 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoom To Learn, Learn To Zoom
May 13, 2019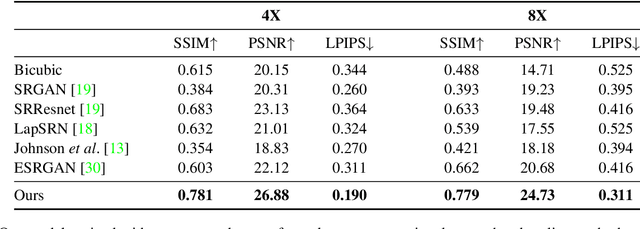
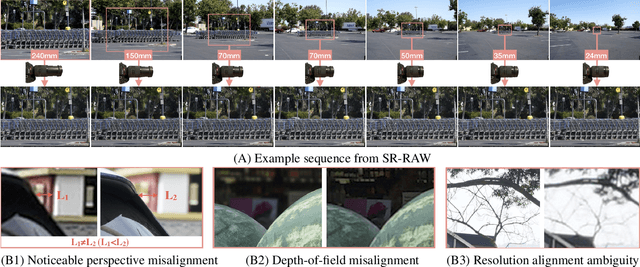
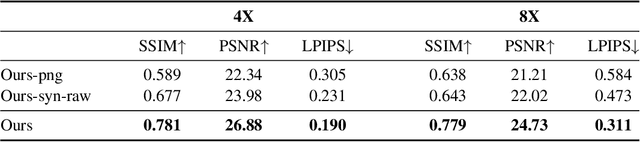

This paper shows that when applying machine learning to digital zoom for photography, it is beneficial to use real, RAW sensor data for training. Existing learning-based super-resolution methods do not use real sensor data, instead operating on RGB images. In practice, these approaches result in loss of detail and accuracy in their digitally zoomed output when zooming in on distant image regions. We also show that synthesizing sensor data by resampling high-resolution RGB images is an oversimplified approximation of real sensor data and noise, resulting in worse image quality. The key barrier to using real sensor data for training is that ground truth high-resolution imagery is missing. We show how to obtain the ground-truth data with optically zoomed images and contribute a dataset, SR-RAW, for real-world computational zoom. We use SR-RAW to train a deep network with a novel contextual bilateral loss (CoBi) that delivers critical robustness to mild misalignment in input-output image pairs. The trained network achieves state-of-the-art performance in 4X and 8X computational zoom.
What Do Single-view 3D Reconstruction Networks Learn?
May 09, 2019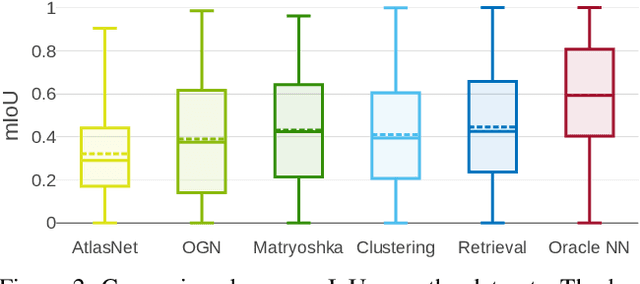
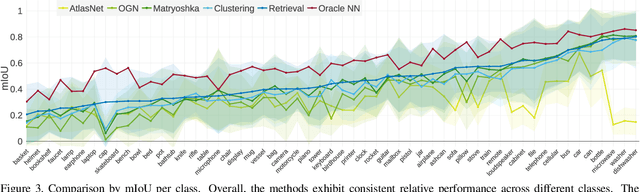
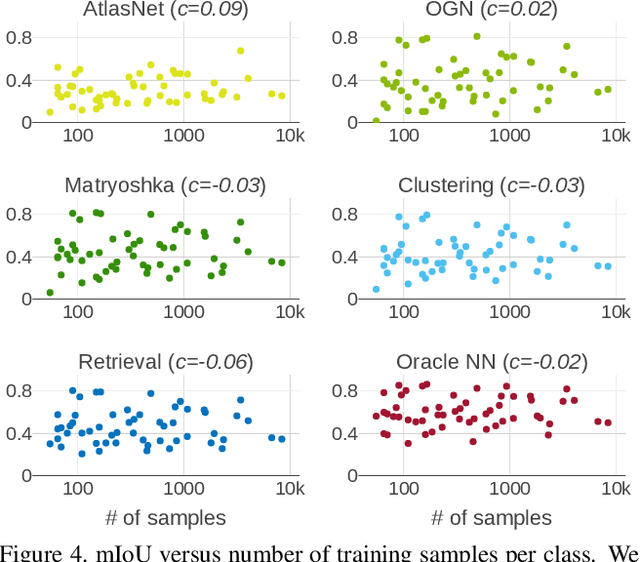

Convolutional networks for single-view object reconstruction have shown impressive performance and have become a popular subject of research. All existing techniques are united by the idea of having an encoder-decoder network that performs non-trivial reasoning about the 3D structure of the output space. In this work, we set up two alternative approaches that perform image classification and retrieval respectively. These simple baselines yield better results than state-of-the-art methods, both qualitatively and quantitatively. We show that encoder-decoder methods are statistically indistinguishable from these baselines, thus indicating that the current state of the art in single-view object reconstruction does not actually perform reconstruction but image classification. We identify aspects of popular experimental procedures that elicit this behavior and discuss ways to improve the current state of research.
