 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fractals by Gradient Descent
Mar 14, 2023



Fractals are geometric shapes that can display complex and self-similar patterns found in nature (e.g., clouds and plants). Recent works in visual recognition have leveraged this property to create random fractal images for model pre-training. In this paper, we study the inverse problem -- given a target image (not necessarily a fractal), we aim to generate a fractal image that looks like it. We propose a novel approach that learns the parameters underlying a fractal image via gradient descent. We show that our approach can find fractal parameters of high visual quality and be compatible with different loss functions, opening up several potentials, e.g., learning fractals for downstream tasks, scientific understanding, etc.
Making Batch Normalization Great in Federated Deep Learning
Mar 12, 2023Batch Normalization (BN) is commonly used in modern deep neural networks (DNNs) to improve stability and speed up convergence during centralized training. In federated learning (FL) with non-IID decentralized data, previous works observed that training with BN could hinder performance due to the mismatch of the BN statistics between training and testing. Group Normalization (GN) is thus more often used in FL as an alternative to BN. However, from our empirical study across various FL settings, we see no consistent winner between BN and GN. This leads us to revisit the use of normalization layers in FL. We find that with proper treatments, BN can be highly competitive across a wide range of FL settings, and this requires no additional training or communication costs. We hope that our study could serve as a valuable reference for future practical usage and theoretical analysis in FL.
LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models
Dec 08, 2022



This study focuses on embodied agents that can follow natural language instructions to complete complex tasks in a visually-perceived environment. Existing methods rely on a large amount of (instruction, gold trajectory) pairs to learn a good policy. The high data cost and poor sample efficiency prevents the development of versatile agents that are capable of many tasks and can learn new tasks quickly. In this work, we propose a novel method, LLM-Planner, that harnesses the power of large language models (LLMs) such as GPT-3 to do few-shot planning for embodied agents. We further propose a simple but effective way to enhance LLMs with physical grounding to generate plans that are grounded in the current environment. Experiments on the ALFRED dataset show that our method can achieve very competitive few-shot performance, even outperforming several recent baselines that are trained using the full training data despite using less than 0.5% of paired training data. Existing methods can barely complete any task successfully under the same few-shot setting. Our work opens the door for developing versatile and sample-efficient embodied agents that can quickly learn many tasks.
Visual Query Tuning: Towards Effective Usage of Intermediate Representations for Parameter and Memory Efficient Transfer Learning
Dec 06, 2022



Intermediate features of a pre-trained model have been shown informative for making accurate predictions on downstream tasks, even if the model backbone is kept frozen. The key challenge is how to utilize these intermediate features given their gigantic amount. We propose visual query tuning (VQT), a simple yet effective approach to aggregate intermediate features of Vision Transformers. Through introducing a handful of learnable ``query'' tokens to each layer, VQT leverages the inner workings of Transformers to ``summarize'' rich intermediate features of each layer, which can then be used to train the prediction heads of downstream tasks. As VQT keeps the intermediate features intact and only learns to combine them, it enjoys memory efficiency in training, compared to many other parameter-efficient fine-tuning approaches that learn to adapt features and need back-propagation through the entire backbone. This also suggests the complementary role between VQT and those approaches in transfer learning. Empirically, VQT consistently surpasses the state-of-the-art approach that utilizes intermediate features for transfer learning and outperforms full fine-tuning in many cases. Compared to parameter-efficient approaches that adapt features, VQT achieves much higher accuracy under memory constraints. Most importantly, VQT is compatible with these approaches to attain even higher accuracy, making it a simple add-on to further boost transfer learning.
