 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA cross Transformer for image denoising
Oct 16, 2023



Deep convolutional neural networks (CNNs) depend on feedforward and feedback ways to obtain good performance in image denoising. However, how to obtain effective structural information via CNNs to efficiently represent given noisy images is key for complex scenes. In this paper, we propose a cross Transformer denoising CNN (CTNet) with a serial block (SB), a parallel block (PB), and a residual block (RB) to obtain clean images for complex scenes. A SB uses an enhanced residual architecture to deeply search structural information for image denoising. To avoid loss of key information, PB uses three heterogeneous networks to implement multiple interactions of multi-level features to broadly search for extra information for improving the adaptability of an obtained denoiser for complex scenes. Also, to improve denoising performance, Transformer mechanisms are embedded into the SB and PB to extract complementary salient features for effectively removing noise in terms of pixel relations. Finally, a RB is applied to acquire clean images. Experiments illustrate that our CTNet is superior to some popular denoising methods in terms of real and synthetic image denoising. It is suitable to mobile digital devices, i.e., phones. Codes can be obtained at https://github.com/hellloxiaotian/CTNet.
DualAug: Exploiting Additional Heavy Augmentation with OOD Data Rejection
Oct 16, 2023Data augmentation is a dominant method for reducing model overfitting and improving generalization. Most existing data augmentation methods tend to find a compromise in augmenting the data, \textit{i.e.}, increasing the amplitude of augmentation carefully to avoid degrading some data too much and doing harm to the model performance. We delve into the relationship between data augmentation and model performance, revealing that the performance drop with heavy augmentation comes from the presence of out-of-distribution (OOD) data. Nonetheless, as the same data transformation has different effects for different training samples, even for heavy augmentation, there remains part of in-distribution data which is beneficial to model training. Based on the observation, we propose a novel data augmentation method, named \textbf{DualAug}, to keep the augmentation in distribution as much as possible at a reasonable time and computational cost. We design a data mixing strategy to fuse augmented data from both the basic- and the heavy-augmentation branches. Extensive experiments on supervised image classification benchmarks show that DualAug improve various automated data augmentation method. Moreover, the experiments on semi-supervised learning and contrastive self-supervised learning demonstrate that our DualAug can also improve related method. Code is available at \href{https://github.com/shuguang99/DualAug}{https://github.com/shuguang99/DualAug}.
Rethinking the BERT-like Pretraining for DNA Sequences
Oct 12, 2023With the success of large-scale pretraining in NLP, there is an increasing trend of applying it to the domain of life sciences. In particular, pretraining methods based on DNA sequences have garnered growing attention due to their potential to capture generic information about genes. However, existing pretraining methods for DNA sequences largely rely on direct adoptions of BERT pretraining from NLP, lacking a comprehensive understanding and a specifically tailored approach. To address this research gap, we first conducted a series of exploratory experiments and gained several insightful observations: 1) In the fine-tuning phase of downstream tasks, when using K-mer overlapping tokenization instead of K-mer non-overlapping tokenization, both overlapping and non-overlapping pretraining weights show consistent performance improvement.2) During the pre-training process, using K-mer overlapping tokenization quickly produces clear K-mer embeddings and reduces the loss to a very low level, while using K-mer non-overlapping tokenization results in less distinct embeddings and continuously decreases the loss. 3) Using overlapping tokenization causes the self-attention in the intermediate layers of pre-trained models to tend to overly focus on certain tokens, reflecting that these layers are not adequately optimized. In summary, overlapping tokenization can benefit the fine-tuning of downstream tasks but leads to inadequate pretraining with fast convergence. To unleash the pretraining potential, we introduce a novel approach called RandomMask, which gradually increases the task difficulty of BERT-like pretraining by continuously expanding its mask boundary, forcing the model to learn more knowledge. RandomMask is simple but effective, achieving top-tier performance across 26 datasets of 28 datasets spanning 7 downstream tasks.
Sentence-level Prompts Benefit Composed Image Retrieval
Oct 09, 2023