Events-to-Video: Bringing Modern Computer Vision to Event Cameras
Apr 17, 2019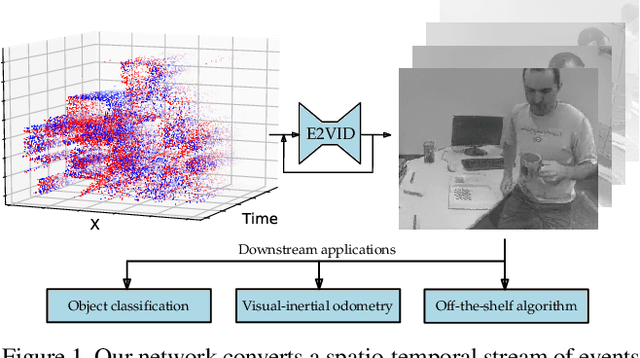
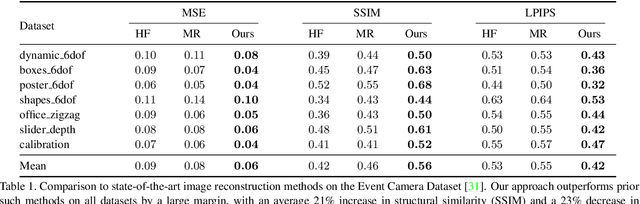
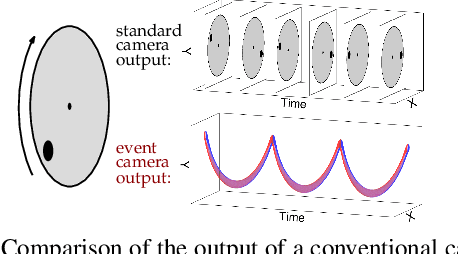
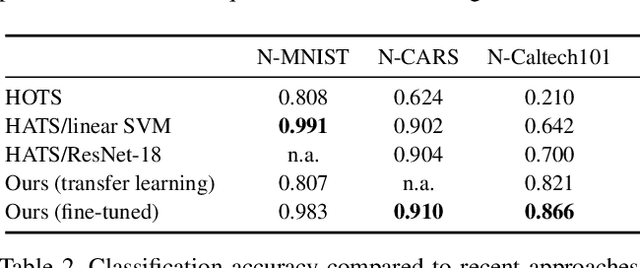
Event cameras are novel sensors that report brightness changes in the form of asynchronous "events" instead of intensity frames. They have significant advantages over conventional cameras: high temporal resolution, high dynamic range, and no motion blur. Since the output of event cameras is fundamentally different from conventional cameras, it is commonly accepted that they require the development of specialized algorithms to accommodate the particular nature of events. In this work, we take a different view and propose to apply existing, mature computer vision techniques to videos reconstructed from event data. We propose a novel recurrent network to reconstruct videos from a stream of events, and train it on a large amount of simulated event data. Our experiments show that our approach surpasses state-of-the-art reconstruction methods by a large margin (> 20%) in terms of image quality. We further apply off-the-shelf computer vision algorithms to videos reconstructed from event data on tasks such as object classification and visual-inertial odometry, and show that this strategy consistently outperforms algorithms that were specifically designed for event data. We believe that our approach opens the door to bringing the outstanding properties of event cameras to an entirely new range of tasks. A video of the experiments is available at https://youtu.be/IdYrC4cUO0I
Habitat: A Platform for Embodied AI Research
Apr 02, 2019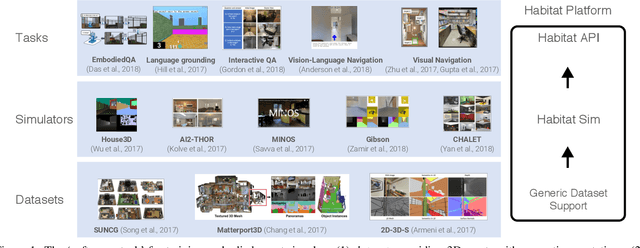
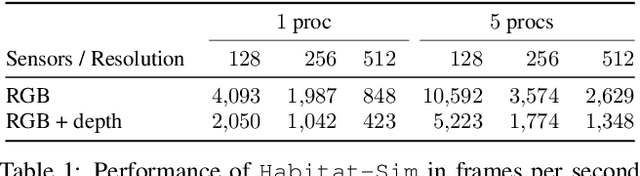

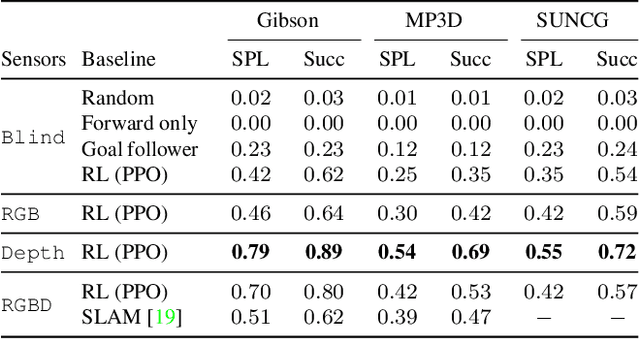
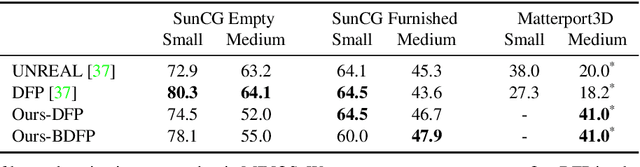
