 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActFormer: A GAN Transformer Framework towards General Action-Conditioned 3D Human Motion Generation
Mar 15, 2022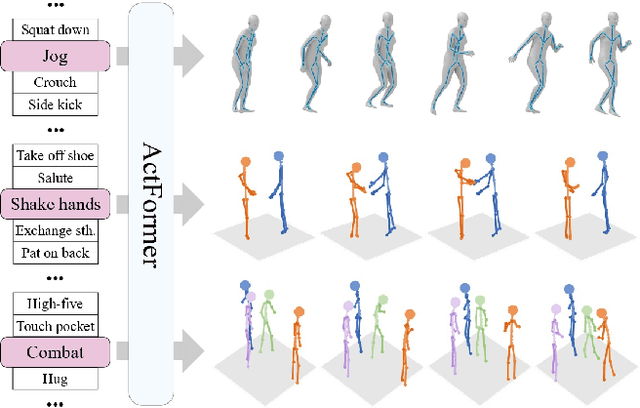

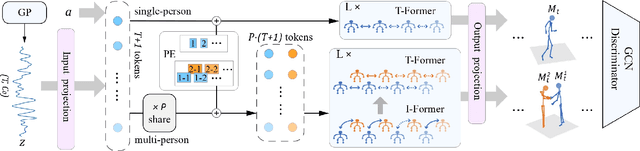

We present a GAN Transformer framework for general action-conditioned 3D human motion generation, including not only single-person actions but also multi-person interactive actions. Our approach consists of a powerful Action-conditioned motion transFormer (ActFormer) under a GAN training scheme, equipped with a Gaussian Process latent prior. Such a design combines the strong spatio-temporal representation capacity of Transformer, superiority in generative modeling of GAN, and inherent temporal correlations from latent prior. Furthermore, ActFormer can be naturally extended to multi-person motions by alternately modeling temporal correlations and human interactions with Transformer encoders. We validate our approach by comparison with other methods on larger-scale benchmarks, including NTU RGB+D 120 and BABEL. We also introduce a new synthetic dataset of complex multi-person combat behaviors to facilitate research on multi-person motion generation. Our method demonstrates adaptability to various human motion representations and achieves leading performance over SOTA methods on both single-person and multi-person motion generation tasks, indicating a hopeful step towards a universal human motion generator.
Backbone is All Your Need: A Simplified Architecture for Visual Object Tracking
Mar 10, 2022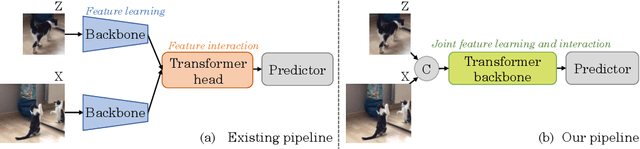
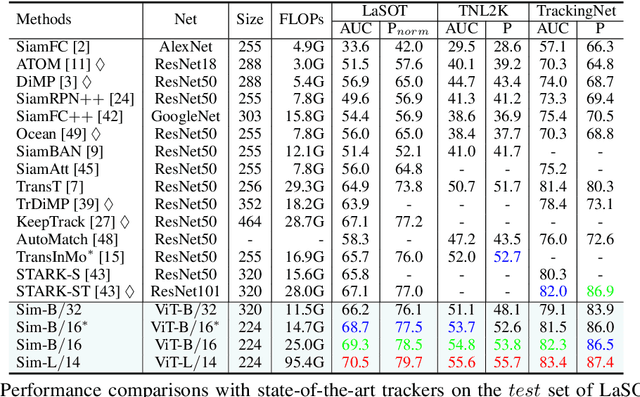
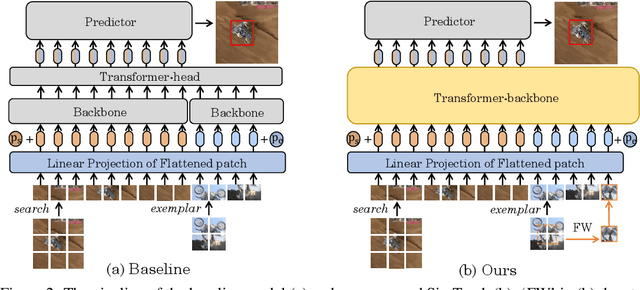
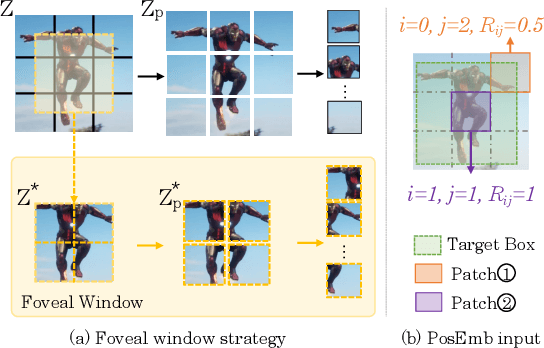
Exploiting a general-purpose neural architecture to replace hand-wired designs or inductive biases has recently drawn extensive interest. However, existing tracking approaches rely on customized sub-modules and need prior knowledge for architecture selection, hindering the tracking development in a more general system. This