 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICDAR 2023 Competition on Structured Text Extraction from Visually-Rich Document Images
Jun 05, 2023Structured text extraction is one of the most valuable and challenging application directions in the field of Document AI. However, the scenarios of past benchmarks are limited, and the corresponding evaluation protocols usually focus on the submodules of the structured text extraction scheme. In order to eliminate these problems, we organized the ICDAR 2023 competition on Structured text extraction from Visually-Rich Document images (SVRD). We set up two tracks for SVRD including Track 1: HUST-CELL and Track 2: Baidu-FEST, where HUST-CELL aims to evaluate the end-to-end performance of Complex Entity Linking and Labeling, and Baidu-FEST focuses on evaluating the performance and generalization of Zero-shot / Few-shot Structured Text extraction from an end-to-end perspective. Compared to the current document benchmarks, our two tracks of competition benchmark enriches the scenarios greatly and contains more than 50 types of visually-rich document images (mainly from the actual enterprise applications). The competition opened on 30th December, 2022 and closed on 24th March, 2023. There are 35 participants and 91 valid submissions received for Track 1, and 15 participants and 26 valid submissions received for Track 2. In this report we will presents the motivation, competition datasets, task definition, evaluation protocol, and submission summaries. According to the performance of the submissions, we believe there is still a large gap on the expected information extraction performance for complex and zero-shot scenarios. It is hoped that this competition will attract many researchers in the field of CV and NLP, and bring some new thoughts to the field of Document AI.
SelFLoc: Selective Feature Fusion for Large-scale Point Cloud-based Place Recognition
Jun 05, 2023



Point cloud-based place recognition is crucial for mobile robots and autonomous vehicles, especially when the global positioning sensor is not accessible. LiDAR points are scattered on the surface of objects and buildings, which have strong shape priors along different axes. To enhance message passing along particular axes, Stacked Asymmetric Convolution Block (SACB) is designed, which is one of the main contributions in this paper. Comprehensive experiments demonstrate that asymmetric convolution and its corresponding strategies employed by SACB can contribute to the more effective representation of point cloud feature. On this basis, Selective Feature Fusion Block (SFFB), which is formed by stacking point- and channel-wise gating layers in a predefined sequence, is proposed to selectively boost salient local features in certain key regions, as well as to align the features before fusion phase. SACBs and SFFBs are combined to construct a robust and accurate architecture for point cloud-based place recognition, which is termed SelFLoc. Comparative experimental results show that SelFLoc achieves the state-of-the-art (SOTA) performance on the Oxford and other three in-house benchmarks with an improvement of 1.6 absolute percentages on mean average recall@1.
Visual Information Extraction in the Wild: Practical Dataset and End-to-end Solution
May 12, 2023



Visual information extraction (VIE), which aims to simultaneously perform OCR and information extraction in a unified framework, has drawn increasing attention due to its essential role in various applications like understanding receipts, goods, and traffic signs. However, as existing benchmark datasets for VIE mainly consist of document images without the adequate diversity of layout structures, background disturbs, and entity categories, they cannot fully reveal the challenges of real-world applications. In this paper, we propose a large-scale dataset consisting of camera images for VIE, which contains not only the larger variance of layout, backgrounds, and fonts but also much more types of entities. Besides, we propose a novel framework for end-to-end VIE that combines the stages of OCR and information extraction in an end-to-end learning fashion. Different from the previous end-to-end approaches that directly adopt OCR features as the input of an information extraction module, we propose to use contrastive learning to narrow the semantic gap caused by the difference between the tasks of OCR and information extraction. We evaluate the existing end-to-end methods for VIE on the proposed dataset and observe that the performance of these methods has a distinguishable drop from SROIE (a widely used English dataset) to our proposed dataset due to the larger variance of layout and entities. These results demonstrate our dataset is more practical for promoting advanced VIE algorithms. In addition, experiments demonstrate that the proposed VIE method consistently achieves the obvious performance gains on the proposed and SROIE datasets.
