 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior-Grounded Lane Representation Learning for Multi-Task Traffic Digital Twins
May 03, 2026Traffic digital twins are powerful tools for advanced traffic management, and most systems are built on static geometric representations. However, these representations fail to capture the dynamic functional semantics required for behavior-aware reasoning, such as how a lane operates under complex traffic conditions. To address this gap, we introduce GeoLaneRep, a behavior-grounded lane representation learning framework for traffic digital twins. GeoLaneRep jointly encodes static lane geometry, observed vehicle trajectories, and operational descriptors into a shared, cross-camera semantic embedding. The encoder is trained with a joint objective combining contrastive cross-camera alignment, auxiliary role supervision, and temporal anomaly detection. Across 16 roadside cameras and 132 lanes, the learned embeddings achieve a $0.004$ lateral-rank error and an edge-role F1 of $1.000$ in zero-shot cross-camera matching, and an AUROC of $0.991$ for window-level anomaly detection. We further show that the same behavioral embeddings can condition a diffusion-based generator to synthesize lane geometries that satisfy targeted operational specifications, with $87.9\%$ overall specification accuracy across 38 lane groups. GeoLaneRep thus provides a semantic interface between roadside observations and downstream digital twin tasks, supporting cross-camera transfer, behavior-aware monitoring, and goal-directed lane synthesis. The framework is openly available at https://github.com/raynbowy23/GeoLaneRep.
CrashSight: A Phase-Aware, Infrastructure-Centric Video Benchmark for Traffic Crash Scene Understanding and Reasoning
Apr 09, 2026Cooperative autonomous driving requires traffic scene understanding from both vehicle and infrastructure perspectives. While vision-language models (VLMs) show strong general reasoning capabilities, their performance in safety-critical traffic scenarios remains insufficiently evaluated due to the ego-vehicle focus of existing benchmarks. To bridge this gap, we present \textbf{CrashSight}, a large-scale vision-language benchmark for roadway crash understanding using real-world roadside camera data. The dataset comprises 250 crash videos, annotated with 13K multiple-choice question-answer pairs organized under a two-tier taxonomy. Tier 1 evaluates the visual grounding of scene context and involved parties, while Tier 2 probes higher-level reasoning, including crash mechanics, causal attribution, temporal progression, and post-crash outcomes. We benchmark 8 state-of-the-art VLMs and show that, despite strong scene description capabilities, current models struggle with temporal and causal reasoning in safety-critical scenarios. We provide a detailed analysis of failure scenarios and discuss directions for improving VLM crash understanding. The benchmark provides a standardized evaluation framework for infrastructure-assisted perception in cooperative autonomous driving. The CrashSight benchmark, including the full dataset and code, is accessible at https://mcgrche.github.io/crashsight.
V2X-QA: A Comprehensive Reasoning Dataset and Benchmark for Multimodal Large Language Models in Autonomous Driving Across Ego, Infrastructure, and Cooperative Views
Apr 03, 2026Multimodal large language models (MLLMs) have shown strong potential for autonomous driving, yet existing benchmarks remain largely ego-centric and therefore cannot systematically assess model performance in infrastructure-centric and cooperative driving conditions. In this work, we introduce V2X-QA, a real-world dataset and benchmark for evaluating MLLMs across vehicle-side, infrastructure-side, and cooperative viewpoints. V2X-QA is built around a view-decoupled evaluation protocol that enables controlled comparison under vehicle-only, infrastructure-only, and cooperative driving conditions within a unified multiple-choice question answering (MCQA) framework. The benchmark is organized into a twelve-task taxonomy spanning perception, prediction, and reasoning and planning, and is constructed through expert-verified MCQA annotation to enable fine-grained diagnosis of viewpoint-dependent capabilities. Benchmark results across ten representative state-of-the-art proprietary and open-source models show that viewpoint accessibility substantially affects performance, and infrastructure-side reasoning supports meaningful macroscopic traffic understanding. Results also indicate that cooperative reasoning remains challenging since it requires cross-view alignment and evidence integration rather than simply additional visual input. To address these challenges, we introduce V2X-MoE, a benchmark-aligned baseline with explicit view routing and viewpoint-specific LoRA experts. The strong performance of V2X-MoE further suggests that explicit viewpoint specialization is a promising direction for multi-view reasoning in autonomous driving. Overall, V2X-QA provides a foundation for studying multi-perspective reasoning, reliability, and cooperative physical intelligence in connected autonomous driving. The dataset and V2X-MoE resources are publicly available at: https://github.com/junwei0001/V2X-QA.
