 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Heads Matter: A Head-Level KV Cache Compression Method with Integrated Retrieval and Reasoning
Oct 28, 2024



Key-Value (KV) caching is a common technique to enhance the computational efficiency of Large Language Models (LLMs), but its memory overhead grows rapidly with input length. Prior work has shown that not all tokens are equally important for text generation, proposing layer-level KV cache compression to selectively retain key information. Recognizing the distinct roles of attention heads in generation, we propose HeadKV, a head-level KV cache compression method, and HeadKV-R2, which leverages a novel contextual reasoning ability estimation for compression. Our approach operates at the level of individual heads, estimating their importance for contextual QA tasks that require both retrieval and reasoning capabilities. Extensive experiments across diverse benchmarks (LongBench, LooGLE), model architectures (e.g., Llama-3-8B-Instruct, Mistral-7B-Instruct), and long-context abilities tests demonstrate that our head-level KV cache compression significantly outperforms strong baselines, particularly in low-resource settings (KV size = 64 & 128). Notably, our method retains just 1.5% of the KV cache while achieving 97% of the performance of the full KV cache on the contextual question answering benchmark.
Integrative Decoding: Improve Factuality via Implicit Self-consistency
Oct 02, 2024



Self-consistency-based approaches, which involve repeatedly sampling multiple outputs and selecting the most consistent one as the final response, prove to be remarkably effective in improving the factual accuracy of large language models. Nonetheless, existing methods usually have strict constraints on the task format, largely limiting their applicability. In this paper, we present Integrative Decoding (ID), to unlock the potential of self-consistency in open-ended generation tasks. ID operates by constructing a set of inputs, each prepended with a previously sampled response, and then processes them concurrently, with the next token being selected by aggregating of all their corresponding predictions at each decoding step. In essence, this simple approach implicitly incorporates self-consistency in the decoding objective. Extensive evaluation shows that ID consistently enhances factuality over a wide range of language models, with substantial improvements on the TruthfulQA (+11.2%), Biographies (+15.4%) and LongFact (+8.5%) benchmarks. The performance gains amplify progressively as the number of sampled responses increases, indicating the potential of ID to scale up with repeated sampling.
Developing a Reliable, General-Purpose Hallucination Detection and Mitigation Service: Insights and Lessons Learned
Jul 22, 2024



Hallucination, a phenomenon where large language models (LLMs) produce output that is factually incorrect or unrelated to the input, is a major challenge for LLM applications that require accuracy and dependability. In this paper, we introduce a reliable and high-speed production system aimed at detecting and rectifying the hallucination issue within LLMs. Our system encompasses named entity recognition (NER), natural language inference (NLI), span-based detection (SBD), and an intricate decision tree-based process to reliably detect a wide range of hallucinations in LLM responses. Furthermore, our team has crafted a rewriting mechanism that maintains an optimal mix of precision, response time, and cost-effectiveness. We detail the core elements of our framework and underscore the paramount challenges tied to response time, availability, and performance metrics, which are crucial for real-world deployment of these technologies. Our extensive evaluation, utilizing offline data and live production traffic, confirms the efficacy of our proposed framework and service.
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Jun 04, 2024



In this study, we investigate whether attention-based information flow inside large language models (LLMs) is aggregated through noticeable patterns for long context processing. Our observations reveal that LLMs aggregate information through Pyramidal Information Funneling where attention is scattering widely in lower layers, progressively consolidating within specific contexts, and ultimately focusin on critical tokens (a.k.a massive activation or attention sink) in higher layers. Motivated by these insights, we developed PyramidKV, a novel and effective KV cache compression method. This approach dynamically adjusts the KV cache size across different layers, allocating more cache in lower layers and less in higher ones, diverging from traditional methods that maintain a uniform KV cache size. Our experimental evaluations, utilizing the LongBench benchmark, show that PyramidKV matches the performance of models with a full KV cache while retaining only 12% of the KV cache, thus significantly reducing memory usage. In scenarios emphasizing memory efficiency, where only 0.7% of the KV cache is maintained, PyramidKV surpasses other KV cache compression techniques achieving up to a 20.5 absolute accuracy improvement on TREC.
Interactive Editing for Text Summarization
Jun 05, 2023



