 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Learning of Visual-Audio Saliency Prediction and Sound Source Localization on Multi-face Videos
Paper and Code
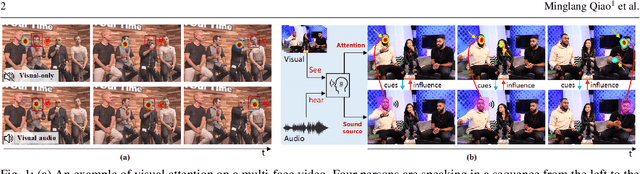
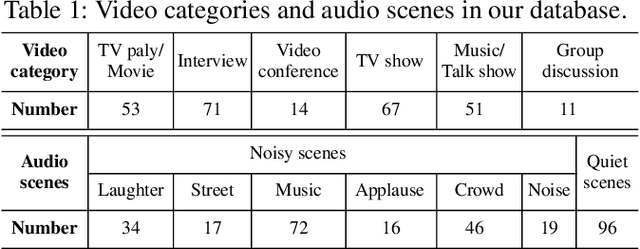

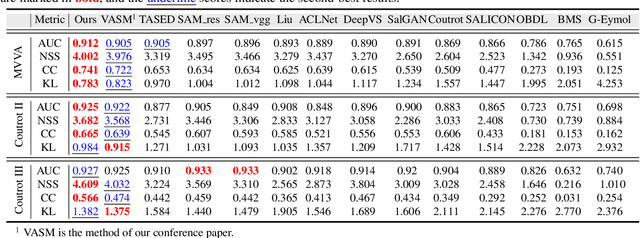
Visual and audio events simultaneously occur and both attract attention. However, most existing saliency prediction works ignore the influence of audio and only consider vision modality. In this paper, we propose a multitask learning method for visual-audio saliency prediction and sound source localization on multi-face video by leveraging visual, audio and face information. Specifically, we first introduce a large-scale database of multi-face video in visual-audio condition (MVVA), containing eye-tracking data and sound source annotations. Using this database, we find that sound influences human attention, and conversly attention offers a cue to determine sound source on multi-face video. Guided by these findings, a visual-audio multi-task network (VAM-Net) is introduced to predict saliency and locate sound source. VAM-Net consists of three branches corresponding to visual, audio and face modalities. Visual branch has a two-stream architecture to capture spatial and temporal information. Face and audio branches encode audio signals and faces, respectively. Finally, a spatio-temporal multi-modal graph (STMG) is constructed to model the interaction among multiple faces. With joint optimization of these branches, the intrinsic correlation of the tasks of saliency prediction and sound source localization is utilized and their performance is boosted by each other. Experiments show that the proposed method outperforms 12 state-of-the-art saliency prediction methods, and achieves competitive results in sound source localization.