Order Is Not Layout: Order-to-Space Bias in Image Generation
Mar 04, 2026We study a systematic bias in modern image generation models: the mention order of entities in text spuriously determines spatial layout and entity--role binding. We term this phenomenon Order-to-Space Bias (OTS) and show that it arises in both text-to-image and image-to-image generation, often overriding grounded cues and causing incorrect layouts or swapped assignments. To quantify OTS, we introduce OTS-Bench, which isolates order effects with paired prompts differing only in entity order and evaluates models along two dimensions: homogenization and correctness. Experiments show that Order-to-Space Bias (OTS) is widespread in modern image generation models, and provide evidence that it is primarily data-driven and manifests during the early stages of layout formation. Motivated by this insight, we show that both targeted fine-tuning and early-stage intervention strategies can substantially reduce OTS, while preserving generation quality.
WS-IMUBench: Can Weakly Supervised Methods from Audio, Image, and Video Be Adapted for IMU-based Temporal Action Localization?
Feb 02, 2026IMU-based Human Activity Recognition (HAR) has enabled a wide range of ubiquitous computing applications, yet its dominant clip classification paradigm cannot capture the rich temporal structure of real-world behaviors. This motivates a shift toward IMU Temporal Action Localization (IMU-TAL), which predicts both action categories and their start/end times in continuous streams. However, current progress is strongly bottlenecked by the need for dense, frame-level boundary annotations, which are costly and difficult to scale. To address this bottleneck, we introduce WS-IMUBench, a systematic benchmark study of weakly supervised IMU-TAL (WS-IMU-TAL) under only sequence-level labels. Rather than proposing a new localization algorithm, we evaluate how well established weakly supervised localization paradigms from audio, image, and video transfer to IMU-TAL under only sequence-level labels. We benchmark seven representative weakly supervised methods on seven public IMU datasets, resulting in over 3,540 model training runs and 7,080 inference evaluations. Guided by three research questions on transferability, effectiveness, and insights, our findings show that (i) transfer is modality-dependent, with temporal-domain methods generally more stable than image-derived proposal-based approaches; (ii) weak supervision can be competitive on favorable datasets (e.g., with longer actions and higher-dimensional sensing); and (iii) dominant failure modes arise from short actions, temporal ambiguity, and proposal quality. Finally, we outline concrete directions for advancing WS-IMU-TAL (e.g., IMU-specific proposal generation, boundary-aware objectives, and stronger temporal reasoning). Beyond individual results, WS-IMUBench establishes a reproducible benchmarking template, datasets, protocols, and analyses, to accelerate community-wide progress toward scalable WS-IMU-TAL.
V2X-REALM: Vision-Language Model-Based Robust End-to-End Cooperative Autonomous Driving with Adaptive Long-Tail Modeling
Jun 26, 2025Ensuring robust planning and decision-making under rare, diverse, and visually degraded long-tail scenarios remains a fundamental challenge for autonomous driving in urban environments. This issue becomes more critical in cooperative settings, where vehicles and infrastructure jointly perceive and reason across complex environments. To address this challenge, we propose V2X-REALM, a vision-language model (VLM)-based framework with adaptive multimodal learning for robust cooperative autonomous driving under long-tail scenarios. V2X-REALM introduces three core innovations: (i) a prompt-driven long-tail scenario generation and evaluation pipeline that leverages foundation models to synthesize realistic long-tail conditions such as snow and fog across vehicle- and infrastructure-side views, enriching training diversity efficiently; (ii) a gated multi-scenario adaptive attention module that modulates the visual stream using scenario priors to recalibrate ambiguous or corrupted features; and (iii) a multi-task scenario-aware contrastive learning objective that improves multimodal alignment and promotes cross-scenario feature separability. Extensive experiments demonstrate that V2X-REALM significantly outperforms existing baselines in robustness, semantic reasoning, safety, and planning accuracy under complex, challenging driving conditions, advancing the scalability of end-to-end cooperative autonomous driving.
