 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Meets Visual Odometry
Jul 22, 2024



Visual Odometry (VO) is essential to downstream mobile robotics and augmented/virtual reality tasks. Despite recent advances, existing VO methods still rely on heuristic design choices that require several weeks of hyperparameter tuning by human experts, hindering generalizability and robustness. We address these challenges by reframing VO as a sequential decision-making task and applying Reinforcement Learning (RL) to adapt the VO process dynamically. Our approach introduces a neural network, operating as an agent within the VO pipeline, to make decisions such as keyframe and grid-size selection based on real-time conditions. Our method minimizes reliance on heuristic choices using a reward function based on pose error, runtime, and other metrics to guide the system. Our RL framework treats the VO system and the image sequence as an environment, with the agent receiving observations from keypoints, map statistics, and prior poses. Experimental results using classical VO methods and public benchmarks demonstrate improvements in accuracy and robustness, validating the generalizability of our RL-enhanced VO approach to different scenarios. We believe this paradigm shift advances VO technology by eliminating the need for time-intensive parameter tuning of heuristics.
State Space Models for Event Cameras
Feb 23, 2024Today, state-of-the-art deep neural networks that process event-camera data first convert a temporal window of events into dense, grid-like input representations. As such, they exhibit poor generalizability when deployed at higher inference frequencies (i.e., smaller temporal windows) than the ones they were trained on. We address this challenge by introducing state-space models (SSMs) with learnable timescale parameters to event-based vision. This design adapts to varying frequencies without the need to retrain the network at different frequencies. Additionally, we investigate two strategies to counteract aliasing effects when deploying the model at higher frequencies. We comprehensively evaluate our approach against existing methods based on RNN and Transformer architectures across various benchmarks, including Gen1 and 1 Mpx event camera datasets. Our results demonstrate that SSM-based models train 33% faster and also exhibit minimal performance degradation when tested at higher frequencies than the training input. Traditional RNN and Transformer models exhibit performance drops of more than 20 mAP, with SSMs having a drop of 3.31 mAP, highlighting the effectiveness of SSMs in event-based vision tasks.
LEOD: Label-Efficient Object Detection for Event Cameras
Nov 29, 2023



Object detection with event cameras enjoys the property of low latency and high dynamic range, making it suitable for safety-critical scenarios such as self-driving. However, labeling event streams with high temporal resolutions for supervised training is costly. We address this issue with LEOD, the first framework for label-efficient event-based detection. Our method unifies weakly- and semi-supervised object detection with a self-training mechanism. We first utilize a detector pre-trained on limited labels to produce pseudo ground truth on unlabeled events, and then re-train the detector with both real and generated labels. Leveraging the temporal consistency of events, we run bi-directional inference and apply tracking-based post-processing to enhance the quality of pseudo labels. To stabilize training, we further design a soft anchor assignment strategy to mitigate the noise in labels. We introduce new experimental protocols to evaluate the task of label-efficient event-based detection on Gen1 and 1Mpx datasets. LEOD consistently outperforms supervised baselines across various labeling ratios. For example, on Gen1, it improves mAP by 8.6% and 7.8% for RVT-S trained with 1% and 2% labels. On 1Mpx, RVT-S with 10% labels even surpasses its fully-supervised counterpart using 100% labels. LEOD maintains its effectiveness even when all labeled data are available, reaching new state-of-the-art results. Finally, we show that our method readily scales to improve larger detectors as well.
Revisiting Token Pruning for Object Detection and Instance Segmentation
Jun 12, 2023



Vision Transformers (ViTs) have shown impressive performance in computer vision, but their high computational cost, quadratic in the number of tokens, limits their adoption in computation-constrained applications. However, this large number of tokens may not be necessary, as not all tokens are equally important. In this paper, we investigate token pruning to accelerate inference for object detection and instance segmentation, extending prior works from image classification. Through extensive experiments, we offer four insights for dense tasks: (i) tokens should not be completely pruned and discarded, but rather preserved in the feature maps for later use. (ii) reactivating previously pruned tokens can further enhance model performance. (iii) a dynamic pruning rate based on images is better than a fixed pruning rate. (iv) a lightweight, 2-layer MLP can effectively prune tokens, achieving accuracy comparable with complex gating networks with a simpler design. We evaluate the impact of these design choices on COCO dataset and present a method integrating these insights that outperforms prior art token pruning models, significantly reducing performance drop from ~1.5 mAP to ~0.3 mAP for both boxes and masks. Compared to the dense counterpart that uses all tokens, our method achieves up to 34% faster inference speed for the whole network and 46% for the backbone.
From Chaos Comes Order: Ordering Event Representations for Object Detection
Apr 27, 2023



