 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeVideoFormer: An Efficient Spike-Driven Video Transformer with Hamming Attention and $\mathcal{O}(T)$ Complexity
May 15, 2025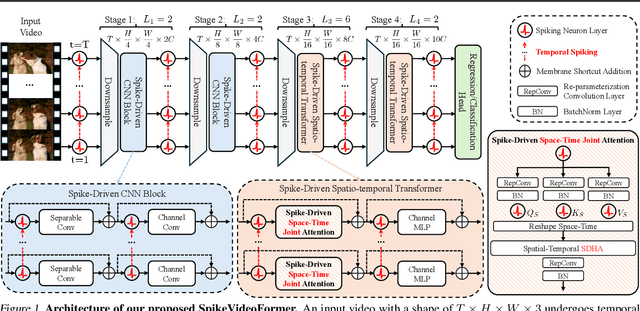
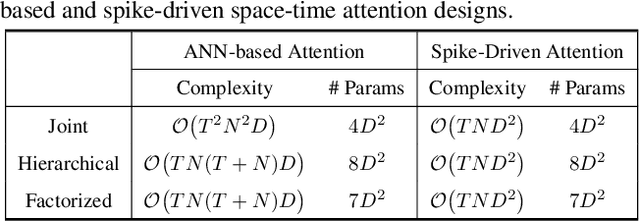

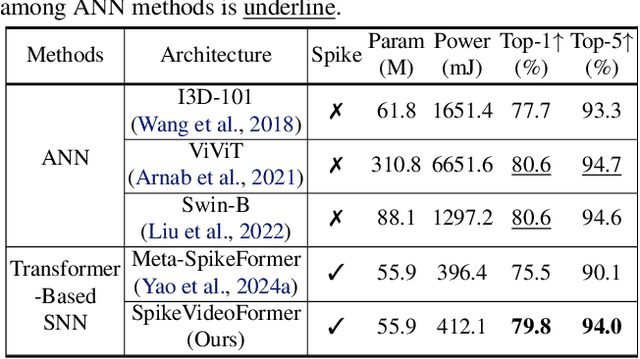
Spiking Neural Networks (SNNs) have shown competitive performance to Artificial Neural Networks (ANNs) in various vision tasks, while offering superior energy efficiency. However, existing SNN-based Transformers primarily focus on single-image tasks, emphasizing spatial features while not effectively leveraging SNNs' efficiency in video-based vision tasks. In this paper, we introduce SpikeVideoFormer, an efficient spike-driven video Transformer, featuring linear temporal complexity $\mathcal{O}(T)$. Specifically, we design a spike-driven Hamming attention (SDHA) which provides a theoretically guided adaptation from traditional real-valued attention to spike-driven attention. Building on SDHA, we further analyze various spike-driven space-time attention designs and identify an optimal scheme that delivers appealing performance for video tasks, while maintaining only linear temporal complexity. The generalization ability and efficiency of our model are demonstrated across diverse downstream video tasks, including classification, human pose tracking, and semantic segmentation. Empirical results show our method achieves state-of-the-art (SOTA) performance compared to existing SNN approaches, with over 15\% improvement on the latter two tasks. Additionally, it matches the performance of recent ANN-based methods while offering significant efficiency gains, achieving $\times 16$, $\times 10$ and $\times 5$ improvements on the three tasks. https://github.com/JimmyZou/SpikeVideoFormer
Learning Fine-grained Domain Generalization via Hyperbolic State Space Hallucination
Apr 10, 2025Fine-grained domain generalization (FGDG) aims to learn a fine-grained representation that can be well generalized to unseen target domains when only trained on the source domain data. Compared with generic domain generalization, FGDG is particularly challenging in that the fine-grained category can be only discerned by some subtle and tiny patterns. Such patterns are particularly fragile under the cross-domain style shifts caused by illumination, color and etc. To push this frontier, this paper presents a novel Hyperbolic State Space Hallucination (HSSH) method. It consists of two key components, namely, state space hallucination (SSH) and hyperbolic manifold consistency (HMC). SSH enriches the style diversity for the state embeddings by firstly extrapolating and then hallucinating the source images. Then, the pre- and post- style hallucinate state embeddings are projected into the hyperbolic manifold. The hyperbolic state space models the high-order statistics, and allows a better discernment of the fine-grained patterns. Finally, the hyperbolic distance is minimized, so that the impact of style variation on fine-grained patterns can be eliminated. Experiments on three FGDG benchmarks demonstrate its state-of-the-art performance.