paper presents a Simplified Tracking architecture (SimTrack) by leveraging a transformer backbone for joint feature extraction and interaction. Unlike existing Siamese trackers, we serialize the input images and concatenate them directly before the one-branch backbone. Feature interaction in the backbone helps to remove well-designed interaction modules and produce a more efficient and effective framework. To reduce the information loss from down-sampling in vision transformers, we further propose a foveal window strategy, providing more diverse input patches with acceptable computational costs. Our SimTrack improves the baseline with 2.5%/2.6% AUC gains on LaSOT/TNL2K and gets results competitive with other specialized tracking algorithms without bells and whistles.
InstructionNER: A Multi-Task Instruction-Based Generative Framework for Few-shot NER
Mar 08, 2022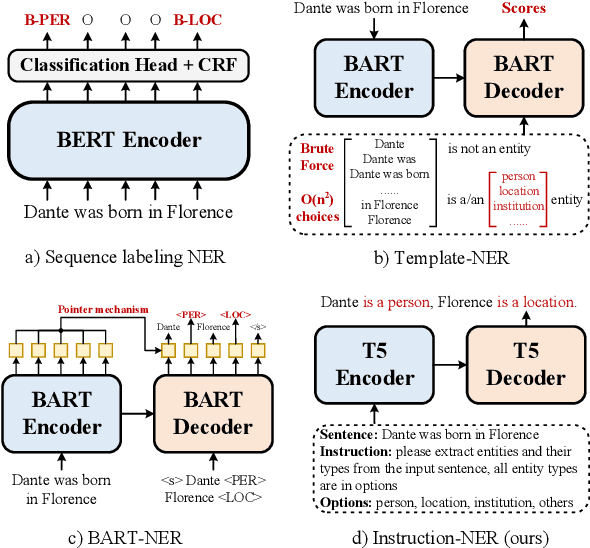
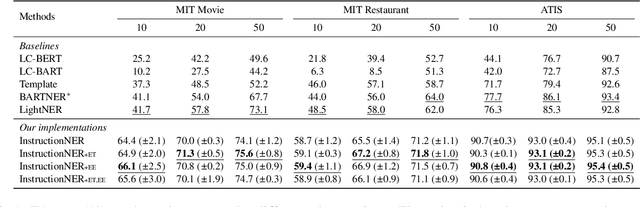
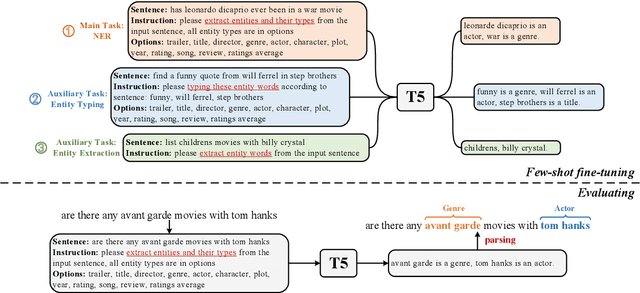

Recently, prompt-based methods have achieved significant performance in few-shot learning scenarios by bridging the gap between language model pre-training and fine-tuning for downstream tasks. However, existing prompt templates are mostly designed for sentence-level tasks and are inappropriate for sequence labeling objectives. To address the above issue, we propose a multi-task instruction-based generative framework, named InstructionNER, for low-resource named entity recognition. Specifically, we reformulate the NER task as a generation problem, which enriches source sentences with task-specific instructions and answer options, then inferences the entities and types in natural language. We further propose two auxiliary tasks, including entity extraction and entity typing, which enable the model to capture more boundary information of entities and deepen the understanding of entity type semantics, respectively. Experimental results show that our method consistently outperforms other baselines on five datasets in few-shot settings.