We present Habitat, a new platform for research in embodied artificial intelligence (AI). Habitat enables training embodied agents (virtual robots) in highly efficient photorealistic 3D simulation, before transferring the learned skills to reality. Specifically, Habitat consists of the following: 1. Habitat-Sim: a flexible, high-performance 3D simulator with configurable agents, multiple sensors, and generic 3D dataset handling (with built-in support for SUNCG, Matterport3D, Gibson datasets). Habitat-Sim is fast -- when rendering a scene from the Matterport3D dataset, Habitat-Sim achieves several thousand frames per second (fps) running single-threaded, and can reach over 10,000 fps multi-process on a single GPU, which is orders of magnitude faster than the closest simulator. 2. Habitat-API: a modular high-level library for end-to-end development of embodied AI algorithms -- defining embodied AI tasks (e.g. navigation, instruction following, question answering), configuring and training embodied agents (via imitation or reinforcement learning, or via classic SLAM), and benchmarking using standard metrics. These large-scale engineering contributions enable us to answer scientific questions requiring experiments that were till now impracticable or `merely' impractical. Specifically, in the context of point-goal navigation (1) we revisit the comparison between learning and SLAM approaches from two recent works and find evidence for the opposite conclusion -- that learning outperforms SLAM, if scaled to total experience far surpassing that of previous investigations, and (2) we conduct the first cross-dataset generalization experiments {train, test} x {Matterport3D, Gibson} for multiple sensors {blind, RGB, RGBD, D} and find that only agents with depth (D) sensors generalize across datasets. We hope that our open-source platform and these findings will advance research in embodied AI.