SOOD: Towards Semi-Supervised Oriented Object Detection
Apr 10, 2023



Semi-Supervised Object Detection (SSOD), aiming to explore unlabeled data for boosting object detectors, has become an active task in recent years. However, existing SSOD approaches mainly focus on horizontal objects, leaving multi-oriented objects that are common in aerial images unexplored. This paper proposes a novel Semi-supervised Oriented Object Detection model, termed SOOD, built upon the mainstream pseudo-labeling framework. Towards oriented objects in aerial scenes, we design two loss functions to provide better supervision. Focusing on the orientations of objects, the first loss regularizes the consistency between each pseudo-label-prediction pair (includes a prediction and its corresponding pseudo label) with adaptive weights based on their orientation gap. Focusing on the layout of an image, the second loss regularizes the similarity and explicitly builds the many-to-many relation between the sets of pseudo-labels and predictions. Such a global consistency constraint can further boost semi-supervised learning. Our experiments show that when trained with the two proposed losses, SOOD surpasses the state-of-the-art SSOD methods under various settings on the DOTA-v1.5 benchmark. The code will be available at https://github.com/HamPerdredes/SOOD.
I$^2$-SDF: Intrinsic Indoor Scene Reconstruction and Editing via Raytracing in Neural SDFs
Mar 29, 2023



In this work, we present I$^2$-SDF, a new method for intrinsic indoor scene reconstruction and editing using differentiable Monte Carlo raytracing on neural signed distance fields (SDFs). Our holistic neural SDF-based framework jointly recovers the underlying shapes, incident radiance and materials from multi-view images. We introduce a novel bubble loss for fine-grained small objects and error-guided adaptive sampling scheme to largely improve the reconstruction quality on large-scale indoor scenes. Further, we propose to decompose the neural radiance field into spatially-varying material of the scene as a neural field through surface-based, differentiable Monte Carlo raytracing and emitter semantic segmentations, which enables physically based and photorealistic scene relighting and editing applications. Through a number of qualitative and quantitative experiments, we demonstrate the superior quality of our method on indoor scene reconstruction, novel view synthesis, and scene editing compared to state-of-the-art baselines.
Turning a CLIP Model into a Scene Text Detector
Mar 01, 2023The recent large-scale Contrastive Language-Image Pretraining (CLIP) model has shown great potential in various downstream tasks via leveraging the pretrained vision and language knowledge. Scene text, which contains rich textual and visual information, has an inherent connection with a model like CLIP. Recently, pretraining approaches based on vision language models have made effective progresses in the field of text detection. In contrast to these works, this paper proposes a new method, termed TCM, focusing on Turning the CLIP Model directly for text detection without pretraining process. We demonstrate the advantages of the proposed TCM as follows: (1) The underlying principle of our framework can be applied to improve existing scene text detector. (2) It facilitates the few-shot training capability of existing methods, e.g., by using 10% of labeled data, we significantly improve the performance of the baseline method with an average of 22% in terms of the F-measure on 4 benchmarks. (3) By turning the CLIP model into existing scene text detection methods, we further achieve promising domain adaptation ability. The code will be publicly released at https://github.com/wenwenyu/TCM.
Dynamic Speed Guidance for CAV Ramp Merging in Non-Cooperative Environment: An On-Site Experiment
Dec 21, 2022Ramp merging is a typical application of cooperative intelligent transportation system (C-ITS). Vehicle trajectories perceived by roadside sensors are importation complement to the limited visual field of on-board perception. Vehicle tracking and trajectory denoising algorithm is proposed in this paper to take full advantage of roadside cameras for vehicle trajectory and speed profile estimation. Dynamic speed guidance algorithm is proposed to help on-ramp vehicles to merge into mainline smoothly, even in non-cooperative environment where mainline vehicles are not expected to slow down to accommodate on-ramp vehicles. On-site experiments were taken out in a merging area of Hangzhou Belt Highway to testify our prototype system, and simulation analysis shows our proposed algorithm can achieve significant fuel savings during the ramp merging process.