DGFamba: Learning Flow Factorized State Space for Visual Domain Generalization
Apr 10, 2025Domain generalization aims to learn a representation from the source domain, which can be generalized to arbitrary unseen target domains. A fundamental challenge for visual domain generalization is the domain gap caused by the dramatic style variation whereas the image content is stable. The realm of selective state space, exemplified by VMamba, demonstrates its global receptive field in representing the content. However, the way exploiting the domain-invariant property for selective state space is rarely explored. In this paper, we propose a novel Flow Factorized State Space model, dubbed as DG-Famba, for visual domain generalization. To maintain domain consistency, we innovatively map the style-augmented and the original state embeddings by flow factorization. In this latent flow space, each state embedding from a certain style is specified by a latent probability path. By aligning these probability paths in the latent space, the state embeddings are able to represent the same content distribution regardless of the style differences. Extensive experiments conducted on various visual domain generalization settings show its state-of-the-art performance.
DefMamba: Deformable Visual State Space Model
Apr 08, 2025



Recently, state space models (SSM), particularly Mamba, have attracted significant attention from scholars due to their ability to effectively balance computational efficiency and performance. However, most existing visual Mamba methods flatten images into 1D sequences using predefined scan orders, which results the model being less capable of utilizing the spatial structural information of the image during the feature extraction process. To address this issue, we proposed a novel visual foundation model called DefMamba. This model includes a multi-scale backbone structure and deformable mamba (DM) blocks, which dynamically adjust the scanning path to prioritize important information, thus enhancing the capture and processing of relevant input features. By combining a deformable scanning(DS) strategy, this model significantly improves its ability to learn image structures and detects changes in object details. Numerous experiments have shown that DefMamba achieves state-of-the-art performance in various visual tasks, including image classification, object detection, instance segmentation, and semantic segmentation. The code is open source on DefMamba.
Anatomically and Metabolically Informed Diffusion for Unified Denoising and Segmentation in Low-Count PET Imaging
Mar 17, 2025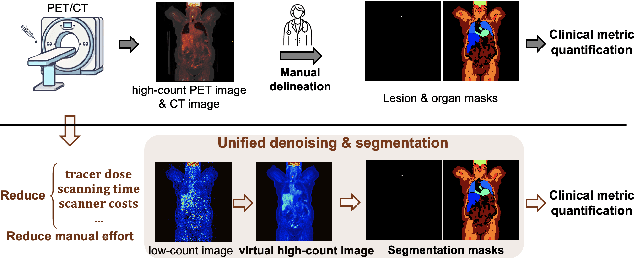
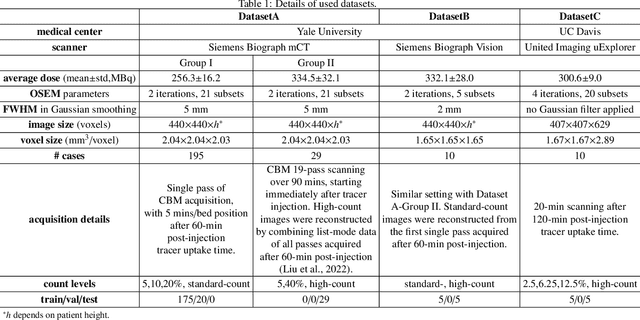
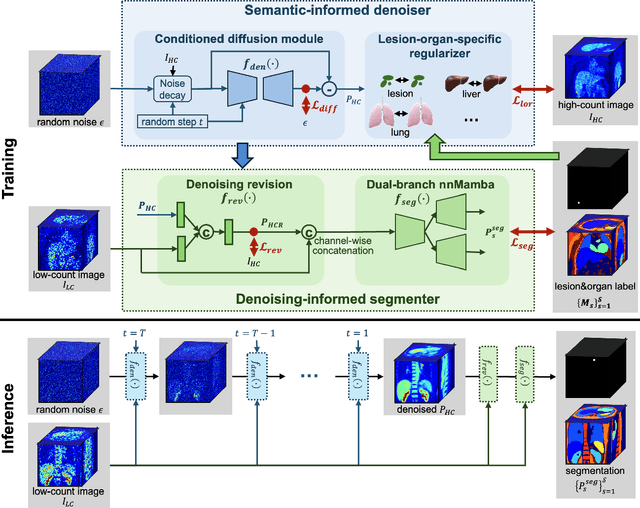
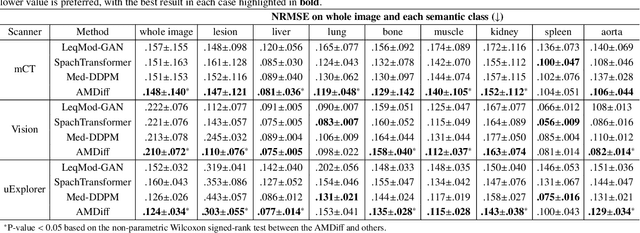
Positron emission tomography (PET) image denoising, along with lesion and organ segmentation, are critical steps in PET-aided diagnosis. However, existing methods typically treat these tasks independently, overlooking inherent synergies between them as correlated steps in the analysis pipeline. In this work, we present the anatomically and metabolically informed diffusion (AMDiff) model, a unified framework for denoising and lesion/organ segmentation in low-count PET imaging. By integrating multi-task functionality and exploiting the mutual benefits of these tasks, AMDiff enables direct quantification of clinical metrics, such as total lesion glycolysis (TLG), from low-count inputs. The AMDiff model incorporates a semantic-informed denoiser based on diffusion strategy and a denoising-informed segmenter utilizing nnMamba architecture. The segmenter constrains denoised outputs via a lesion-organ-specific regularizer, while the denoiser enhances the segmenter by providing enriched image information through a denoising revision module. These components are connected via a warming-up mechanism to optimize multitask interactions. Experiments on multi-vendor, multi-center, and multi-noise-level datasets demonstrate the superior performance of AMDiff. For test cases below 20% of the clinical count levels from participating sites, AMDiff achieves TLG quantification biases of -26.98%, outperforming its ablated versions which yield biases of -35.85% (without the lesion-organ-specific regularizer) and -40.79% (without the denoising revision module).
