 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhance audio generation controllability through representation similarity regularization
Sep 15, 2023This paper presents an innovative approach to enhance control over audio generation by emphasizing the alignment between audio and text representations during model training. In the context of language model-based audio generation, the model leverages input from both textual and audio token representations to predict subsequent audio tokens. However, the current configuration lacks explicit regularization to ensure the alignment between the chosen text representation and the language model's predictions. Our proposal involves the incorporation of audio and text representation regularization, particularly during the classifier-free guidance (CFG) phase, where the text condition is excluded from cross attention during language model training. The aim of this proposed representation regularization is to minimize discrepancies in audio and text similarity compared to other samples within the same training batch. Experimental results on both music and audio generation tasks demonstrate that our proposed methods lead to improvements in objective metrics for both audio and music generation, as well as an enhancement in the human perception for audio generation.
Stack-and-Delay: a new codebook pattern for music generation
Sep 15, 2023In language modeling based music generation, a generated waveform is represented by a sequence of hierarchical token stacks that can be decoded either in an auto-regressive manner or in parallel, depending on the codebook patterns. In particular, flattening the codebooks represents the highest quality decoding strategy, while being notoriously slow. To this end, we propose a novel stack-and-delay style of decoding strategy to improve upon the flat pattern decoding where generation speed is four times faster as opposed to vanilla flat decoding. This brings the inference time close to that of the delay decoding strategy, and allows for faster inference on GPU for small batch sizes. For the same inference efficiency budget as the delay pattern, we show that the proposed approach performs better in objective evaluations, almost closing the gap with the flat pattern in terms of quality. The results are corroborated by subjective evaluations which show that samples generated by the new model are slightly more often preferred to samples generated by the competing model given the same text prompts.
TODM: Train Once Deploy Many Efficient Supernet-Based RNN-T Compression For On-device ASR Models
Sep 05, 2023



Automatic Speech Recognition (ASR) models need to be optimized for specific hardware before they can be deployed on devices. This can be done by tuning the model's hyperparameters or exploring variations in its architecture. Re-training and re-validating models after making these changes can be a resource-intensive task. This paper presents TODM (Train Once Deploy Many), a new approach to efficiently train many sizes of hardware-friendly on-device ASR models with comparable GPU-hours to that of a single training job. TODM leverages insights from prior work on Supernet, where Recurrent Neural Network Transducer (RNN-T) models share weights within a Supernet. It reduces layer sizes and widths of the Supernet to obtain subnetworks, making them smaller models suitable for all hardware types. We introduce a novel combination of three techniques to improve the outcomes of the TODM Supernet: adaptive dropouts, an in-place Alpha-divergence knowledge distillation, and the use of ScaledAdam optimizer. We validate our approach by comparing Supernet-trained versus individually tuned Multi-Head State Space Model (MH-SSM) RNN-T using LibriSpeech. Results demonstrate that our TODM Supernet either matches or surpasses the performance of manually tuned models by up to a relative of 3% better in word error rate (WER), while efficiently keeping the cost of training many models at a small constant.
Revisiting Sample Size Determination in Natural Language Understanding
Jul 01, 2023



Knowing exactly how many data points need to be labeled to achieve a certain model performance is a hugely beneficial step towards reducing the overall budgets for annotation. It pertains to both active learning and traditional data annotation, and is particularly beneficial for low resource scenarios. Nevertheless, it remains a largely under-explored area of research in NLP. We therefore explored various techniques for estimating the training sample size necessary to achieve a targeted performance value. We derived a simple yet effective approach to predict the maximum achievable model performance based on small amount of training samples - which serves as an early indicator during data annotation for data quality and sample size determination. We performed ablation studies on four language understanding tasks, and showed that the proposed approach allows us to forecast model performance within a small margin of mean absolute error (~ 0.9%) with only 10% data.
Mixture-of-Supernets: Improving Weight-Sharing Supernet Training with Architecture-Routed Mixture-of-Experts
Jun 08, 2023



