randomness of weight learning and enhance the model robustness. Experiments indicate that our method outperforms SOTA methods on multiple authentic datasets with higher accuracy and generalization. We also adapt the proposed loss to various networks, which brings better performance and more stable training.
I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models
Dec 27, 2023



In the rapidly evolving domain of digital content generation, the focus has shifted from text-to-image (T2I) models to more advanced video diffusion models, notably text-to-video (T2V) and image-to-video (I2V). This paper addresses the intricate challenge posed by I2V: converting static images into dynamic, lifelike video sequences while preserving the original image fidelity. Traditional methods typically involve integrating entire images into diffusion processes or using pretrained encoders for cross attention. However, these approaches often necessitate altering the fundamental weights of T2I models, thereby restricting their reusability. We introduce a novel solution, namely I2V-Adapter, designed to overcome such limitations. Our approach preserves the structural integrity of T2I models and their inherent motion modules. The I2V-Adapter operates by processing noised video frames in parallel with the input image, utilizing a lightweight adapter module. This module acts as a bridge, efficiently linking the input to the model's self-attention mechanism, thus maintaining spatial details without requiring structural changes to the T2I model. Moreover, I2V-Adapter requires only a fraction of the parameters of conventional models and ensures compatibility with existing community-driven T2I models and controlling tools. Our experimental results demonstrate I2V-Adapter's capability to produce high-quality video outputs. This performance, coupled with its versatility and reduced need for trainable parameters, represents a substantial advancement in the field of AI-driven video generation, particularly for creative applications.
Set Prediction Guided by Semantic Concepts for Diverse Video Captioning
Dec 25, 2023



Diverse video captioning aims to generate a set of sentences to describe the given video in various aspects. Mainstream methods are trained with independent pairs of a video and a caption from its ground-truth set without exploiting the intra-set relationship, resulting in low diversity of generated captions. Different from them, we formulate diverse captioning into a semantic-concept-guided set prediction (SCG-SP) problem by fitting the predicted caption set to the ground-truth set, where the set-level relationship is fully captured. Specifically, our set prediction consists of two synergistic tasks, i.e., caption generation and an auxiliary task of concept combination prediction providing extra semantic supervision. Each caption in the set is attached to a concept combination indicating the primary semantic content of the caption and facilitating element alignment in set prediction. Furthermore, we apply a diversity regularization term on concepts to encourage the model to generate semantically diverse captions with various concept combinations. These two tasks share multiple semantics-specific encodings as input, which are obtained by iterative interaction between visual features and conceptual queries. The correspondence between the generated captions and specific concept combinations further guarantees the interpretability of our model. Extensive experiments on benchmark datasets show that the proposed SCG-SP achieves state-of-the-art (SOTA) performance under both relevance and diversity metrics.
ZoomTrack: Target-aware Non-uniform Resizing for Efficient Visual Tracking
Oct 16, 2023



Recently, the transformer has enabled the speed-oriented trackers to approach state-of-the-art (SOTA) performance with high-speed thanks to the smaller input size or the lighter feature extraction backbone, though they still substantially lag behind their corresponding performance-oriented versions. In this paper, we demonstrate that it is possible to narrow or even close this gap while achieving high tracking speed based on the smaller input size. To this end, we non-uniformly resize the cropped image to have a smaller input size while the resolution of the area where the target is more likely to appear is higher and vice versa. This enables us to solve the dilemma of attending to a larger visual field while retaining more raw information for the target despite a smaller input size. Our formulation for the non-uniform resizing can be efficiently solved through quadratic programming (QP) and naturally integrated into most of the crop-based local trackers. Comprehensive experiments on five challenging datasets based on two kinds of transformer trackers, \ie, OSTrack and TransT, demonstrate consistent improvements over them. In particular, applying our method to the speed-oriented version of OSTrack even outperforms its performance-oriented counterpart by 0.6% AUC on TNL2K, while running 50% faster and saving over 55% MACs. Codes and models are available at https://github.com/Kou-99/ZoomTrack.
RT-MonoDepth: Real-time Monocular Depth Estimation on Embedded Systems
Aug 21, 2023



Depth sensing is a crucial function of unmanned aerial vehicles and autonomous vehicles. Due to the small size and simple structure of monocular cameras, there has been a growing interest in depth estimation from a single RGB image. However, state-of-the-art monocular CNN-based depth estimation methods using fairly complex deep neural networks are too slow for real-time inference on embedded platforms. This paper addresses the problem of real-time depth estimation on embedded systems. We propose two efficient and lightweight encoder-decoder network architectures, RT-MonoDepth and RT-MonoDepth-S, to reduce computational complexity and latency. Our methodologies demonstrate that it is possible to achieve similar accuracy as prior state-of-the-art works on depth estimation at a faster inference speed. Our proposed networks, RT-MonoDepth and RT-MonoDepth-S, runs at 18.4\&30.5 FPS on NVIDIA Jetson Nano and 253.0\&364.1 FPS on NVIDIA Jetson AGX Orin on a single RGB image of resolution 640$\times$192, and achieve relative state-of-the-art accuracy on the KITTI dataset. To the best of the authors' knowledge, this paper achieves the best accuracy and fastest inference speed compared with existing fast monocular depth estimation methods.
EBHI-Seg: A Novel Enteroscope Biopsy Histopathological Haematoxylin and Eosin Image Dataset for Image Segmentation Tasks
Dec 06, 2022