Summarizing lengthy documents is a common and essential task in our daily lives. Although recent advancements in neural summarization models can assist in crafting general-purpose summaries, human writers often have specific requirements that call for a more customized approach. To address this need, we introduce REVISE (Refinement and Editing via Iterative Summarization Enhancement), an innovative framework designed to facilitate iterative editing and refinement of draft summaries by human writers. Within our framework, writers can effortlessly modify unsatisfactory segments at any location or length and provide optional starting phrases -- our system will generate coherent alternatives that seamlessly integrate with the existing summary. At its core, REVISE incorporates a modified fill-in-the-middle model with the encoder-decoder architecture while developing novel evaluation metrics tailored for the summarization task. In essence, our framework empowers users to create high-quality, personalized summaries by effectively harnessing both human expertise and AI capabilities, ultimately transforming the summarization process into a truly collaborative and adaptive experience.
Momentum Calibration for Text Generation
Dec 08, 2022The input and output of most text generation tasks can be transformed to two sequences of tokens and they can be modeled using sequence-to-sequence learning modeling tools such as Transformers. These models are usually trained by maximizing the likelihood the output text sequence and assumes the input sequence and all gold preceding tokens are given during training, while during inference the model suffers from the exposure bias problem (i.e., it only has access to its previously predicted tokens rather gold tokens during beam search). In this paper, we propose MoCa ({\bf Mo}mentum {\bf Ca}libration) for text generation. MoCa is an online method that dynamically generates slowly evolving (but consistent) samples using a momentum moving average generator with beam search and MoCa learns to align its model scores of these samples with their actual qualities. Experiments on four text generation datasets (i.e., CNN/DailyMail, XSum, SAMSum and Gigaword) show MoCa consistently improves strong pre-trained transformers using vanilla fine-tuning and we achieve the state-of-the-art results on CNN/DailyMail and SAMSum datasets.
Z-Code++: A Pre-trained Language Model Optimized for Abstractive Summarization
Aug 21, 2022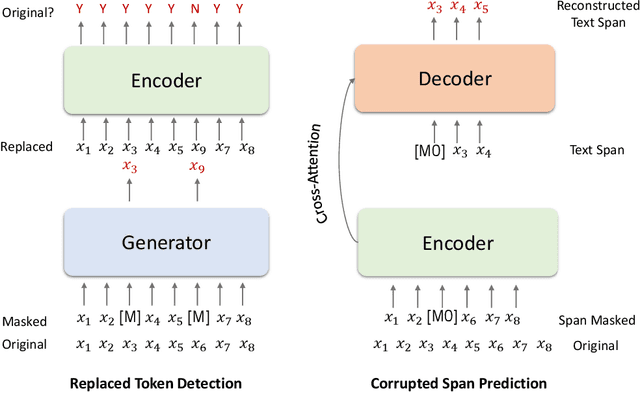

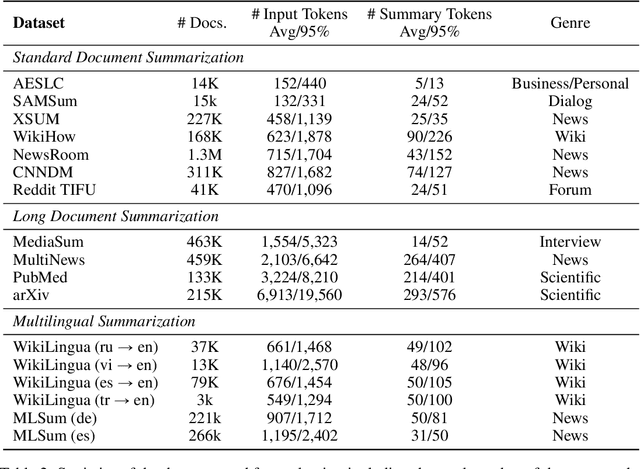
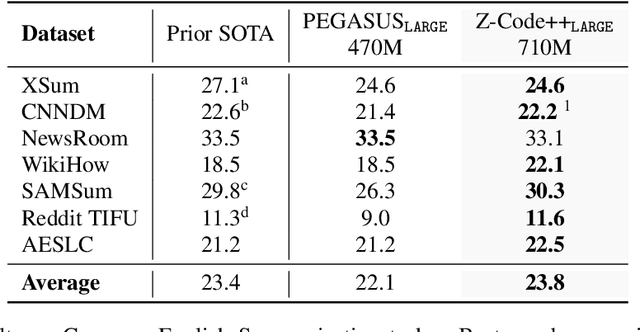
This paper presents Z-Code++, a new pre-trained language model optimized for abstractive text summarization. The model extends the state of the art encoder-decoder model using three techniques. First, we use a two-phase pre-training process to improve model's performance on low-resource summarization tasks. The model is first pre-trained using text corpora for language understanding, and then is continually pre-trained on summarization corpora for grounded text generation. Second, we replace self-attention layers in the encoder with disentangled attention layers, where each word is represented using two vectors that encode its content and position, respectively. Third, we use fusion-in-encoder, a simple yet effective method of encoding long sequences in a hierarchical manner. Z-Code++ creates new state of the art on 9 out of 13 text summarization tasks across 5 languages. Our model is parameter-efficient in that it outperforms the 600x larger PaLM-540B on XSum, and the finetuned 200x larger GPT3-175B on SAMSum. In zero-shot and few-shot settings, our model substantially outperforms the competing models.
Advances in Online Audio-Visual Meeting Transcription
Dec 10, 2019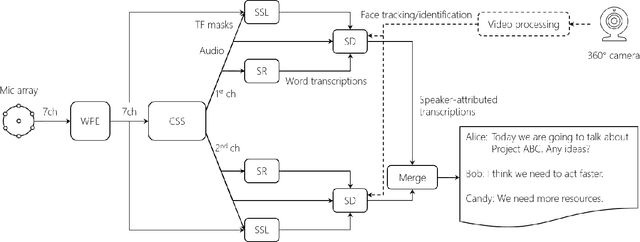