Benchmarking Classic and Learned Navigation in Complex 3D Environments
Mar 28, 2019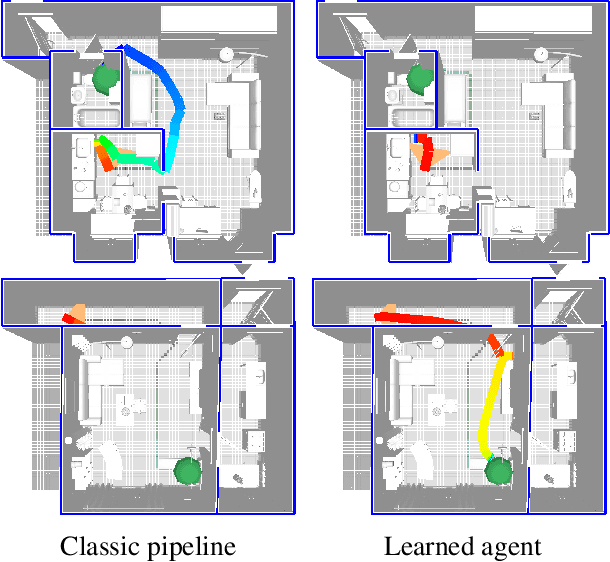
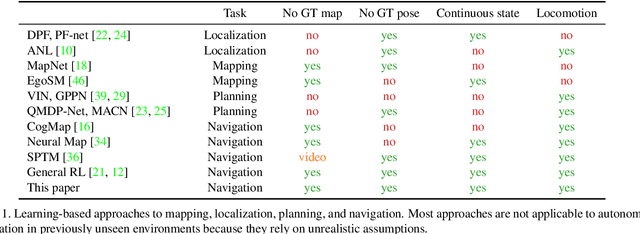
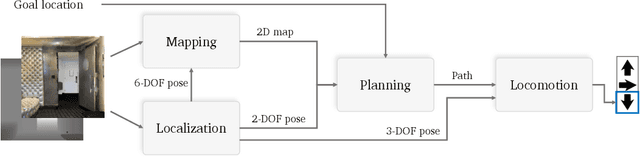
Navigation research is attracting renewed interest with the advent of learning-based methods. However, this new line of work is largely disconnected from well-established classic navigation approaches. In this paper, we take a step towards coordinating these two directions of research. We set up classic and learning-based navigation systems in common simulated environments and thoroughly evaluate them in indoor spaces of varying complexity, with access to different sensory modalities. Additionally, we measure human performance in the same environments. We find that a classic pipeline, when properly tuned, can perform very well in complex cluttered environments. On the other hand, learned systems can operate more robustly with a limited sensor suite. Overall, both approaches are still far from human-level performance.
Beauty and the Beast: Optimal Methods Meet Learning for Drone Racing
Mar 01, 2019
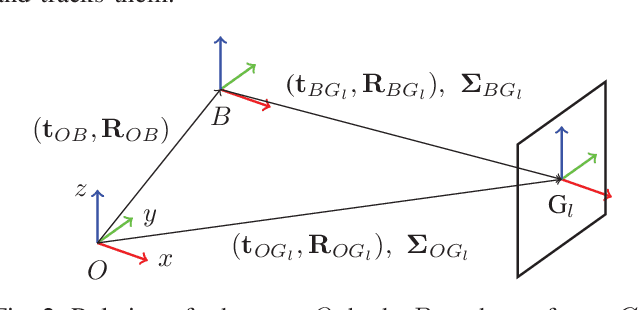


Autonomous micro aerial vehicles still struggle with fast and agile maneuvers, dynamic environments, imperfect sensing, and state estimation drift. Autonomous drone racing brings these challenges to the fore. Human pilots can fly a previously unseen track after a handful of practice runs. In contrast, state-of-the-art autonomous navigation algorithms require either a precise metric map of the environment or a large amount of training data collected in the track of interest. To bridge this gap, we propose an approach that can fly a new track in a previously unseen environment without a precise map or expensive data collection. Our approach represents the global track layout with coarse gate locations, which can be easily estimated from a single demonstration flight. At test time, a convolutional network predicts the poses of the closest gates along with their uncertainty. These predictions are incorporated by an extended Kalman filter to maintain optimal maximum-a-posteriori estimates of gate locations. This allows the framework to cope with misleading high-variance estimates that could stem from poor observability or lack of visible gates. Given the estimated gate poses, we use model predictive control to quickly and accurately navigate through the track. We conduct extensive experiments in the physical world, demonstrating agile and robust flight through complex and diverse previously-unseen race tracks. The presented approach was used to win the IROS 2018 Autonomous Drone Race Competition, outracing the second-placing team by a factor of two.