Graph Neural Network-Based Scheduling for Multi-UAV-Enabled Communications in D2D Networks
Feb 15, 2022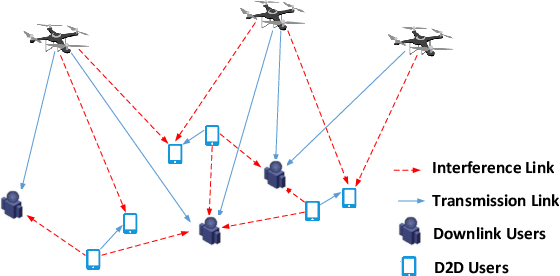
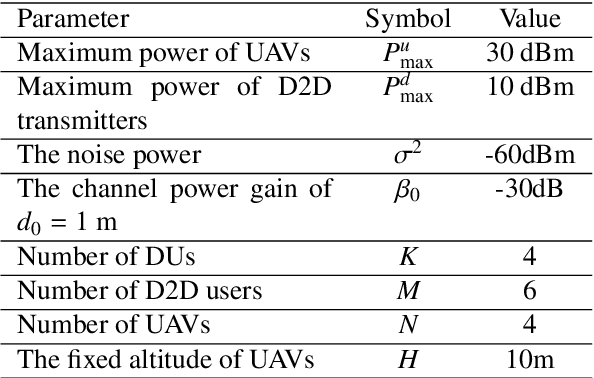
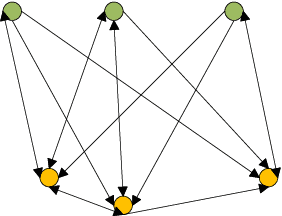
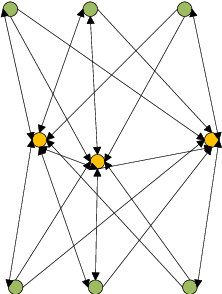
In this paper, we jointly design the power control and position dispatch for Multi-unmanned aerial vehicle (UAV)-enabled communication in device-to-device (D2D) networks. Our objective is to maximize the total transmission rate of downlink users (DUs). Meanwhile, the quality of service (QoS) of all D2D users must be satisfied. We comprehensively considered the interference among D2D communications and downlink transmissions. The original problem is strongly non-convex, which requires high computational complexity for traditional optimization methods. And to make matters worse, the results are not necessarily globally optimal. In this paper, we propose a novel graph neural networks (GNN) based approach that can map the considered system into a specific graph structure and achieve the optimal solution in a low complexity manner. Particularly, we first construct a GNN-based model for the proposed network, in which the transmission links and interference links are formulated as vertexes and edges, respectively. Then, by taking the channel state information and the coordinates of ground users as the inputs, as well as the location of UAVs and the transmission power of all transmitters as outputs, we obtain the mapping from inputs to outputs through training the parameters of GNN. Simulation results verified that the way to maximize the total transmission rate of DUs can be extracted effectively via the training on samples. Moreover, it also shows that the performance of proposed GNN-based method is better than that of traditional means.