Background and Purpose: Colorectal cancer is a common fatal malignancy, the fourth most common cancer in men, and the third most common cancer in women worldwide. Timely detection of cancer in its early stages is essential for treating the disease. Currently, there is a lack of datasets for histopathological image segmentation of rectal cancer, which often hampers the assessment accuracy when computer technology is used to aid in diagnosis. Methods: This present study provided a new publicly available Enteroscope Biopsy Histopathological Hematoxylin and Eosin Image Dataset for Image Segmentation Tasks (EBHI-Seg). To demonstrate the validity and extensiveness of EBHI-Seg, the experimental results for EBHI-Seg are evaluated using classical machine learning methods and deep learning methods. Results: The experimental results showed that deep learning methods had a better image segmentation performance when utilizing EBHI-Seg. The maximum accuracy of the Dice evaluation metric for the classical machine learning method is 0.948, while the Dice evaluation metric for the deep learning method is 0.965. Conclusion: This publicly available dataset contained 5,170 images of six types of tumor differentiation stages and the corresponding ground truth images. The dataset can provide researchers with new segmentation algorithms for medical diagnosis of colorectal cancer, which can be used in the clinical setting to help doctors and patients.
DSPNet: Towards Slimmable Pretrained Networks based on Discriminative Self-supervised Learning
Jul 13, 2022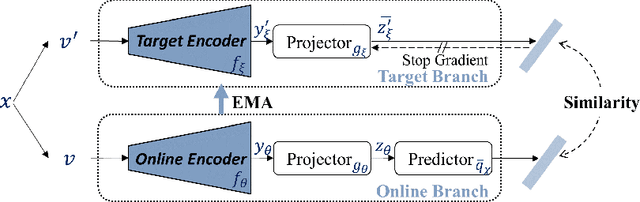
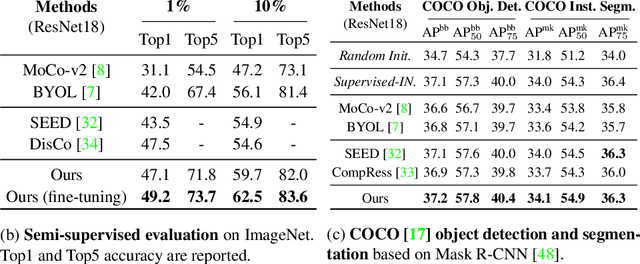
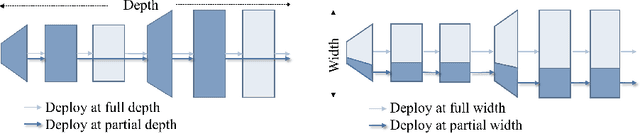
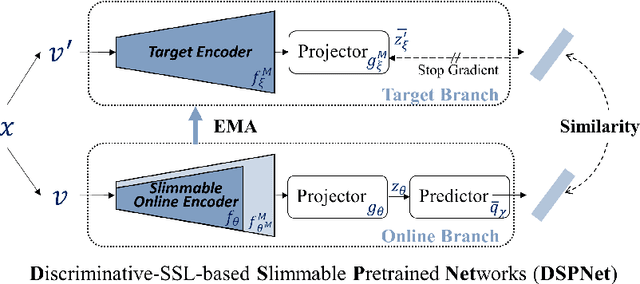
Self-supervised learning (SSL) has achieved promising downstream performance. However, when facing various resource budgets in real-world applications, it costs a huge computation burden to pretrain multiple networks of various sizes one by one. In this paper, we propose Discriminative-SSL-based Slimmable Pretrained Networks (DSPNet), which can be trained at once and then slimmed to multiple sub-networks of various sizes, each of which faithfully learns good representation and can serve as good initialization for downstream tasks with various resource budgets. Specifically, we extend the idea of slimmable networks to a discriminative SSL paradigm, by integrating SSL and knowledge distillation gracefully. We show comparable or improved performance of DSPNet on ImageNet to the networks individually pretrained one by one under the linear evaluation and semi-supervised evaluation protocols, while reducing large training cost. The pretrained models also generalize well on downstream detection and segmentation tasks. Code will be made public.