SASFormer: Transformers for Sparsely Annotated Semantic Segmentation
Dec 06, 2022



Semantic segmentation based on sparse annotation has advanced in recent years. It labels only part of each object in the image, leaving the remainder unlabeled. Most of the existing approaches are time-consuming and often necessitate a multi-stage training strategy. In this work, we propose a simple yet effective sparse annotated semantic segmentation framework based on segformer, dubbed SASFormer, that achieves remarkable performance. Specifically, the framework first generates hierarchical patch attention maps, which are then multiplied by the network predictions to produce correlated regions separated by valid labels. Besides, we also introduce the affinity loss to ensure consistency between the features of correlation results and network predictions. Extensive experiments showcase that our proposed approach is superior to existing methods and achieves cutting-edge performance. The source code is available at \url{https://github.com/su-hui-zz/SASFormer}.
PriorLane: A Prior Knowledge Enhanced Lane Detection Approach Based on Transformer
Sep 15, 2022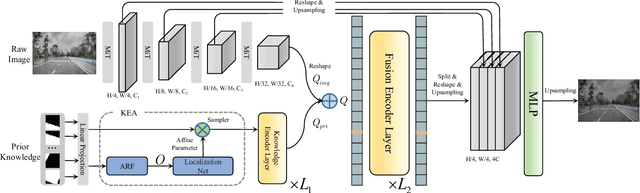
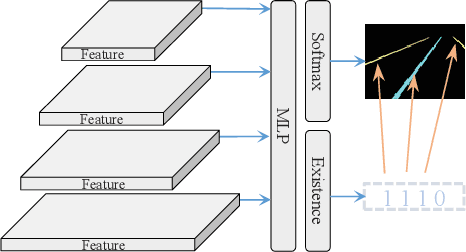

Lane detection is one of the fundamental modules in self-driving. In this paper we employ a transformer-only method for lane detection, thus it could benefit from the blooming development of fully vision transformer and achieves the state-of-the-art (SOTA) performance on both CULane and TuSimple benchmarks, by fine-tuning the weight fully pre-trained on large datasets. More importantly, this paper proposes a novel and general framework called PriorLane, which is used to enhance the segmentation performance of the fully vision transformer by introducing the low-cost local prior knowledge. PriorLane utilizes an encoder-only transformer to fuse the feature extracted by a pre-trained segmentation model with prior