Intelligent Resource Allocations for IRS-Assisted OFDM Communications: A Hybrid MDQN-DDPG Approach
Feb 10, 2022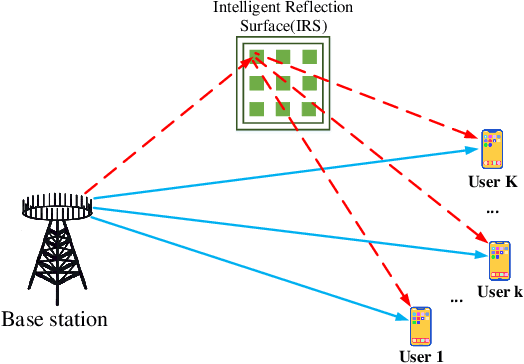
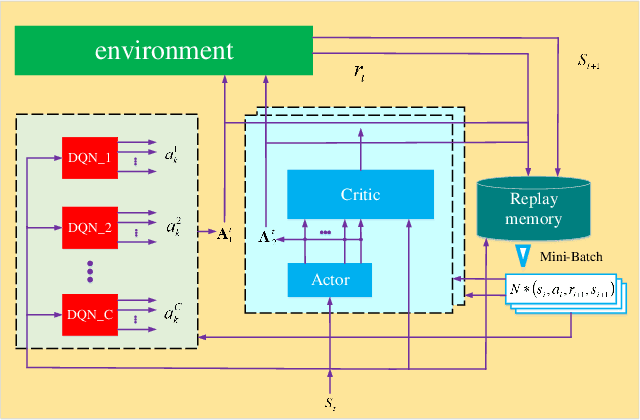
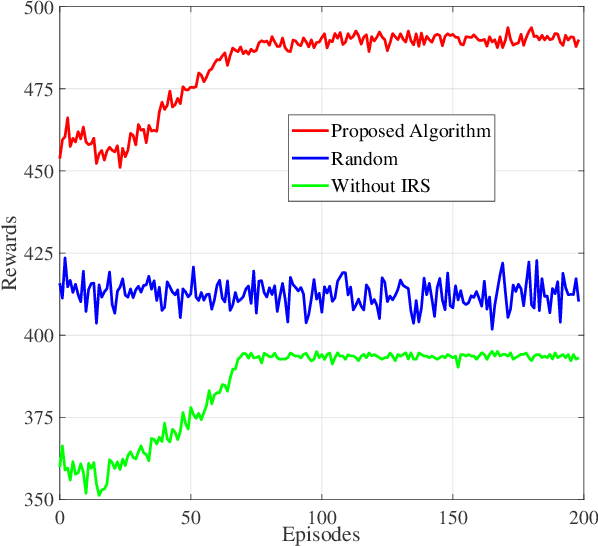
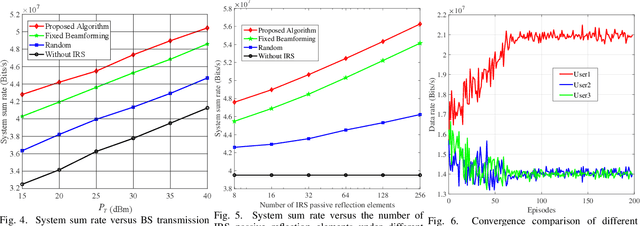
In this paper, we study the resource allocation problem for an intelligent reflecting surface (IRS)-assisted OFDM system. The system sum rate maximization framework is formulated by jointly optimizing subcarrier allocation, base station transmit beamforming and IRS phase shift. Considering the continuous and discrete hybrid action space characteristics of the optimization variables, we propose an efficient resource allocation algorithm combining multiple deep Q networks (MDQN) and deep deterministic policy-gradient (DDPG) to deal with this issue. In our algorithm, MDQN are employed to solve the problem of large discrete action space, while DDPG is introduced to tackle the continuous action allocation. Compared with the traditional approaches, our proposed MDQN-DDPG based algorithm has the advantage of continuous behavior improvement through learning from the environment. Simulation results demonstrate superior performance of our design in terms of system sum rate compared with the benchmark schemes.