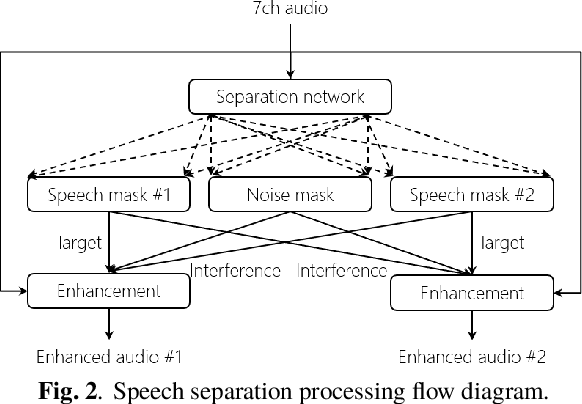
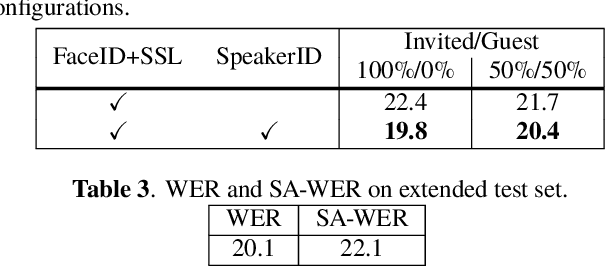
This paper describes a system that generates speaker-annotated transcripts of meetings by using a microphone array and a 360-degree camera. The hallmark of the system is its ability to handle overlapped speech, which has been an unsolved problem in realistic settings for over a decade. We show that this problem can be addressed by using a continuous speech separation approach. In addition, we describe an online audio-visual speaker diarization method that leverages face tracking and identification, sound source localization, speaker identification, and, if available, prior speaker information for robustness to various real world challenges. All components are integrated in a meeting transcription framework called SRD, which stands for "separate, recognize, and diarize". Experimental results using recordings of natural meetings involving up to 11 attendees are reported. The continuous speech separation improves a word error rate (WER) by 16.1% compared with a highly tuned beamformer. When a complete list of meeting attendees is available, the discrepancy between WER and speaker-attributed WER is only 1.0%, indicating accurate word-to-speaker association. This increases marginally to 1.6% when 50% of the attendees are unknown to the system.
Progressive Joint Modeling in Unsupervised Single-channel Overlapped Speech Recognition
Oct 20, 2017
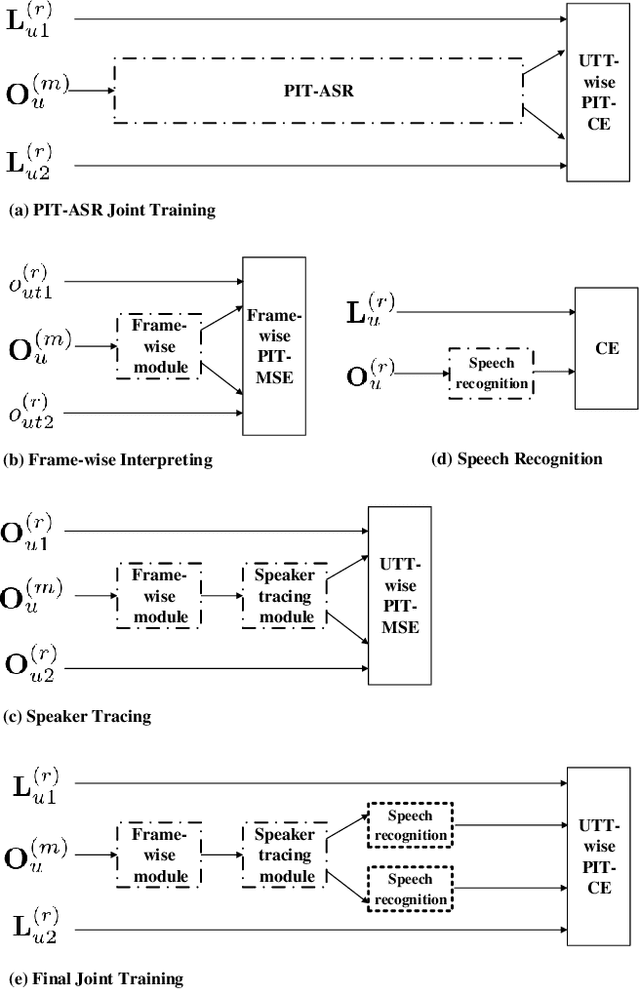
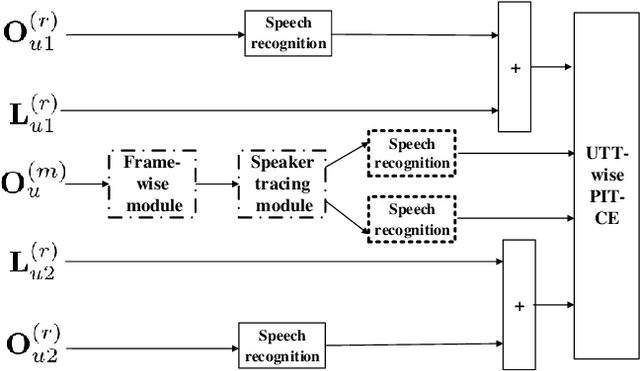