Image-to-Image Translation for Autonomous Driving from Coarsely-Aligned Image Pairs
Sep 23, 2022
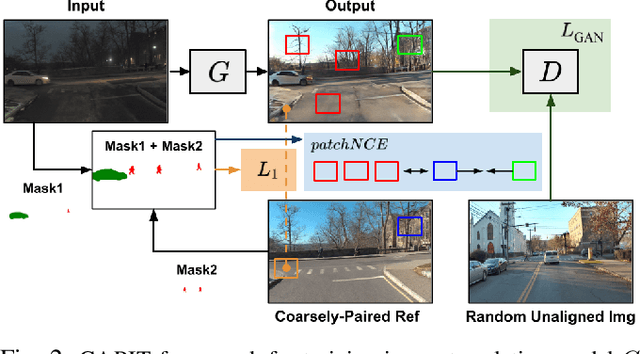

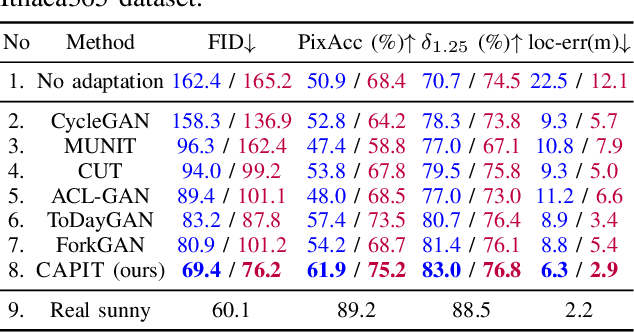
A self-driving car must be able to reliably handle adverse weather conditions (e.g., snowy) to operate safely. In this paper, we investigate the idea of turning sensor inputs (i.e., images) captured in an adverse condition into a benign one (i.e., sunny), upon which the downstream tasks (e.g., semantic segmentation) can attain high accuracy. Prior work primarily formulates this as an unpaired image-to-image translation problem due to the lack of paired images captured under the exact same camera poses and semantic layouts. While perfectly-aligned images are not available, one can easily obtain coarsely-paired images. For instance, many people drive the same routes daily in both good and adverse weather; thus, images captured at close-by GPS locations can form a pair. Though data from repeated traversals are unlikely to capture the same foreground objects, we posit that they provide rich contextual information to supervise the image translation model. To this end, we propose a novel training objective leveraging coarsely-aligned image pairs. We show that our coarsely-aligned training scheme leads to a better image translation quality and improved downstream tasks, such as semantic segmentation, monocular depth estimation, and visual localization.
PreSTU: Pre-Training for Scene-Text Understanding
Sep 12, 2022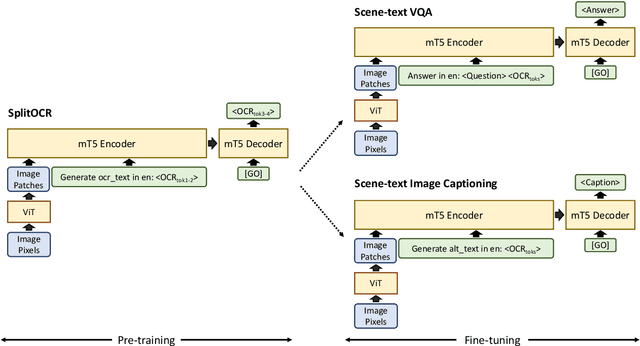
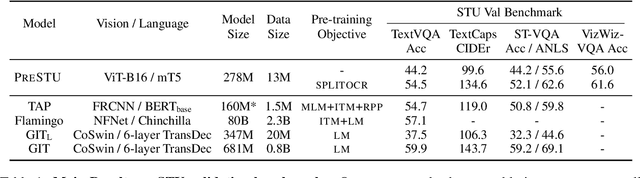
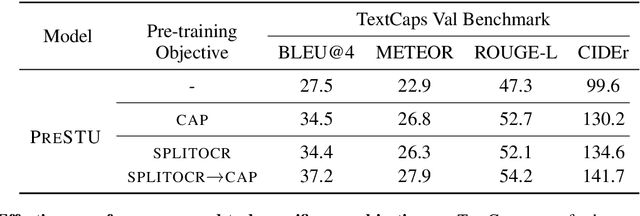
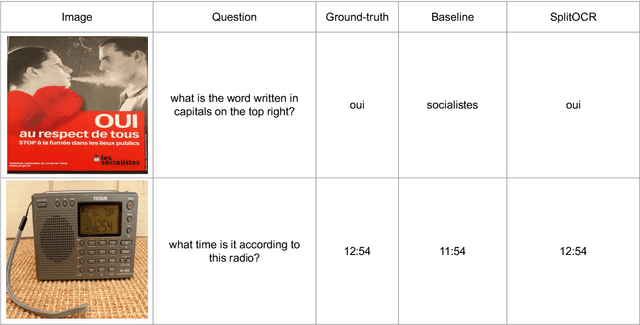
The ability to read and reason about texts in an image is often lacking in vision-and-language (V&L) models. How can we learn V&L models that exhibit strong scene-text understanding (STU)? In this paper, we propose PreSTU, a simple pre-training recipe specifically designed for scene-text understanding. PreSTU combines a simple OCR-aware pre-training objective with a large-scale image-text dataset with off-the-shelf OCR signals. We empirically demonstrate the superiority of this pre-training objective on TextVQA, TextCaps, ST-VQA, and VizWiz-VQA. We also study which factors affect STU performance, where we highlight the importance of image resolution and dataset scale during pre-training.