Unmanned Aerial Vehicle Swarm-Enabled Edge Computing: Potentials, Promising Technologies, and Challenges
Jan 21, 2022
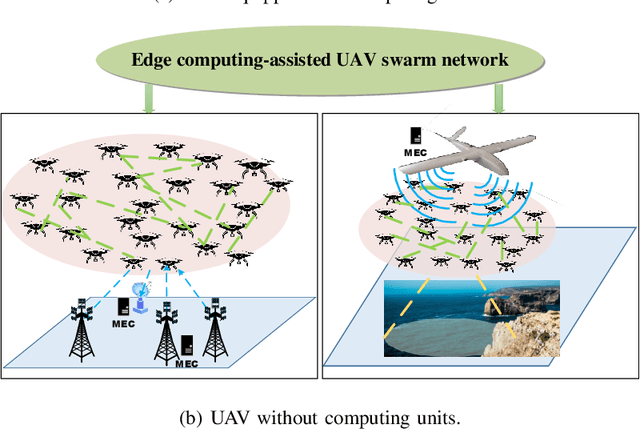
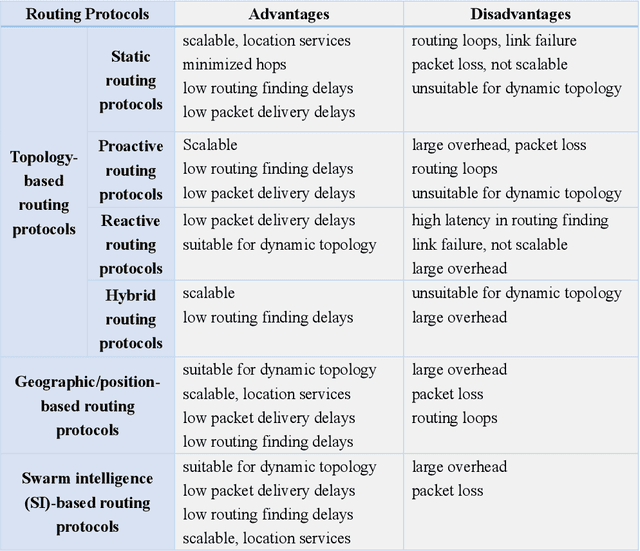
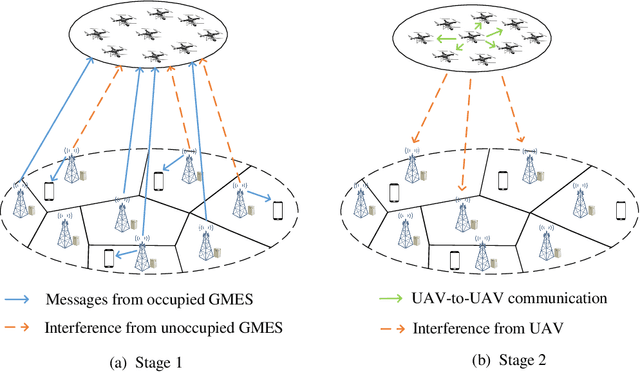
Unmanned aerial vehicle (UAV) swarm enabled edge computing is envisioned to be promising in the sixth generation wireless communication networks due to their wide application sensories and flexible deployment. However, most of the existing works focus on edge computing enabled by a single or a small scale UAVs, which are very different from UAV swarm-enabled edge computing. In order to facilitate the practical applications of UAV swarm-enabled edge computing, the state of the art research is presented in this article. The potential applications, architectures and implementation considerations are illustrated. Moreover, the promising enabling technologies for UAV swarm-enabled edge computing are discussed. Furthermore, we outline challenges and open issues in order to shed light on the future research directions.