Composed image retrieval (CIR) is the task of retrieving specific images by using a query that involves both a reference image and a relative caption. Most existing CIR models adopt the late-fusion strategy to combine visual and language features. Besides, several approaches have also been suggested to generate a pseudo-word token from the reference image, which is further integrated into the relative caption for CIR. However, these pseudo-word-based prompting methods have limitations when target image encompasses complex changes on reference image, e.g., object removal and attribute modification. In this work, we demonstrate that learning an appropriate sentence-level prompt for the relative caption (SPRC) is sufficient for achieving effective composed image retrieval. Instead of relying on pseudo-word-based prompts, we propose to leverage pretrained V-L models, e.g., BLIP-2, to generate sentence-level prompts. By concatenating the learned sentence-level prompt with the relative caption, one can readily use existing text-based image retrieval models to enhance CIR performance. Furthermore, we introduce both image-text contrastive loss and text prompt alignment loss to enforce the learning of suitable sentence-level prompts. Experiments show that our proposed method performs favorably against the state-of-the-art CIR methods on the Fashion-IQ and CIRR datasets. The source code and pretrained model are publicly available at https://github.com/chunmeifeng/SPRC
Self-Supervised High Dynamic Range Imaging with Multi-Exposure Images in Dynamic Scenes
Oct 03, 2023
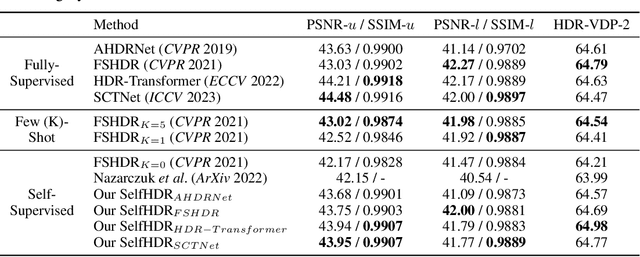
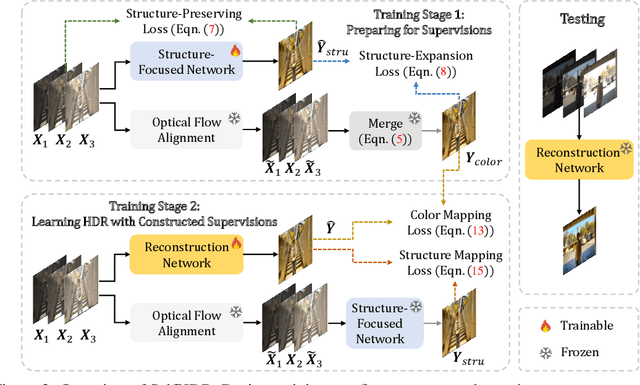

Merging multi-exposure images is a common approach for obtaining high dynamic range (HDR) images, with the primary challenge being the avoidance of ghosting artifacts in dynamic scenes. Recent methods have proposed using deep neural networks for deghosting. However, the methods typically rely on sufficient data with HDR ground-truths, which are difficult and costly to collect. In this work, to eliminate the need for labeled data, we propose SelfHDR, a self-supervised HDR reconstruction method that only requires dynamic multi-exposure images during training. Specifically, SelfHDR learns a reconstruction network under the supervision of two complementary components, which can be constructed from multi-exposure images and focus on HDR color as well as structure, respectively. The color component is estimated from aligned multi-exposure images, while the structure one is generated through a structure-focused network that is supervised by the color component and an input reference (\eg, medium-exposure) image. During testing, the learned reconstruction network is directly deployed to predict an HDR image. Experiments on real-world images demonstrate our SelfHDR achieves superior results against the state-of-the-art self-supervised methods, and comparable performance to supervised ones. Codes are available at https://github.com/cszhilu1998/SelfHDR
TextField3D: Towards Enhancing Open-Vocabulary 3D Generation with Noisy Text Fields
Sep 29, 2023