Today, state-of-the-art deep neural networks that process events first convert them into dense, grid-like input representations before using an off-the-shelf network. However, selecting the appropriate representation for the task traditionally requires training a neural network for each representation and selecting the best one based on the validation score, which is very time-consuming. In this work, we eliminate this bottleneck by selecting the best representation based on the Gromov-Wasserstein Discrepancy (GWD) between the raw events and their representation. It is approximately 200 times faster to compute than training a neural network and preserves the task performance ranking of event representations across multiple representations, network backbones, and datasets. This means that finding a representation with a high task score is equivalent to finding a representation with a low GWD. We use this insight to, for the first time, perform a hyperparameter search on a large family of event representations, revealing new and powerful representations that exceed the state-of-the-art. On object detection, our optimized representation outperforms existing representations by 1.9% mAP on the 1 Mpx dataset and 8.6% mAP on the Gen1 dataset and even outperforms the state-of-the-art by 1.8% mAP on Gen1 and state-of-the-art feed-forward methods by 6.0% mAP on the 1 Mpx dataset. This work opens a new unexplored field of explicit representation optimization for event-based learning methods.
Neuromorphic Optical Flow and Real-time Implementation with Event Cameras
Apr 14, 2023
Optical flow provides information on relative motion that is an important component in many computer vision pipelines. Neural networks provide high accuracy optical flow, yet their complexity is often prohibitive for application at the edge or in robots, where efficiency and latency play crucial role. To address this challenge, we build on the latest developments in event-based vision and spiking neural networks. We propose a new network architecture, inspired by Timelens, that improves the state-of-the-art self-supervised optical flow accuracy when operated both in spiking and non-spiking mode. To implement a real-time pipeline with a physical event camera, we propose a methodology for principled model simplification based on activity and latency analysis. We demonstrate high speed optical flow prediction with almost two orders of magnitude reduced complexity while maintaining the accuracy, opening the path for real-time deployments.
A Hybrid ANN-SNN Architecture for Low-Power and Low-Latency Visual Perception
Mar 24, 2023



Spiking Neural Networks (SNN) are a class of bio-inspired neural networks that promise to bring low-power and low-latency inference to edge devices through asynchronous and sparse processing. However, being temporal models, SNNs depend heavily on expressive states to generate predictions on par with classical artificial neural networks (ANNs). These states converge only after long transient periods, and quickly decay without input data, leading to higher latency, power consumption, and lower accuracy. This work addresses this issue by initializing the state with an auxiliary ANN running at a low rate. The SNN then uses the state to generate predictions with high temporal resolution until the next initialization phase. Our hybrid ANN-SNN model thus combines the best of both worlds: It does not suffer from long state transients and state decay thanks to the ANN, and can generate predictions with high temporal resolution, low latency, and low power thanks to the SNN. We show for the task of event-based 2D and 3D human pose estimation that our method consumes 88% less power with only a 4% decrease in performance compared to its fully ANN counterparts when run at the same inference rate. Moreover, when compared to SNNs, our method achieves a 74% lower error. This research thus provides a new understanding of how ANNs and SNNs can be used to maximize their respective benefits.
Recurrent Vision Transformers for Object Detection with Event Cameras
Dec 11, 2022



We present Recurrent Vision Transformers (RVTs), a novel backbone for object detection with event cameras. Event cameras provide visual information with sub-millisecond latency at a high-dynamic range and with strong robustness against motion blur. These unique properties offer great potential for low-latency object detection and tracking in time-critical scenarios. Prior work in event-based vision has achieved outstanding detection performance but at the cost of substantial inference time, typically beyond 40 milliseconds. By revisiting the high-level design of recurrent vision backbones, we reduce inference time by a factor of 5 while retaining similar performance. To achieve this, we explore a multi-stage design that utilizes three key concepts in each stage: First, a convolutional prior that can be regarded as a conditional positional embedding. Second, local- and dilated global self-attention for spatial feature interaction. Third, recurrent temporal feature aggregation to minimize latency while retaining temporal information. RVTs can be trained from scratch to reach state-of-the-art performance on event-based object detection - achieving an mAP of 47.5% on the Gen1 automotive dataset. At the same time, RVTs offer fast inference (13 ms on a T4 GPU) and favorable parameter efficiency (5 times fewer than prior art). Our study brings new insights into effective design choices that could be fruitful for research beyond event-based vision.
Data-driven Feature Tracking for Event Cameras
Nov 23, 2022