Pay More Attention to History: A Context Modeling Strategy for Conversational Text-to-SQL
Dec 16, 2021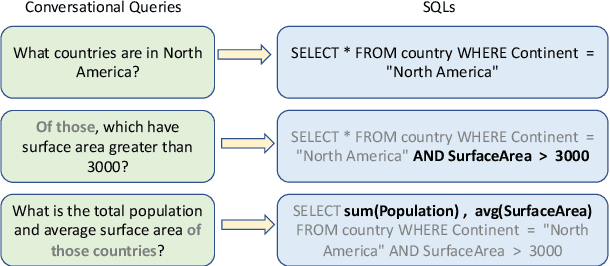
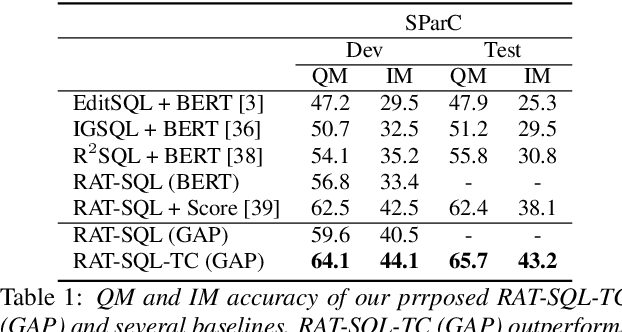
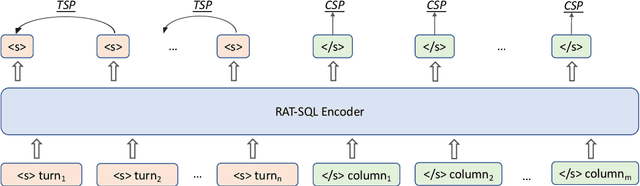
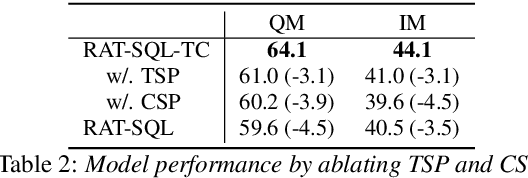
Conversational text-to-SQL aims at converting multi-turn natural language queries into their corresponding SQL representations. One of the most intractable problem of conversational text-to-SQL is modeling the semantics of multi-turn queries and gathering proper information required for the current query. This paper shows that explicit modeling the semantic changes by adding each turn and the summarization of the whole context can bring better performance on converting conversational queries into SQLs. In particular, we propose two conversational modeling tasks in both turn grain and conversation grain. These two tasks simply work as auxiliary training tasks to help with multi-turn conversational semantic parsing. We conducted empirical studies and achieve new state-of-the-art results on large-scale open-domain conversational text-to-SQL dataset. The results demonstrate that the proposed mechanism significantly improves the performance of multi-turn semantic parsing.
VIRT: Improving Representation-based Models for Text Matching through Virtual Interaction
Dec 08, 2021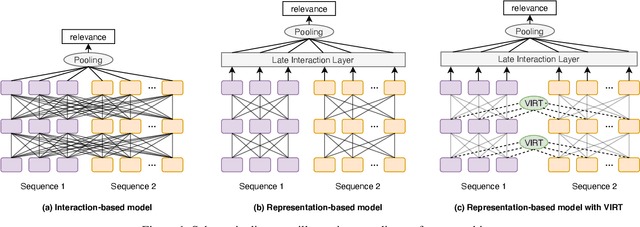
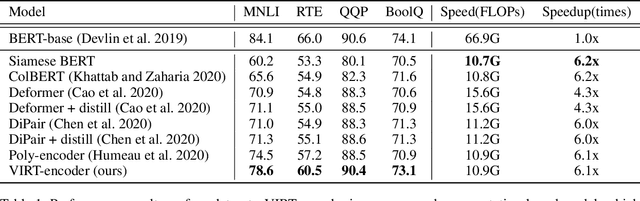
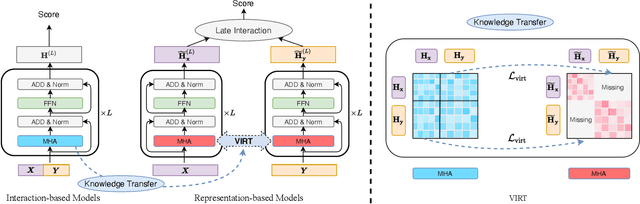
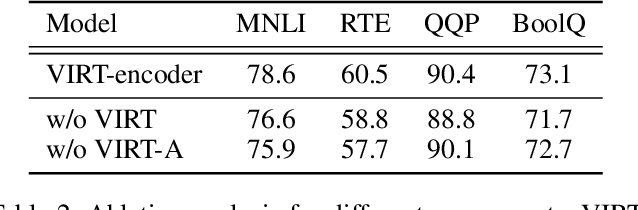
With the booming of pre-trained transformers, remarkable progress has been made on textual pair modeling to support relevant natural language applications. Two lines of approaches are developed for text matching: interaction-based models performing full interactions over the textual pair, and representation-based models encoding the pair independently with siamese encoders. The former achieves compelling performance due to its deep interaction modeling ability, yet with a sacrifice in inference latency. The latter is efficient and widely adopted for practical use, however, suffers from severe performance degradation due to the lack of interactions. Though some prior works attempt to integrate interactive knowledge into representation-based models, considering the computational cost, they only perform late interaction or knowledge transferring at the top layers. Interactive information in the lower layers is still missing, which limits the performance of representation-based solutions. To remedy this, we propose a novel \textit{Virtual} InteRacTion mechanism, termed as VIRT, to enable full and deep interaction modeling in representation-based models without \textit{actual} inference computations. Concretely, VIRT asks representation-based encoders to conduct virtual interactions to mimic the behaviors as interaction-based models do. In addition, the knowledge distilled from interaction-based encoders is taken as supervised signals to promise the effectiveness of virtual interactions. Since virtual interactions only happen at the training stage, VIRT would not increase the inference cost. Furthermore, we design a VIRT-adapted late interaction strategy to fully utilize the learned virtual interactive knowledge.