Ithaca365: Dataset and Driving Perception under Repeated and Challenging Weather Conditions
Aug 01, 2022
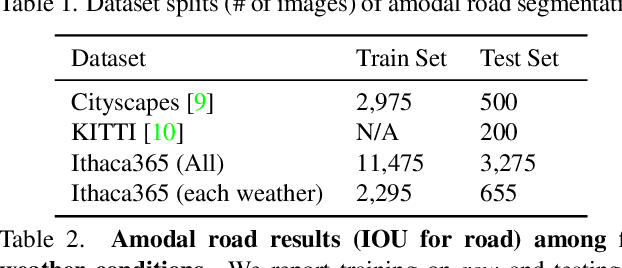
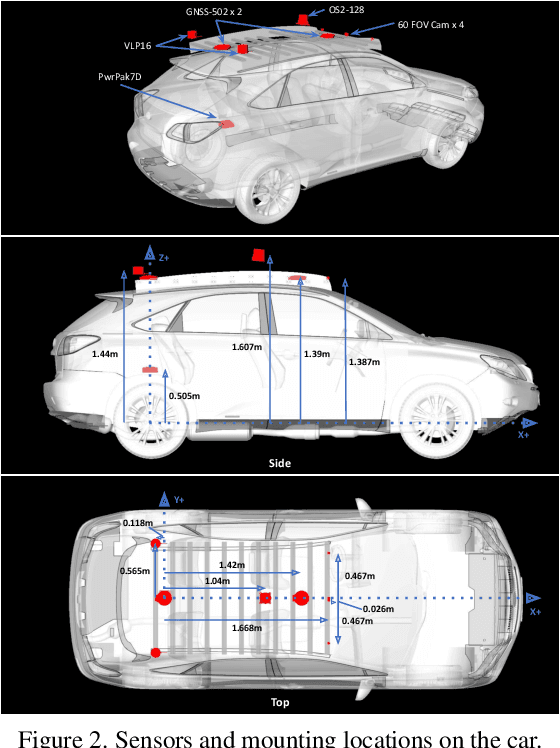
Advances in perception for self-driving cars have accelerated in recent years due to the availability of large-scale datasets, typically collected at specific locations and under nice weather conditions. Yet, to achieve the high safety requirement, these perceptual systems must operate robustly under a wide variety of weather conditions including snow and rain. In this paper, we present a new dataset to enable robust autonomous driving via a novel data collection process - data is repeatedly recorded along a 15 km route under diverse scene (urban, highway, rural, campus), weather (snow, rain, sun), time (day/night), and traffic conditions (pedestrians, cyclists and cars). The dataset includes images and point clouds from cameras and LiDAR sensors, along with high-precision GPS/INS to establish correspondence across routes. The dataset includes road and object annotations using amodal masks to capture partial occlusions and 3D bounding boxes. We demonstrate the uniqueness of this dataset by analyzing the performance of baselines in amodal segmentation of road and objects, depth estimation, and 3D object detection. The repeated routes opens new research directions in object discovery, continual learning, and anomaly detection. Link to Ithaca365: https://ithaca365.mae.cornell.edu/
Gradual Domain Adaptation without Indexed Intermediate Domains
Jul 11, 2022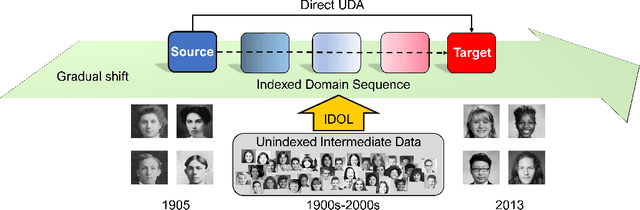
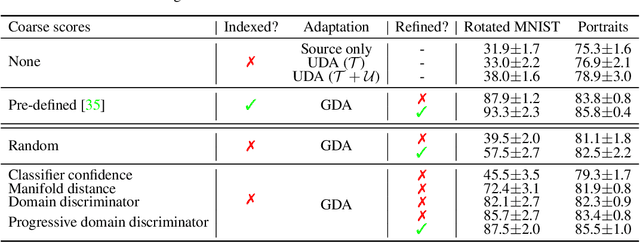
