 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKamino: GPU-based Massively Parallel Simulation of Multi-Body Systems with Challenging Topologies
Mar 17, 2026We present Kamino, a GPU-based physics solver for massively parallel simulations of heterogeneous highly-coupled mechanical systems. Implemented in Python using NVIDIA Warp and integrated into the Newton framework, it enables the application of data-driven methods, such as large-scale reinforcement learning, to complex robotic systems that exhibit strongly coupled kinematic and dynamic constraints such as kinematic loops. The latter are often circumvented by practitioners; approximating the system topology as a kinematic tree and incorporating explicit loop-closure constraints or so-called mimic joints. Kamino aims at alleviating this burden by natively supporting these types of coupling. This capability facilitates high-throughput parallelized simulations that capture the true nature of mechanical systems that exploit closed kinematic chains for mechanical advantage. Moreover, Kamino supports heterogeneous worlds, allowing for batched simulation of structurally diverse robots on a single GPU. At its core lies a state-of-the-art constrained optimization algorithm that computes constraint forces by solving the constrained rigid multi-body forward dynamics transcribed as a nonlinear complementarity problem. This leads to high-fidelity simulations that can resolve contact dynamics without resorting to approximate models that simplify and/or convexify the problem. We demonstrate RL policy training on DR Legs, a biped with six nested kinematic loops, generating a feasible walking policy while simulating 4096 parallel environments on a single GPU.
On Solving the Dynamics of Constrained Rigid Multi-Body Systems with Kinematic Loops
Apr 28, 2025This technical report provides an in-depth evaluation of both established and state-of-the-art methods for simulating constrained rigid multi-body systems with hard-contact dynamics, using formulations of Nonlinear Complementarity Problems (NCPs). We are particularly interest in examining the simulation of highly coupled mechanical systems with multitudes of closed-loop bilateral kinematic joint constraints in the presence of additional unilateral constraints such as joint limits and frictional contacts with restitutive impacts. This work thus presents an up-to-date literature survey of the relevant fields, as well as an in-depth description of the approaches used for the formulation and solving of the numerical time-integration problem in a maximal coordinate setting. More specifically, our focus lies on a version of the overall problem that decomposes it into the forward dynamics problem followed by a time-integration using the states of the bodies and the constraint reactions rendered by the former. We then proceed to elaborate on the formulations used to model frictional contact dynamics and define a set of solvers that are representative of those currently employed in the majority of the established physics engines. A key aspect of this work is the definition of a benchmarking framework that we propose as a means to both qualitatively and quantitatively evaluate the performance envelopes of the set of solvers on a diverse set of challenging simulation scenarios. We thus present an extensive set of experiments that aim at highlighting the absolute and relative performance of all solvers on particular problems of interest as well as aggravatingly over the complete set defined in the suite.
Cat-like Jumping and Landing of Legged Robots in Low-gravity Using Deep Reinforcement Learning
Jun 17, 2021


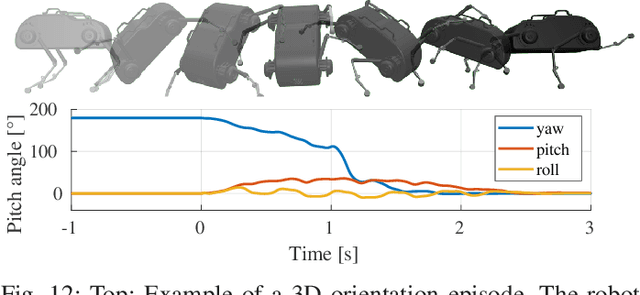
In this article, we show that learned policies can be applied to solve legged locomotion control tasks with extensive flight phases, such as those encountered in space exploration. Using an off-the-shelf deep reinforcement learning algorithm, we trained a neural network to control a jumping quadruped robot while solely using its limbs for attitude control. We present tasks of increasing complexity leading to a combination of three-dimensional (re-)orientation and landing locomotion behaviors of a quadruped robot traversing simulated low-gravity celestial bodies. We show that our approach easily generalizes across these tasks and successfully trains policies for each case. Using sim-to-real transfer, we deploy trained policies in the real world on the SpaceBok robot placed on an experimental testbed designed for two-dimensional micro-gravity experiments. The experimental results demonstrate that repetitive, controlled jumping and landing with natural agility is possible.