Regularity Learning via Explicit Distribution Modeling for Skeletal Video Anomaly Detection
Dec 08, 2021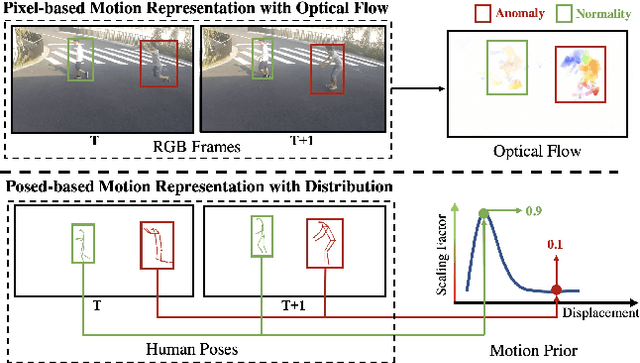
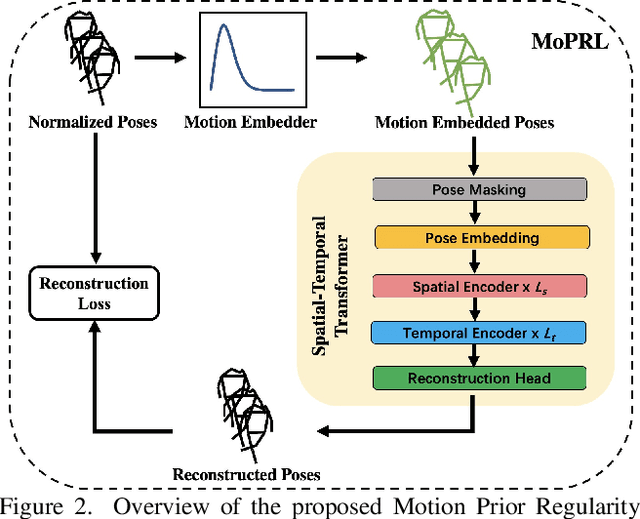

Anomaly detection in surveillance videos is challenging and important for ensuring public security. Different from pixel-based anomaly detection methods, pose-based methods utilize highly-structured skeleton data, which decreases the computational burden and also avoids the negative impact of background noise. However, unlike pixel-based methods, which could directly exploit explicit motion features such as optical flow, pose-based methods suffer from the lack of alternative dynamic representation. In this paper, a novel Motion Embedder (ME) is proposed to provide a pose motion representation from the probability perspective. Furthermore, a novel task-specific Spatial-Temporal Transformer (STT) is deployed for self-supervised pose sequence reconstruction. These two modules are then integrated into a unified framework for pose regularity learning, which is referred to as Motion Prior Regularity Learner (MoPRL). MoPRL achieves the state-of-the-art performance by an average improvement of 4.7% AUC on several challenging datasets. Extensive experiments validate the versatility of each proposed module.