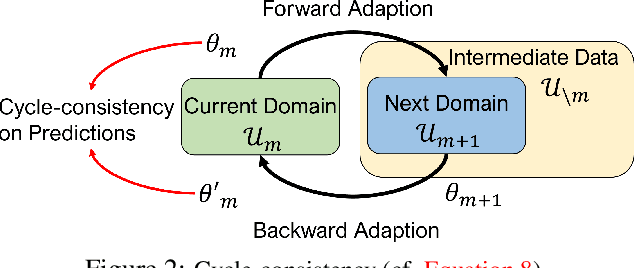
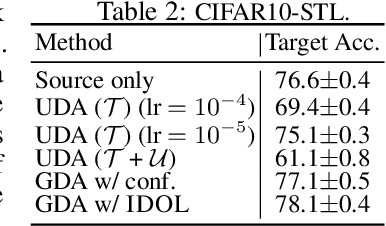
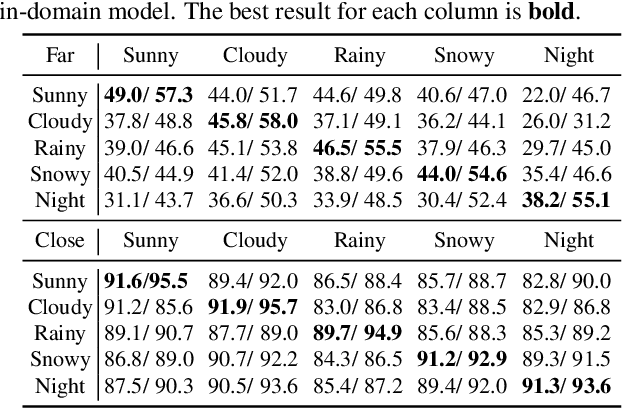
The effectiveness of unsupervised domain adaptation degrades when there is a large discrepancy between the source and target domains. Gradual domain adaptation (GDA) is one promising way to mitigate such an issue, by leveraging additional unlabeled data that gradually shift from the source to the target. Through sequentially adapting the model along the "indexed" intermediate domains, GDA substantially improves the overall adaptation performance. In practice, however, the extra unlabeled data may not be separated into intermediate domains and indexed properly, limiting the applicability of GDA. In this paper, we investigate how to discover the sequence of intermediate domains when it is not already available. Concretely, we propose a coarse-to-fine framework, which starts with a coarse domain discovery step via progressive domain discriminator training. This coarse domain sequence then undergoes a fine indexing step via a novel cycle-consistency loss, which encourages the next intermediate domain to preserve sufficient discriminative knowledge of the current intermediate domain. The resulting domain sequence can then be used by a GDA algorithm. On benchmark data sets of GDA, we show that our approach, which we name Intermediate DOmain Labeler (IDOL), can lead to comparable or even better adaptation performance compared to the pre-defined domain sequence, making GDA more applicable and robust to the quality of domain sequences. Codes are available at https://github.com/hongyouc/IDOL.