DeepGait: Planning and Control of Quadrupedal Gaits using Deep Reinforcement Learning
Sep 18, 2019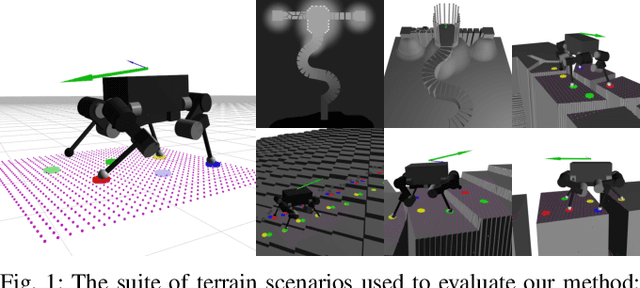
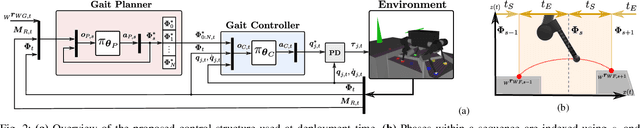
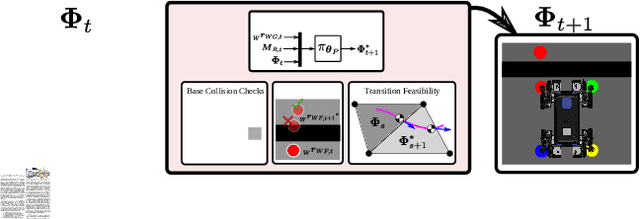
This paper addresses the problem of legged locomotion in non-flat terrain. As legged robots such as quadrupeds are to be deployed in terrains with geometries which are difficult to model and predict, the need arises to equip them with the capability to generalize well to unforeseen situations. In this work, we propose a novel technique for training neural-network policies for terrain-aware locomotion, which combines state-of-the-art methods for model-based motion planning and reinforcement learning. Our approach is centered on formulating Markov decision processes using the evaluation of dynamic feasibility criteria in place of physical simulation. We thus employ policy-gradient methods to independently train policies which respectively plan and execute foothold and base motions in 3D environments using both proprioceptive and exteroceptive measurements. We apply our method within a challenging suite of simulated terrain scenarios which contain features such as narrow bridges, gaps and stepping-stones, and train policies which succeed in locomoting effectively in all cases.
Learning agile and dynamic motor skills for legged robots
Jan 24, 2019Legged robots pose one of the greatest challenges in robotics. Dynamic and agile maneuvers of animals cannot be imitated by existing methods that are crafted by humans. A compelling alternative is reinforcement learning, which requires minimal craftsmanship and promotes the natural evolution of a control policy. However, so far, reinforcement learning research for legged robots is mainly limited to simulation, and only few and comparably simple examples have been deployed on real systems. The primary reason is that training with real robots, particularly with dynamically balancing systems, is complicated and expensive. In the present work, we introduce a method for training a neural network policy in simulation and transferring it to a state-of-the-art legged system, thereby leveraging fast, automated, and cost-effective data generation schemes. The approach is applied to the ANYmal robot, a sophisticated medium-dog-sized quadrupedal system. Using policies trained in simulation, the quadrupedal machine achieves locomotion skills that go beyond what had been achieved with prior methods: ANYmal is capable of precisely and energy-efficiently following high-level body velocity commands, running faster than before, and recovering from falling even in complex configurations.