Calibrated Feature Decomposition for Generalizable Person Re-Identification
Nov 27, 2021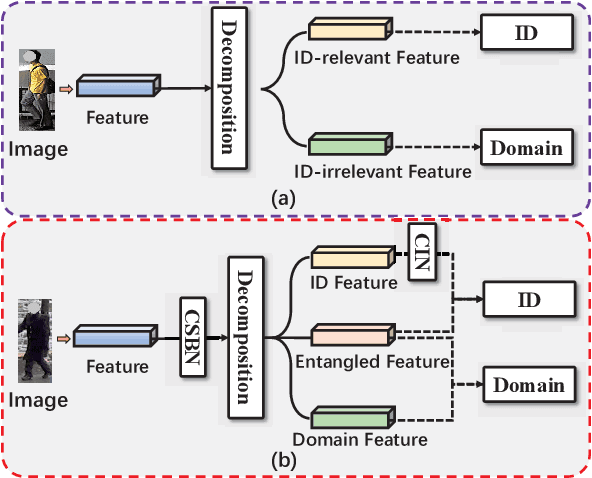
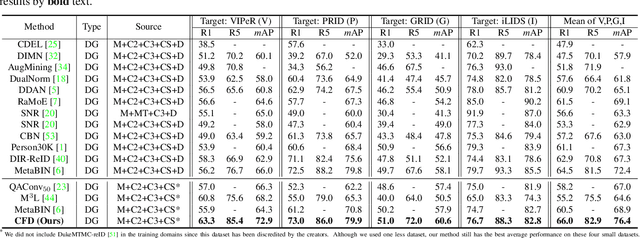
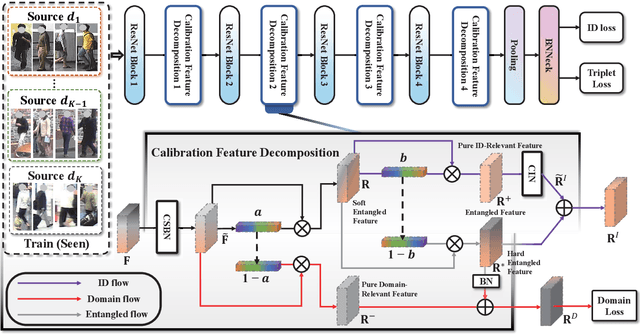
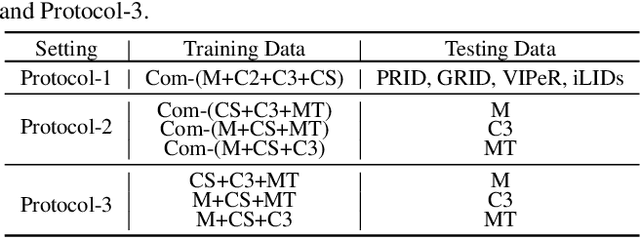
Existing disentangled-based methods for generalizable person re-identification aim at directly disentangling person representations into domain-relevant interference and identity-relevant feature. However, they ignore that some crucial characteristics are stubbornly entwined in both the domain-relevant interference and identity-relevant feature, which are intractable to decompose in an unsupervised manner. In this paper, we propose a simple yet effective Calibrated Feature Decomposition (CFD) module that focuses on improving the generalization capacity for person re-identification through a more judicious feature decomposition and reinforcement strategy. Specifically, a calibrated-and-standardized Batch normalization (CSBN) is designed to learn calibrated person representation by jointly exploring intra-domain calibration and inter-domain standardization of multi-source domain features. CSBN restricts instance-level inconsistency of feature distribution for each domain and captures intrinsic domain-level specific statistics. The calibrated person representation is subtly decomposed into the identity-relevant feature, domain feature, and the remaining entangled one. For enhancing the generalization ability and ensuring high discrimination of the identity-relevant feature, a calibrated instance normalization (CIN) is introduced to enforce discriminative id-relevant information, and filter out id-irrelevant information, and meanwhile the rich complementary clues from the remaining entangled feature are further employed to strengthen it. Extensive experiments demonstrate the strong generalization capability of our framework. Our models empowered by CFD modules significantly outperform the state-of-the-art domain generalization approaches on multiple widely-used benchmarks. Code will be made public: https://github.com/zkcys001/CFD.