knowledge embeddings. Note that a Knowledge Embedding Alignment (KEA) module is adapted to enhance the fusion performance by aligning the knowledge embedding. Extensive experiments on our Zjlab dataset show that Prior-Lane outperforms SOTA lane detection methods by a 2.82% mIoU, and the code will be released at: https://github. com/vincentqqb/PriorLane.
CVR-LSE: Compact Vectorization Representation of Local Static Environments for Unmanned Ground Vehicles
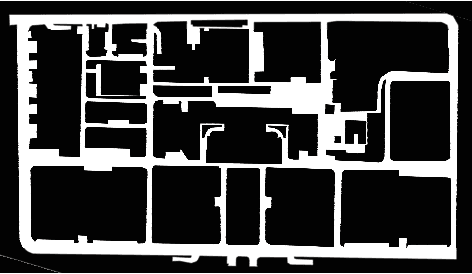
Jun 14, 2022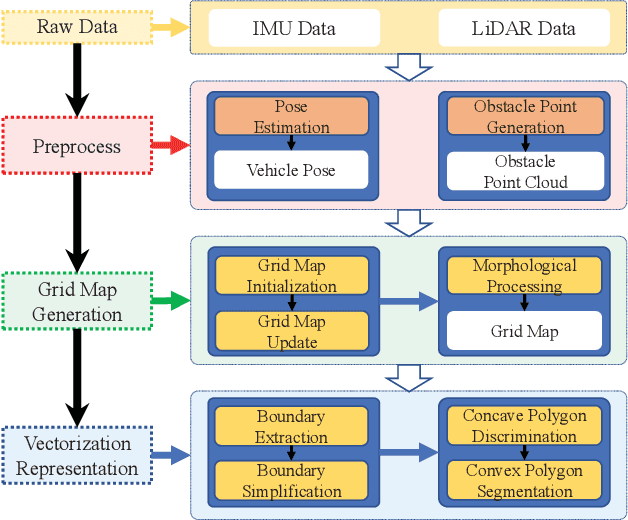
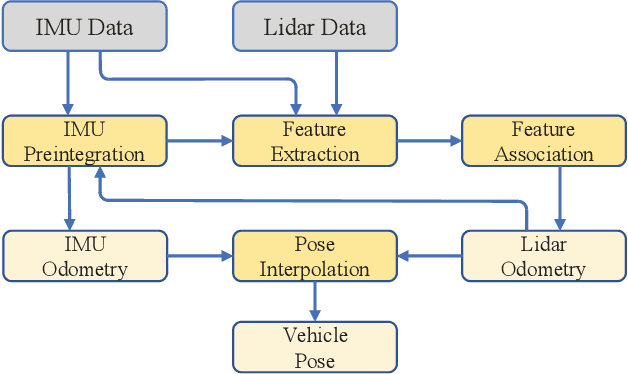
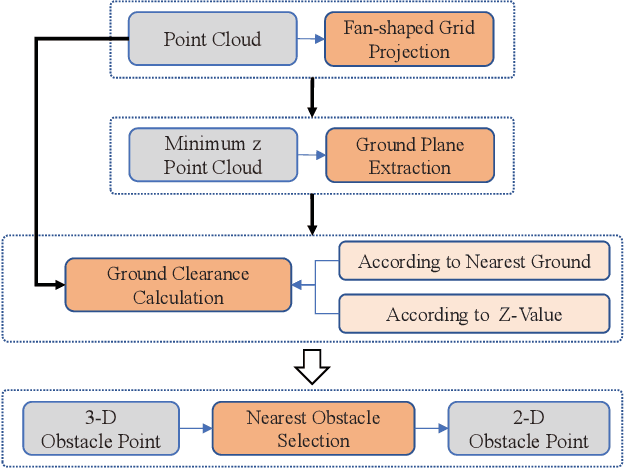
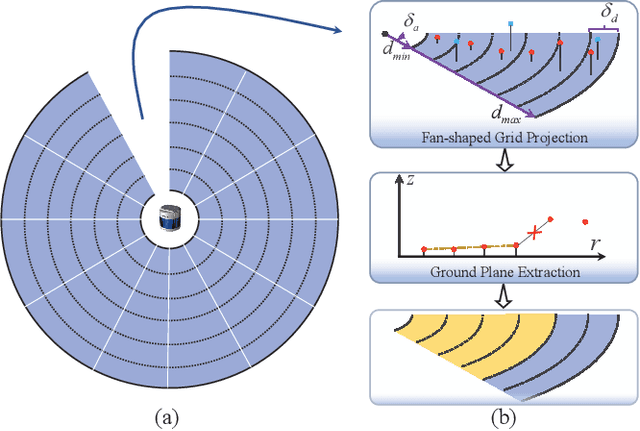
According to the requirement of general static obstacle detection, this paper proposes a compact vectorization representation approach of local static environments for unmanned ground vehicles. At first, by fusing the data of LiDAR and IMU, high-frequency pose information is obtained. Then, through the two-dimensional (2D) obstacle points generation, the process of grid map maintenance with a fixed size is proposed. Finally, the local static environment is described via multiple convex polygons, which is realized throungh the double threshold-based boundary simplification and the convex polygon segmentation. Our proposed approach has been applied in a practical driverless project in the park, and the qualitative experimental results on typical scenes verify the effectiveness and robustness. In addition, the quantitative evaluation shows the superior performance on making use of fewer number of points information (decreased by about 60%) to represent the local static environment compared with the traditional grid map-based methods. Furthermore, the performance of running time (15ms) shows that the proposed approach can be used for real-time local static environment perception. The corresponding code can be accessed at https://github.com/ghm0819/cvr_lse.