* 6 pages (+1 references)
Learning agile and dynamic motor skills for legged robots
Jan 24, 2019Legged robots pose one of the greatest challenges in robotics. Dynamic and agile maneuvers of animals cannot be imitated by existing methods that are crafted by humans. A compelling alternative is reinforcement learning, which requires minimal craftsmanship and promotes the natural evolution of a control policy. However, so far, reinforcement learning research for legged robots is mainly limited to simulation, and only few and comparably simple examples have been deployed on real systems. The primary reason is that training with real robots, particularly with dynamically balancing systems, is complicated and expensive. In the present work, we introduce a method for training a neural network policy in simulation and transferring it to a state-of-the-art legged system, thereby leveraging fast, automated, and cost-effective data generation schemes. The approach is applied to the ANYmal robot, a sophisticated medium-dog-sized quadrupedal system. Using policies trained in simulation, the quadrupedal machine achieves locomotion skills that go beyond what had been achieved with prior methods: ANYmal is capable of precisely and energy-efficiently following high-level body velocity commands, running faster than before, and recovering from falling even in complex configurations.
Motion Perception in Reinforcement Learning with Dynamic Objects
Jan 10, 2019
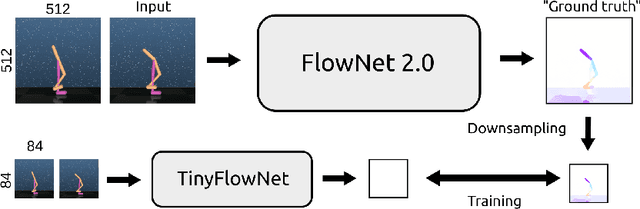
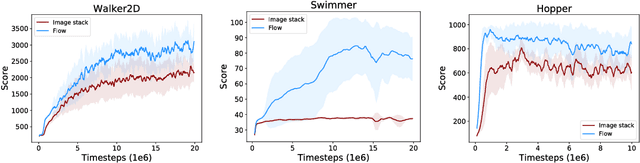

In dynamic environments, learned controllers are supposed to take motion into account when selecting the action to be taken. However, in existing reinforcement learning works motion is rarely treated explicitly; it is rather assumed that the controller learns the necessary motion representation from temporal stacks of frames implicitly. In this paper, we show that for continuous control tasks learning an explicit representation of motion improves the quality of the learned controller in dynamic scenarios. We demonstrate this on common benchmark tasks (Walker, Swimmer, Hopper), on target reaching and ball catching tasks with simulated robotic arms, and on a dynamic single ball juggling task. Moreover, we find that when equipped with an appropriate network architecture, the agent can, on some tasks, learn motion features also with pure reinforcement learning, without additional supervision. Further we find that using an image difference between the current and the previous frame as an additional input leads to better results than a temporal stack of frames.