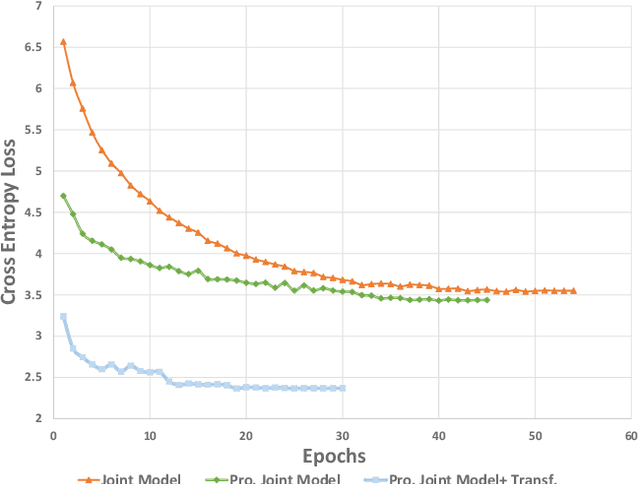
Unsupervised single-channel overlapped speech recognition is one of the hardest problems in automatic speech recognition (ASR). Permutation invariant training (PIT) is a state of the art model-based approach, which applies a single neural network to solve this single-input, multiple-output modeling problem. We propose to advance the current state of the art by imposing a modular structure on the neural network, applying a progressive pretraining regimen, and improving the objective function with transfer learning and a discriminative training criterion. The modular structure splits the problem into three sub-tasks: frame-wise interpreting, utterance-level speaker tracing, and speech recognition. The pretraining regimen uses these modules to solve progressively harder tasks. Transfer learning leverages parallel clean speech to improve the training targets for the network. Our discriminative training formulation is a modification of standard formulations, that also penalizes competing outputs of the system. Experiments are conducted on the artificial overlapped Switchboard and hub5e-swb dataset. The proposed framework achieves over 30% relative improvement of WER over both a strong jointly trained system, PIT for ASR, and a separately optimized system, PIT for speech separation with clean speech ASR model. The improvement comes from better model generalization, training efficiency and the sequence level linguistic knowledge integration.
* submitted to TASLP, 07/20/2017; accepted by TASLP, 10/13/2017