Cable-Driven Actuation for Highly Dynamic Robotic Systems
Jun 27, 2018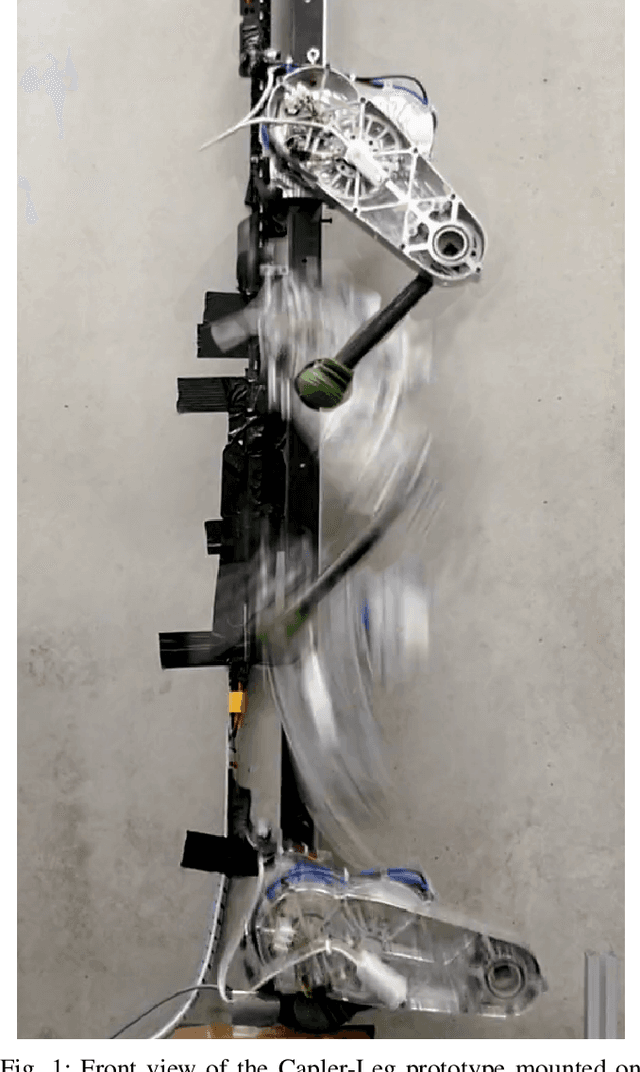
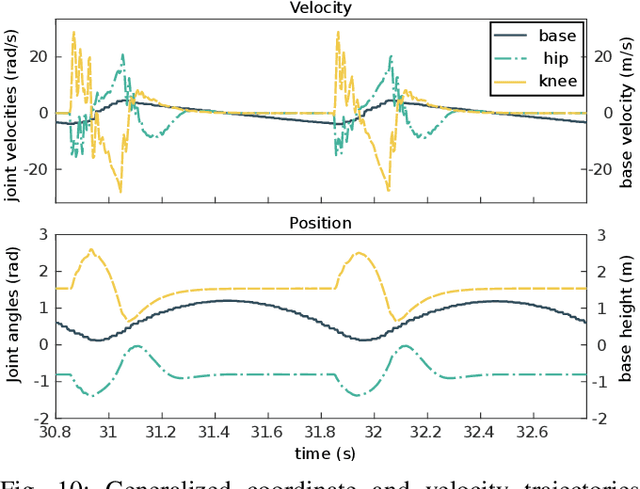
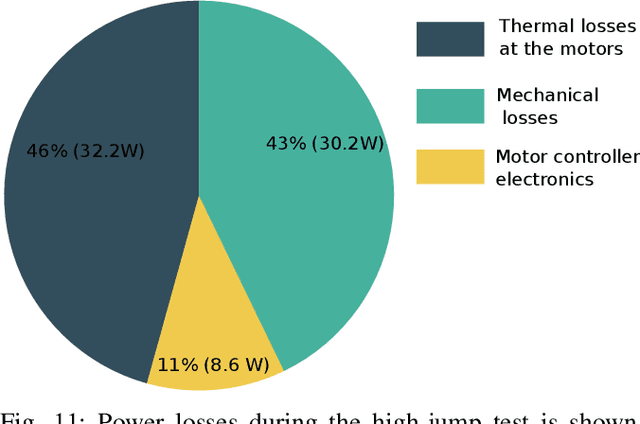
This paper presents design and experimental evaluations of an articulated robotic limb called Capler-Leg. The key element of Capler-Leg is its single-stage cable-pulley transmission combined with a high-gap radius motor. Our cable-pulley system is designed to be as light-weight as possible and to additionally serve as the primary cooling element, thus significantly increasing the power density and efficiency of the overall system. The total weight of active elements on the leg, i.e. the stators and the rotors, contribute more than 60% of the total leg weight, which is an order of magnitude higher than most existing robots. The resulting robotic leg has low inertia, high torque transparency, low manufacturing cost, no backlash, and a low number of parts. Capler-Leg system itself, serves as an experimental setup for evaluating the proposed cable- pulley design in terms of robustness and efficiency. A continuous jump experiment shows a remarkable 96.5 % recuperation rate, measured at the battery output. This means that almost all the mechanical energy output used during push-off returned back to the battery during touch-down.