Recent works learn 3D representation explicitly under text-3D guidance. However, limited text-3D data restricts the vocabulary scale and text control of generations. Generators may easily fall into a stereotype concept for certain text prompts, thus losing open-vocabulary generation ability. To tackle this issue, we introduce a conditional 3D generative model, namely TextField3D. Specifically, rather than using the text prompts as input directly, we suggest to inject dynamic noise into the latent space of given text prompts, i.e., Noisy Text Fields (NTFs). In this way, limited 3D data can be mapped to the appropriate range of textual latent space that is expanded by NTFs. To this end, an NTFGen module is proposed to model general text latent code in noisy fields. Meanwhile, an NTFBind module is proposed to align view-invariant image latent code to noisy fields, further supporting image-conditional 3D generation. To guide the conditional generation in both geometry and texture, multi-modal discrimination is constructed with a text-3D discriminator and a text-2.5D discriminator. Compared to previous methods, TextField3D includes three merits: 1) large vocabulary, 2) text consistency, and 3) low latency. Extensive experiments demonstrate that our method achieves a potential open-vocabulary 3D generation capability.
Beyond Image Borders: Learning Feature Extrapolation for Unbounded Image Composition
Sep 21, 2023For improving image composition and aesthetic quality, most existing methods modulate the captured images by striking out redundant content near the image borders. However, such image cropping methods are limited in the range of image views. Some methods have been suggested to extrapolate the images and predict cropping boxes from the extrapolated image. Nonetheless, the synthesized extrapolated regions may be included in the cropped image, making the image composition result not real and potentially with degraded image quality. In this paper, we circumvent this issue by presenting a joint framework for both unbounded recommendation of camera view and image composition (i.e., UNIC). In this way, the cropped image is a sub-image of the image acquired by the predicted camera view, and thus can be guaranteed to be real and consistent in image quality. Specifically, our framework takes the current camera preview frame as input and provides a recommendation for view adjustment, which contains operations unlimited by the image borders, such as zooming in or out and camera movement. To improve the prediction accuracy of view adjustment prediction, we further extend the field of view by feature extrapolation. After one or several times of view adjustments, our method converges and results in both a camera view and a bounding box showing the image composition recommendation. Extensive experiments are conducted on the datasets constructed upon existing image cropping datasets, showing the effectiveness of our UNIC in unbounded recommendation of camera view and image composition. The source code, dataset, and pretrained models is available at https://github.com/liuxiaoyu1104/UNIC.
MetaF2N: Blind Image Super-Resolution by Learning Efficient Model Adaptation from Faces
Sep 15, 2023Due to their highly structured characteristics, faces are easier to recover than natural scenes for blind image super-resolution. Therefore, we can extract the degradation representation of an image from the low-quality and recovered face pairs. Using the degradation representation, realistic low-quality images can then be synthesized to fine-tune the super-resolution model for the real-world low-quality image. However, such a procedure is time-consuming and laborious, and the gaps between recovered faces and the ground-truths further increase the optimization uncertainty. To facilitate efficient model adaptation towards image-specific degradations, we propose a method dubbed MetaF2N, which leverages the contained Faces to fine-tune model parameters for adapting to the whole Natural image in a Meta-learning framework. The degradation extraction and low-quality image synthesis steps are thus circumvented in our MetaF2N, and it requires only one fine-tuning step to get decent performance. Considering the gaps between the recovered faces and ground-truths, we further deploy a MaskNet for adaptively predicting loss weights at different positions to reduce the impact of low-confidence areas. To evaluate our proposed MetaF2N, we have collected a real-world low-quality dataset with one or multiple faces in each image, and our MetaF2N achieves superior performance on both synthetic and real-world datasets. Source code, pre-trained models, and collected datasets are available at https://github.com/yinzhicun/MetaF2N.
Aggregating Long-term Sharp Features via Hybrid Transformers for Video Deblurring
Sep 13, 2023



Video deblurring methods, aiming at recovering consecutive sharp frames from a given blurry video, usually assume that the input video suffers from consecutively blurry frames. However, in real-world blurry videos taken by modern imaging devices, sharp frames usually appear in the given video, thus making temporal long-term sharp features available for facilitating the restoration of a blurry frame. In this work, we propose a video deblurring method that leverages both neighboring frames and present sharp frames using hybrid Transformers for feature aggregation. Specifically, we first train a blur-aware detector to distinguish between sharp and blurry frames. Then, a window-based local Transformer is employed for exploiting features from neighboring frames, where cross attention is beneficial for aggregating features from neighboring frames without explicit spatial alignment. To aggregate long-term sharp features from detected sharp frames, we utilize a global Transformer with multi-scale matching capability. Moreover, our method can easily be extended to event-driven video deblurring by incorporating an event fusion module into the global Transformer. Extensive experiments on benchmark datasets demonstrate that our proposed method outperforms state-of-the-art video deblurring methods as well as event-driven video deblurring methods in terms of quantitative metrics and visual quality. The source code and trained models are available at https://github.com/shangwei5/STGTN.
Cross-Consistent Deep Unfolding Network for Adaptive All-In-One Video Restoration
Sep 07, 2023Existing Video Restoration (VR) methods always necessitate the individual deployment of models for each adverse weather to remove diverse adverse weather degradations, lacking the capability for adaptive processing of degradations. Such limitation amplifies the complexity and deployment costs in practical applications. To overcome this deficiency, in this paper, we propose a Cross-consistent Deep Unfolding Network (CDUN) for All-In-One VR, which enables the employment of a single model to remove diverse degradations for the first time. Specifically, the proposed CDUN accomplishes a novel iterative optimization framework, capable of restoring frames corrupted by corresponding degradations according to the degradation features given in advance. To empower the framework for eliminating diverse degradations, we devise a Sequence-wise Adaptive Degradation Estimator (SADE) to estimate degradation features for the input corrupted video. By orchestrating these two cascading procedures, CDUN achieves adaptive processing for diverse degradation. In addition, we introduce a window-based inter-frame fusion strategy to utilize information from more adjacent frames. This strategy involves the progressive stacking of temporal windows in multiple iterations, effectively enlarging the temporal receptive field and enabling each frame's restoration to leverage information from distant frames. Extensive experiments demonstrate that the proposed method achieves state-of-the-art performance in All-In-One VR.