On Pre-Training for Federated Learning
Jun 23, 2022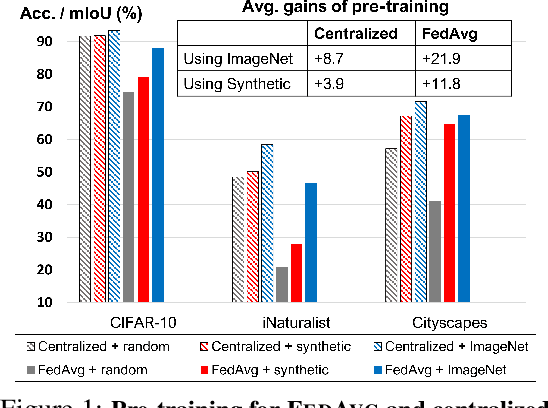
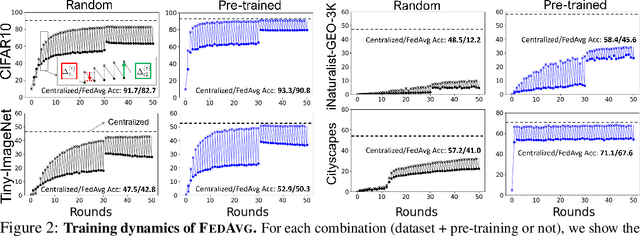
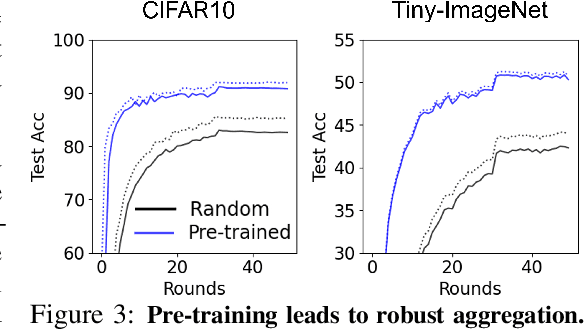
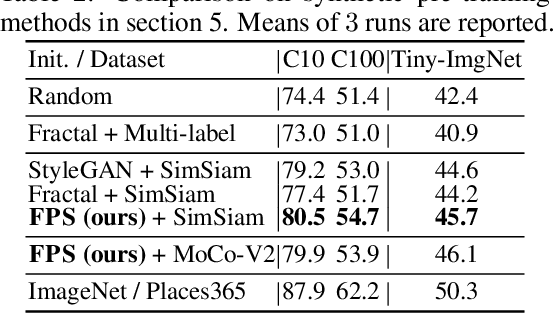
In most of the literature on federated learning (FL), neural networks are initialized with random weights. In this paper, we present an empirical study on the effect of pre-training on FL. Specifically, we aim to investigate if pre-training can alleviate the drastic accuracy drop when clients' decentralized data are non-IID. We focus on FedAvg, the fundamental and most widely used FL algorithm. We found that pre-training does largely close the gap between FedAvg and centralized learning under non-IID data, but this does not come from alleviating the well-known model drifting problem in FedAvg's local training. Instead, how pre-training helps FedAvg is by making FedAvg's global aggregation more stable. When pre-training using real data is not feasible for FL, we propose a novel approach to pre-train with synthetic data. On various image datasets (including one for segmentation), our approach with synthetic pre-training leads to a notable gain, essentially a critical step toward scaling up federated learning for real-world applications.
Learning to Detect Mobile Objects from LiDAR Scans Without Labels
Mar 29, 2022

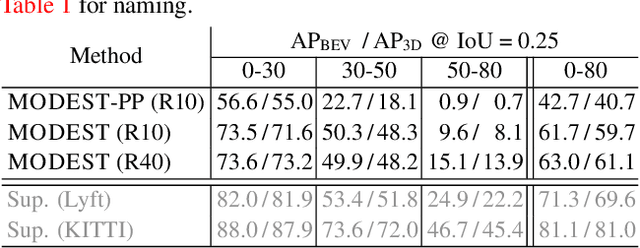
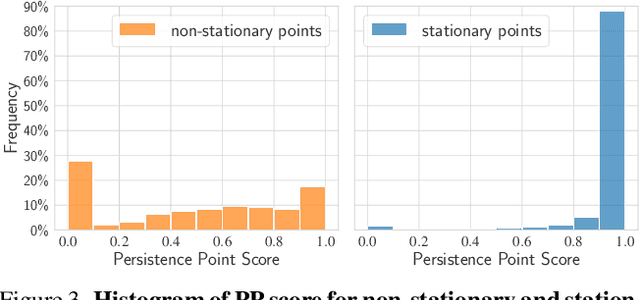
Current 3D object detectors for autonomous driving are almost entirely trained on human-annotated data. Although of high quality, the generation of such data is laborious and costly, restricting them to a few specific locations and object types. This paper proposes an alternative approach entirely based on unlabeled data, which can be collected cheaply and in abundance almost everywhere on earth. Our approach leverages several simple common sense heuristics to create an initial set of approximate seed labels. For example, relevant traffic participants are generally not persistent across multiple traversals of the same route, do not fly, and are never under ground. We demonstrate that these seed labels are highly effective to bootstrap a surprisingly accurate detector through repeated self-training without a single human annotated label.