 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFD-Bench: A Modular and Fair Benchmark for Data-driven Fluid Simulation
May 25, 2025



Data-driven modeling of fluid dynamics has advanced rapidly with neural PDE solvers, yet a fair and strong benchmark remains fragmented due to the absence of unified PDE datasets and standardized evaluation protocols. Although architectural innovations are abundant, fair assessment is further impeded by the lack of clear disentanglement between spatial, temporal and loss modules. In this paper, we introduce FD-Bench, the first fair, modular, comprehensive and reproducible benchmark for data-driven fluid simulation. FD-Bench systematically evaluates 85 baseline models across 10 representative flow scenarios under a unified experimental setup. It provides four key contributions: (1) a modular design enabling fair comparisons across spatial, temporal, and loss function modules; (2) the first systematic framework for direct comparison with traditional numerical solvers; (3) fine-grained generalization analysis across resolutions, initial conditions, and temporal windows; and (4) a user-friendly, extensible codebase to support future research. Through rigorous empirical studies, FD-Bench establishes the most comprehensive leaderboard to date, resolving long-standing issues in reproducibility and comparability, and laying a foundation for robust evaluation of future data-driven fluid models. The code is open-sourced at https://anonymous.4open.science/r/FD-Bench-15BC.
Guiding the Experts: Semantic Priors for Efficient and Focused MoE Routing
May 24, 2025Mixture-of-Experts (MoE) models have emerged as a promising direction for scaling vision architectures efficiently. Among them, Soft MoE improves training stability by assigning each token to all experts via continuous dispatch weights. However, current designs overlook the semantic structure which is implicitly encoded in these weights, resulting in suboptimal expert routing. In this paper, we discover that dispatch weights in Soft MoE inherently exhibit segmentation-like patterns but are not explicitly aligned with semantic regions. Motivated by this observation, we propose a foreground-guided enhancement strategy. Specifically, we introduce a spatially aware auxiliary loss that encourages expert activation to align with semantic foreground regions. To further reinforce this supervision, we integrate a lightweight LayerScale mechanism that improves information flow and stabilizes optimization in skip connections. Our method necessitates only minor architectural adjustments and can be seamlessly integrated into prevailing Soft MoE frameworks. Comprehensive experiments on ImageNet-1K and multiple smaller-scale classification benchmarks not only showcase consistent performance enhancements but also reveal more interpretable expert routing mechanisms.
A Wavelet-based Stereo Matching Framework for Solving Frequency Convergence Inconsistency
May 23, 2025



We find that the EPE evaluation metrics of RAFT-stereo converge inconsistently in the low and high frequency regions, resulting high frequency degradation (e.g., edges and thin objects) during the iterative process. The underlying reason for the limited performance of current iterative methods is that it optimizes all frequency components together without distinguishing between high and low frequencies. We propose a wavelet-based stereo matching framework (Wavelet-Stereo) for solving frequency convergence inconsistency. Specifically, we first explicitly decompose an image into high and low frequency components using discrete wavelet transform. Then, the high-frequency and low-frequency components are fed into two different multi-scale frequency feature extractors. Finally, we propose a novel LSTM-based high-frequency preservation update operator containing an iterative frequency adapter to provide adaptive refined high-frequency features at different iteration steps by fine-tuning the initial high-frequency features. By processing high and low frequency components separately, our framework can simultaneously refine high-frequency information in edges and low-frequency information in smooth regions, which is especially suitable for challenging scenes with fine details and textures in the distance. Extensive experiments demonstrate that our Wavelet-Stereo outperforms the state-of-the-art methods and ranks 1st on both the KITTI 2015 and KITTI 2012 leaderboards for almost all metrics. We will provide code and pre-trained models to encourage further exploration, application, and development of our innovative framework (https://github.com/SIA-IDE/Wavelet-Stereo).
Rethinking the Sampling Criteria in Reinforcement Learning for LLM Reasoning: A Competence-Difficulty Alignment Perspective
May 23, 2025