Sky-Drive: A Distributed Multi-Agent Simulation Platform for Socially-Aware and Human-AI Collaborative Future Transportation
Apr 25, 2025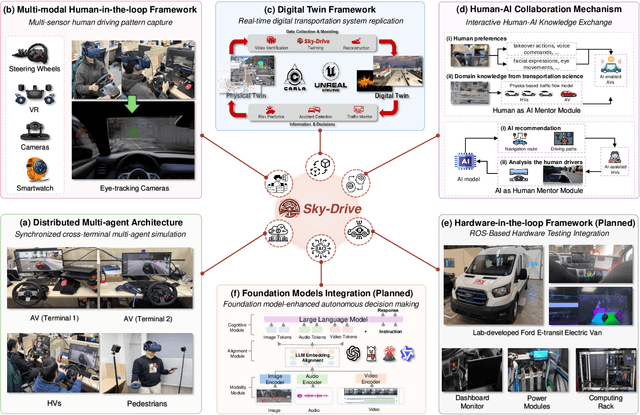
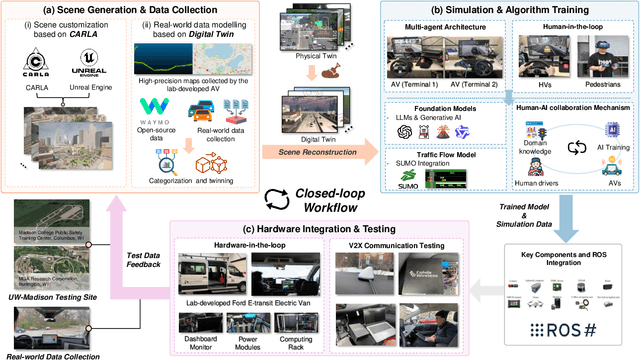
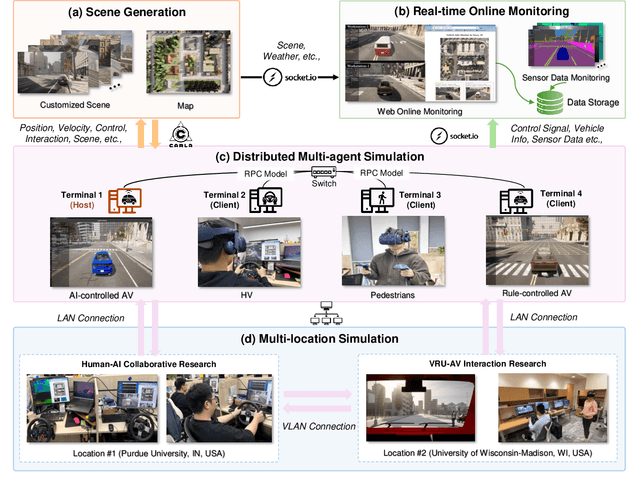
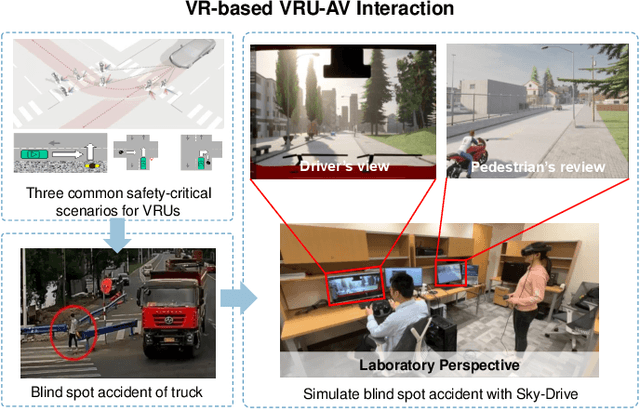
Recent advances in autonomous system simulation platforms have significantly enhanced the safe and scalable testing of driving policies. However, existing simulators do not yet fully meet the needs of future transportation research, particularly in modeling socially-aware driving agents and enabling effective human-AI collaboration. This paper introduces Sky-Drive, a novel distributed multi-agent simulation platform that addresses these limitations through four key innovations: (a) a distributed architecture for synchronized simulation across multiple terminals; (b) a multi-modal human-in-the-loop framework integrating diverse sensors to collect rich behavioral data; (c) a human-AI collaboration mechanism supporting continuous and adaptive knowledge exchange; and (d) a digital twin (DT) framework for constructing high-fidelity virtual replicas of real-world transportation environments. Sky-Drive supports diverse applications such as autonomous vehicle (AV)-vulnerable road user (VRU) interaction modeling, human-in-the-loop training, socially-aware reinforcement learning, personalized driving policy, and customized scenario generation. Future extensions will incorporate foundation models for context-aware decision support and hardware-in-the-loop (HIL) testing for real-world validation. By bridging scenario generation, data collection, algorithm training, and hardware integration, Sky-Drive has the potential to become a foundational platform for the next generation of socially-aware and human-centered autonomous transportation research. The demo video and code are available at:https://sky-lab-uw.github.io/Sky-Drive-website/
Planning Safety Trajectories with Dual-Phase, Physics-Informed, and Transportation Knowledge-Driven Large Language Models
Apr 06, 2025Foundation models have demonstrated strong reasoning and generalization capabilities in driving-related tasks, including scene understanding, planning, and control. However, they still face challenges in hallucinations, uncertainty, and long inference latency. While existing foundation models have general knowledge of avoiding collisions, they often lack transportation-specific safety knowledge. To overcome these limitations, we introduce LetsPi, a physics-informed, dual-phase, knowledge-driven framework for safe, human-like trajectory planning. To prevent hallucinations and minimize uncertainty, this hybrid framework integrates Large Language Model (LLM) reasoning with physics-informed social force dynamics. LetsPi leverages the LLM to analyze driving scenes and historical information, providing appropriate parameters and target destinations (goals) for the social force model, which then generates the future trajectory. Moreover, the dual-phase architecture balances reasoning and computational efficiency through its Memory Collection phase and Fast Inference phase. The Memory Collection phase leverages the physics-informed LLM to process and refine planning results through reasoning, reflection, and memory modules, storing safe, high-quality driving experiences in a memory bank. Surrogate safety measures and physics-informed prompt techniques are introduced to enhance the LLM's knowledge of transportation safety and physical force, respectively. The Fast Inference phase extracts similar driving experiences as few-shot examples for new scenarios, while simplifying input-output requirements to enable rapid trajectory planning without compromising safety. Extensive experiments using the HighD dataset demonstrate that LetsPi outperforms baseline models across five safety metrics.See PDF for project Github link.