Because of their high temporal resolution, increased resilience to motion blur, and very sparse output, event cameras have been shown to be ideal for low-latency and low-bandwidth feature tracking, even in challenging scenarios. Existing feature tracking methods for event cameras are either handcrafted or derived from first principles but require extensive parameter tuning, are sensitive to noise, and do not generalize to different scenarios due to unmodeled effects. To tackle these deficiencies, we introduce the first data-driven feature tracker for event cameras, which leverages low-latency events to track features detected in a grayscale frame. We achieve robust performance via a novel frame attention module, which shares information across feature tracks. By directly transferring zero-shot from synthetic to real data, our data-driven tracker outperforms existing approaches in relative feature age by up to 120 % while also achieving the lowest latency. This performance gap is further increased to 130 % by adapting our tracker to real data with a novel self-supervision strategy.
Dense Continuous-Time Optical Flow from Events and Frames
Mar 25, 2022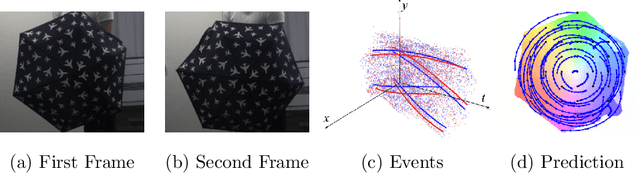
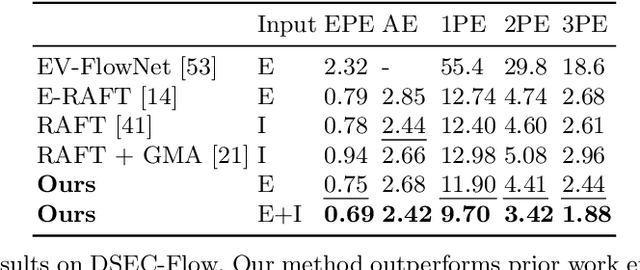
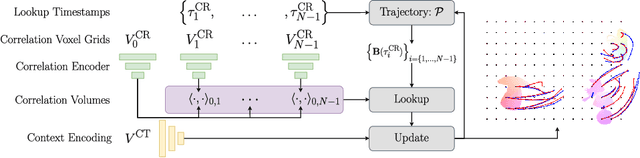
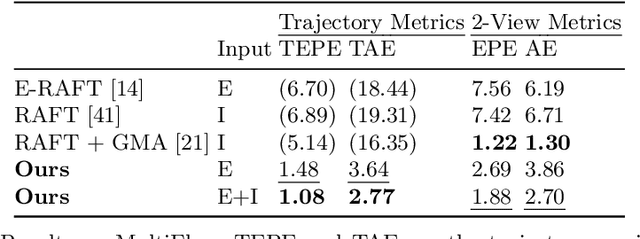
We present a method for estimating dense continuous-time optical flow. Traditional dense optical flow methods compute the pixel displacement between two images. Due to missing information, these approaches cannot recover the pixel trajectories in the blind time between two images. In this work, we show that it is possible to compute per-pixel, continuous-time optical flow by additionally using events from an event camera. Events provide temporally fine-grained information about movement in image space due to their asynchronous nature and microsecond response time. We leverage these benefits to predict pixel trajectories densely in continuous-time via parameterized B\'ezier curves. To achieve this, we introduce multiple innovations to build a neural network with strong inductive biases for this task: First, we build multiple sequential correlation volumes in time using event data. Second, we use B\'ezier curves to index these correlation volumes at multiple timestamps along the trajectory. Third, we use the retrieved correlation to update the B\'ezier curve representations iteratively. Our method can optionally include image pairs to boost performance further. The proposed approach outperforms existing image-based and event-based methods by 11.5 % lower EPE on DSEC-Flow. Finally, we introduce a novel synthetic dataset MultiFlow for pixel trajectory regression on which our method is currently the only successful approach.