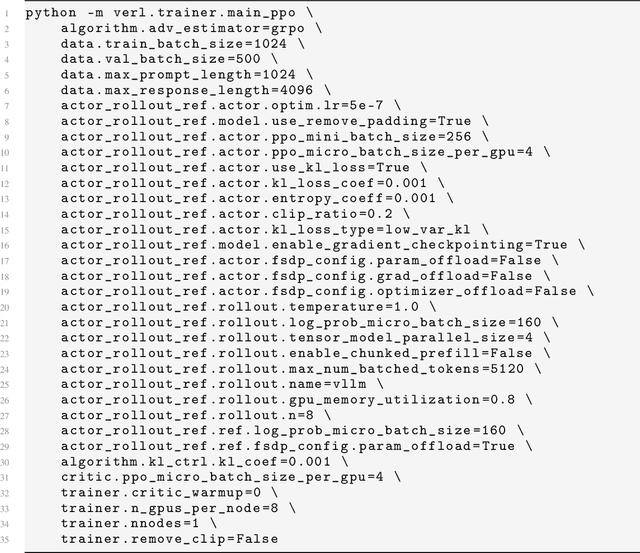
Reinforcement learning exhibits potential in enhancing the reasoning abilities of large language models, yet it is hard to scale for the low sample efficiency during the rollout phase. Existing methods attempt to improve efficiency by scheduling problems based on problem difficulties. However, these approaches suffer from unstable and biased estimations of problem difficulty and fail to capture the alignment between model competence and problem difficulty in RL training, leading to suboptimal results. To tackle these limitations, this paper introduces \textbf{C}ompetence-\textbf{D}ifficulty \textbf{A}lignment \textbf{S}ampling (\textbf{CDAS}), which enables accurate and stable estimation of problem difficulties by aggregating historical performance discrepancies of problems. Then the model competence is quantified to adaptively select problems whose difficulty is in alignment with the model's current competence using a fixed-point system. Experimental results across a range of challenging mathematical benchmarks show that CDAS achieves great improvements in both accuracy and efficiency. CDAS attains the highest average accuracy against baselines and exhibits significant speed advantages compared to Dynamic Sampling, a competitive strategy in DAPO, which is \textbf{2.33} times slower than CDAS.
DiffusionReward: Enhancing Blind Face Restoration through Reward Feedback Learning
May 23, 2025



Reward Feedback Learning (ReFL) has recently shown great potential in aligning model outputs with human preferences across various generative tasks. In this work, we introduce a ReFL framework, named DiffusionReward, to the Blind Face Restoration task for the first time. DiffusionReward effectively overcomes the limitations of diffusion-based methods, which often fail to generate realistic facial details and exhibit poor identity consistency. The core of our framework is the Face Reward Model (FRM), which is trained using carefully annotated data. It provides feedback signals that play a pivotal role in steering the optimization process of the restoration network. In particular, our ReFL framework incorporates a gradient flow into the denoising process of off-the-shelf face restoration methods to guide the update of model parameters. The guiding gradient is collaboratively determined by three aspects: (i) the FRM to ensure the perceptual quality of the restored faces; (ii) a regularization term that functions as a safeguard to preserve generative diversity; and (iii) a structural consistency constraint to maintain facial fidelity. Furthermore, the FRM undergoes dynamic optimization throughout the process. It not only ensures that the restoration network stays precisely aligned with the real face manifold, but also effectively prevents reward hacking. Experiments on synthetic and wild datasets demonstrate that our method outperforms state-of-the-art methods, significantly improving identity consistency and facial details. The source codes, data, and models are available at: https://github.com/01NeuralNinja/DiffusionReward.
Analysis on Energy Efficiency of RIS-Assisted Multiuser Downlink Near-Field Communications
May 23, 2025In this paper, we focus on the energy efficiency (EE) optimization and analysis of reconfigurable intelligent surface (RIS)-assisted multiuser downlink near-field communications. Specifically, we conduct a comprehensive study on several key factors affecting EE performance, including the number of RIS elements, the types of reconfigurable elements, reconfiguration resolutions, and the maximum transmit power. To accurately capture the power characteristics of RISs, we adopt more practical power consumption models for three commonly used reconfigurable elements in RISs: PIN diodes, varactor diodes, and radio frequency (RF) switches. These different elements may result in RIS systems exhibiting significantly different energy efficiencies (EEs), even when their spectral efficiencies (SEs) are similar. Considering discrete phases implemented at most RISs in practice, which makes their optimization NP-hard, we develop a nested alternating optimization framework to maximize EE, consisting of an outer integer-based optimization for discrete RIS phase reconfigurations and a nested non-convex optimization for continuous transmit power allocation within each iteration. Extensive comparisons with multiple benchmark schemes validate the effectiveness and efficiency of the proposed framework. Furthermore, based on the proposed optimization method, we analyze the EE performance of RISs across different key factors and identify the optimal RIS architecture yielding the highest EE.
Bridge2AI: Building A Cross-disciplinary Curriculum Towards AI-Enhanced Biomedical and Clinical Care
May 20, 2025