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
TAIL: Text-Audio Incremental Learning
Mar 06, 2025Many studies combine text and audio to capture multi-modal information but they overlook the model's generalization ability on new datasets. Introducing new datasets may affect the feature space of the original dataset, leading to catastrophic forgetting. Meanwhile, large model parameters can significantly impact training performance. To address these limitations, we introduce a novel task called Text-Audio Incremental Learning (TAIL) task for text-audio retrieval, and propose a new method, PTAT, Prompt Tuning for Audio-Text incremental learning. This method utilizes prompt tuning to optimize the model parameters while incorporating an audio-text similarity and feature distillation module to effectively mitigate catastrophic forgetting. We benchmark our method and previous incremental learning methods on AudioCaps, Clotho, BBC Sound Effects and Audioset datasets, and our method outperforms previous methods significantly, particularly demonstrating stronger resistance to forgetting on older datasets. Compared to the full-parameters Finetune (Sequential) method, our model only requires 2.42\% of its parameters, achieving 4.46\% higher performance.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
A Generalizable 3D Diffusion Framework for Low-Dose and Few-View Cardiac SPECT
Dec 21, 2024Myocardial perfusion imaging using SPECT is widely utilized to diagnose coronary artery diseases, but image quality can be negatively affected in low-dose and few-view acquisition settings. Although various deep learning methods have been introduced to improve image quality from low-dose or few-view SPECT data, previous approaches often fail to generalize across different acquisition settings, limiting their applicability in reality. This work introduced DiffSPECT-3D, a diffusion framework for 3D cardiac SPECT imaging that effectively adapts to different acquisition settings without requiring further network re-training or fine-tuning. Using both image and projection data, a consistency strategy is proposed to ensure that diffusion sampling at each step aligns with the low-dose/few-view projection measurements, the image data, and the scanner geometry, thus enabling generalization to different low-dose/few-view settings. Incorporating anatomical spatial information from CT and total variation constraint, we proposed a 2.5D conditional strategy to allow the DiffSPECT-3D to observe 3D contextual information from the entire image volume, addressing the 3D memory issues in diffusion model. We extensively evaluated the proposed method on 1,325 clinical 99mTc tetrofosmin stress/rest studies from 795 patients. Each study was reconstructed into 5 different low-count and 5 different few-view levels for model evaluations, ranging from 1% to 50% and from 1 view to 9 view, respectively. Validated against cardiac catheterization results and diagnostic comments from nuclear cardiologists, the presented results show the potential to achieve low-dose and few-view SPECT imaging without compromising clinical performance. Additionally, DiffSPECT-3D could be directly applied to full-dose SPECT images to further improve image quality, especially in a low-dose stress-first cardiac SPECT imaging protocol.
MoTe: Learning Motion-Text Diffusion Model for Multiple Generation Tasks
Nov 29, 2024



Recently, human motion analysis has experienced great improvement due to inspiring generative models such as the denoising diffusion model and large language model. While the existing approaches mainly focus on generating motions with textual descriptions and overlook the reciprocal task. In this paper, we present~\textbf{MoTe}, a unified multi-modal model that could handle diverse tasks by learning the marginal, conditional, and joint distributions of motion and text simultaneously. MoTe enables us to handle the paired text-motion generation, motion captioning, and text-driven motion generation by simply modifying the input context. Specifically, MoTe is composed of three components: Motion Encoder-Decoder (MED), Text Encoder-Decoder (TED), and Moti-on-Text Diffusion Model (MTDM). In particular, MED and TED are trained for extracting latent embeddings, and subsequently reconstructing the motion sequences and textual descriptions from the extracted embeddings, respectively. MTDM, on the other hand, performs an iterative denoising process on the input context to handle diverse tasks. Experimental results on the benchmark datasets demonstrate the superior performance of our proposed method on text-to-motion generation and competitive performance on motion captioning.