V2X-LLM: Enhancing V2X Integration and Understanding in Connected Vehicle Corridors
Mar 04, 2025



The advancement of Connected and Automated Vehicles (CAVs) and Vehicle-to-Everything (V2X) offers significant potential for enhancing transportation safety, mobility, and sustainability. However, the integration and analysis of the diverse and voluminous V2X data, including Basic Safety Messages (BSMs) and Signal Phase and Timing (SPaT) data, present substantial challenges, especially on Connected Vehicle Corridors. These challenges include managing large data volumes, ensuring real-time data integration, and understanding complex traffic scenarios. Although these projects have developed an advanced CAV data pipeline that enables real-time communication between vehicles, infrastructure, and other road users for managing connected vehicle and roadside unit (RSU) data, significant hurdles in data comprehension and real-time scenario analysis and reasoning persist. To address these issues, we introduce the V2X-LLM framework, a novel enhancement to the existing CV data pipeline. V2X-LLM leverages Large Language Models (LLMs) to improve the understanding and real-time analysis of V2X data. The framework includes four key tasks: Scenario Explanation, offering detailed narratives of traffic conditions; V2X Data Description, detailing vehicle and infrastructure statuses; State Prediction, forecasting future traffic states; and Navigation Advisory, providing optimized routing instructions. By integrating LLM-driven reasoning with V2X data within the data pipeline, the V2X-LLM framework offers real-time feedback and decision support for traffic management. This integration enhances the accuracy of traffic analysis, safety, and traffic optimization. Demonstrations in a real-world urban corridor highlight the framework's potential to advance intelligent transportation systems.
XRF V2: A Dataset for Action Summarization with Wi-Fi Signals, and IMUs in Phones, Watches, Earbuds, and Glasses
Jan 31, 2025



Human Action Recognition (HAR) plays a crucial role in applications such as health monitoring, smart home automation, and human-computer interaction. While HAR has been extensively studied, action summarization, which involves identifying and summarizing continuous actions, remains an emerging task. This paper introduces the novel XRF V2 dataset, designed for indoor daily activity Temporal Action Localization (TAL) and action summarization. XRF V2 integrates multimodal data from Wi-Fi signals, IMU sensors (smartphones, smartwatches, headphones, and smart glasses), and synchronized video recordings, offering a diverse collection of indoor activities from 16 volunteers across three distinct environments. To tackle TAL and action summarization, we propose the XRFMamba neural network, which excels at capturing long-term dependencies in untrimmed sensory sequences and outperforms state-of-the-art methods, such as ActionFormer and WiFiTAD. We envision XRF V2 as a valuable resource for advancing research in human action localization, action forecasting, pose estimation, multimodal foundation models pre-training, synthetic data generation, and more.