Objective: As AI becomes increasingly central to healthcare, there is a pressing need for bioinformatics and biomedical training systems that are personalized and adaptable. Materials and Methods: The NIH Bridge2AI Training, Recruitment, and Mentoring (TRM) Working Group developed a cross-disciplinary curriculum grounded in collaborative innovation, ethical data stewardship, and professional development within an adapted Learning Health System (LHS) framework. Results: The curriculum integrates foundational AI modules, real-world projects, and a structured mentee-mentor network spanning Bridge2AI Grand Challenges and the Bridge Center. Guided by six learner personas, the program tailors educational pathways to individual needs while supporting scalability. Discussion: Iterative refinement driven by continuous feedback ensures that content remains responsive to learner progress and emerging trends. Conclusion: With over 30 scholars and 100 mentors engaged across North America, the TRM model demonstrates how adaptive, persona-informed training can build interdisciplinary competencies and foster an integrative, ethically grounded AI education in biomedical contexts.
Enhancing Knowledge Graph Completion with GNN Distillation and Probabilistic Interaction Modeling
May 18, 2025Knowledge graphs (KGs) serve as fundamental structures for organizing interconnected data across diverse domains. However, most KGs remain incomplete, limiting their effectiveness in downstream applications. Knowledge graph completion (KGC) aims to address this issue by inferring missing links, but existing methods face critical challenges: deep graph neural networks (GNNs) suffer from over-smoothing, while embedding-based models fail to capture abstract relational features. This study aims to overcome these limitations by proposing a unified framework that integrates GNN distillation and abstract probabilistic interaction modeling (APIM). GNN distillation approach introduces an iterative message-feature filtering process to mitigate over-smoothing, preserving the discriminative power of node representations. APIM module complements this by learning structured, abstract interaction patterns through probabilistic signatures and transition matrices, allowing for a richer, more flexible representation of entity and relation interactions. We apply these methods to GNN-based models and the APIM to embedding-based KGC models, conducting extensive evaluations on the widely used WN18RR and FB15K-237 datasets. Our results demonstrate significant performance gains over baseline models, showcasing the effectiveness of the proposed techniques. The findings highlight the importance of both controlling information propagation and leveraging structured probabilistic modeling, offering new avenues for advancing knowledge graph completion. And our codes are available at https://anonymous.4open.science/r/APIM_and_GNN-Distillation-461C.
Redefining Neural Operators in $d+1$ Dimensions
May 17, 2025Neural Operators have emerged as powerful tools for learning mappings between function spaces. Among them, the kernel integral operator has been widely validated on universally approximating various operators. Although recent advancements following this definition have developed effective modules to better approximate the kernel function defined on the original domain (with $d$ dimensions, $d=1, 2, 3...$), the unclarified evolving mechanism in the embedding spaces blocks our view to design neural operators that can fully capture the target system evolution. Drawing on recent breakthroughs in quantum simulation of partial differential equations (PDEs), we elucidate the linear evolution process in neural operators. Based on that, we redefine neural operators on a new $d+1$ dimensional domain. Within this framework, we implement our proposed Schr\"odingerised Kernel Neural Operator (SKNO) aligning better with the $d+1$ dimensional evolution. In experiments, our $d+1$ dimensional evolving linear block performs far better than others. Also, we test SKNO's SOTA performance on various benchmark tests and also the zero-shot super-resolution task. In addition, we analyse the impact of different lifting and recovering operators on the prediction within the redefined NO framework, reflecting the alignment between our model and the underlying $d+1$ dimensional evolution.
Seasonal Forecasting of Pan-Arctic Sea Ice with State Space Model
May 15, 2025The rapid decline of Arctic sea ice resulting from anthropogenic climate change poses significant risks to indigenous communities, ecosystems, and the global climate system. This situation emphasizes the immediate necessity for precise seasonal sea ice forecasts. While dynamical models perform well for short-term forecasts, they encounter limitations in long-term forecasts and are computationally intensive. Deep learning models, while more computationally efficient, often have difficulty managing seasonal variations and uncertainties when dealing with complex sea ice dynamics. In this research, we introduce IceMamba, a deep learning architecture that integrates sophisticated attention mechanisms within the state space model. Through comparative analysis of 25 renowned forecast models, including dynamical, statistical, and deep learning approaches, our experimental results indicate that IceMamba delivers excellent seasonal forecasting capabilities for Pan-Arctic sea ice concentration. Specifically, IceMamba outperforms all tested models regarding average RMSE and anomaly correlation coefficient (ACC) and ranks second in Integrated Ice Edge Error (IIEE). This innovative approach enhances our ability to foresee and alleviate the effects of sea ice variability, offering essential insights for strategies aimed at climate adaptation.
* This paper is published in npj Climate and Atmospheric Science: https://www.nature.com/articles/s41612-025-01058-0#Sec16 Supplementary information: https://static-content.springer.com/esm/art%3A10.1038%2Fs41612-025-01058-0/MediaObjects/41612_2025_1058_MOESM1_ESM.pdf