Driving Policy Transfer via Modularity and Abstraction
Dec 13, 2018
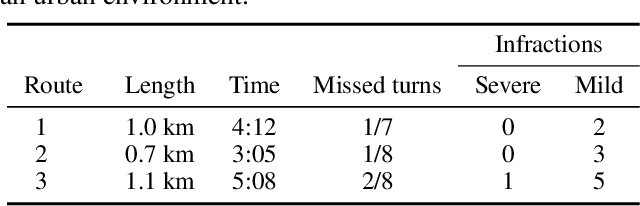
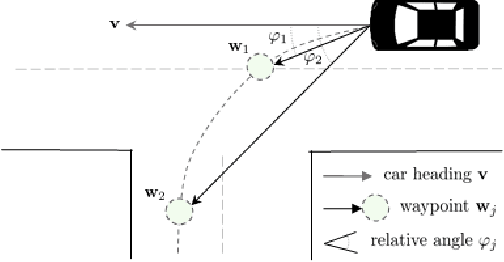
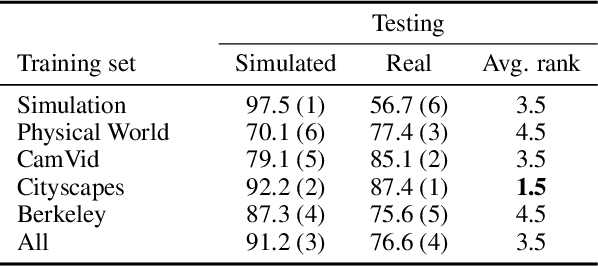
End-to-end approaches to autonomous driving have high sample complexity and are difficult to scale to realistic urban driving. Simulation can help end-to-end driving systems by providing a cheap, safe, and diverse training environment. Yet training driving policies in simulation brings up the problem of transferring such policies to the real world. We present an approach to transferring driving policies from simulation to reality via modularity and abstraction. Our approach is inspired by classic driving systems and aims to combine the benefits of modular architectures and end-to-end deep learning approaches. The key idea is to encapsulate the driving policy such that it is not directly exposed to raw perceptual input or low-level vehicle dynamics. We evaluate the presented approach in simulated urban environments and in the real world. In particular, we transfer a driving policy trained in simulation to a 1/5-scale robotic truck that is deployed in a variety of conditions, with no finetuning, on two continents. The supplementary video can be viewed at https://youtu.be/BrMDJqI6H5U
Assessing Generalization in Deep Reinforcement Learning
Oct 29, 2018
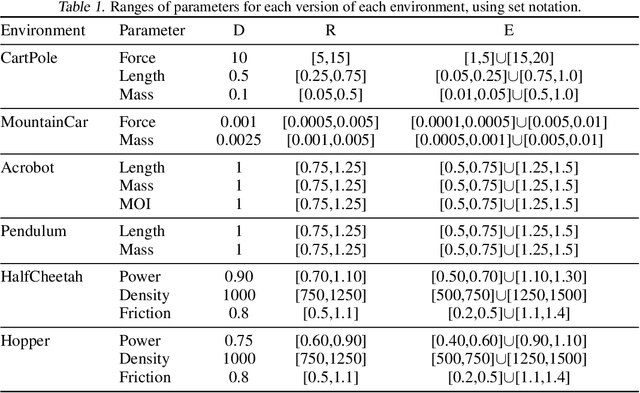
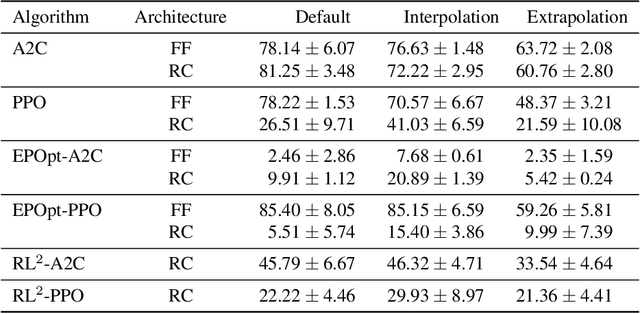
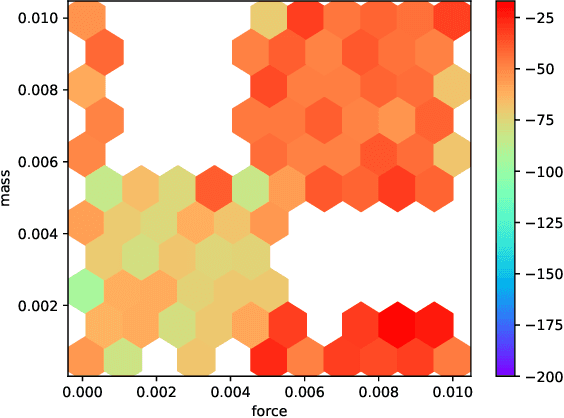
Deep reinforcement learning (RL) has achieved breakthrough results on many tasks, but has been shown to be sensitive to system changes at test time. As a result, building deep RL agents that generalize has become an active research area. Our aim is to catalyze and streamline community-wide progress on this problem by providing the first benchmark and a common experimental protocol for investigating generalization in RL. Our benchmark contains a diverse set of environments and our evaluation methodology covers both in-distribution and out-of-distribution generalization. To provide a set of baselines for future research, we conduct a systematic evaluation of deep RL algorithms, including those that specifically tackle the problem of generalization.