Weight-sharing supernet has become a vital component for performance estimation in the state-of-the-art (SOTA) neural architecture search (NAS) frameworks. Although supernet can directly generate different subnetworks without retraining, there is no guarantee for the quality of these subnetworks because of weight sharing. In NLP tasks such as machine translation and pre-trained language modeling, we observe that given the same model architecture, there is a large performance gap between supernet and training from scratch. Hence, supernet cannot be directly used and retraining is necessary after finding the optimal architectures. In this work, we propose mixture-of-supernets, a generalized supernet formulation where mixture-of-experts (MoE) is adopted to enhance the expressive power of the supernet model, with negligible training overhead. In this way, different subnetworks do not share the model weights directly, but through an architecture-based routing mechanism. As a result, model weights of different subnetworks are customized towards their specific architectures and the weight generation is learned by gradient descent. Compared to existing weight-sharing supernet for NLP, our method can minimize the retraining time, greatly improving training efficiency. In addition, the proposed method achieves the SOTA performance in NAS for building fast machine translation models, yielding better latency-BLEU tradeoff compared to HAT, state-of-the-art NAS for MT. We also achieve the SOTA performance in NAS for building memory-efficient task-agnostic BERT models, outperforming NAS-BERT and AutoDistil in various model sizes.
LLM-QAT: Data-Free Quantization Aware Training for Large Language Models
May 29, 2023



Several post-training quantization methods have been applied to large language models (LLMs), and have been shown to perform well down to 8-bits. We find that these methods break down at lower bit precision, and investigate quantization aware training for LLMs (LLM-QAT) to push quantization levels even further. We propose a data-free distillation method that leverages generations produced by the pre-trained model, which better preserves the original output distribution and allows quantizing any generative model independent of its training data, similar to post-training quantization methods. In addition to quantizing weights and activations, we also quantize the KV cache, which is critical for increasing throughput and support long sequence dependencies at current model sizes. We experiment with LLaMA models of sizes 7B, 13B, and 30B, at quantization levels down to 4-bits. We observe large improvements over training-free methods, especially in the low-bit settings.
PathFusion: Path-consistent Lidar-Camera Deep Feature Fusion
Dec 12, 2022Fusing camera with LiDAR is a promising technique to improve the accuracy of 3D detection due to the complementary physical properties. While most existing methods focus on fusing camera features directly with raw LiDAR point clouds or shallow 3D features, it is observed that direct deep 3D feature fusion achieves inferior accuracy due to feature misalignment. The misalignment that originates from the feature aggregation across large receptive fields becomes increasingly severe for deep network stages. In this paper, we propose PathFusion to enable path-consistent LiDAR-camera deep feature fusion. PathFusion introduces a path consistency loss between shallow and deep features, which encourages the 2D backbone and its fusion path to transform 2D features in a way that is semantically aligned with the transform of the 3D backbone. We apply PathFusion to the prior-art fusion baseline, Focals Conv, and observe more than 1.2\% mAP improvements on the nuScenes test split consistently with and without testing-time augmentations. Moreover, PathFusion also improves KITTI AP3D (R11) by more than 0.6% on moderate level.
SDRM3: A Dynamic Scheduler for Dynamic Real-time Multi-model ML Workloads
Dec 07, 2022



Emerging real-time multi-model ML (RTMM) workloads such as AR/VR and drone control often involve dynamic behaviors in various levels; task, model, and layers (or, ML operators) within a model. Such dynamic behaviors are new challenges to the system software in an ML system because the overall system load is unpredictable unlike traditional ML workloads. Also, the real-time processing requires to meet deadlines, and multi-model workloads involve highly heterogeneous models. As RTMM workloads often run on resource-constrained devices (e.g., VR headset), developing an effective scheduler is an important research problem. Therefore, we propose a new scheduler, SDRM3, that effectively handles various dynamicity in RTMM style workloads targeting multi-accelerator systems. To make scheduling decisions, SDRM3 quantifies the unique requirements for RTMM workloads and utilizes the quantified scores to drive scheduling decisions, considering the current system load and other inference jobs on different models and input frames. SDRM3 has tunable parameters that provide fast adaptivity to dynamic workload changes based on a gradient descent-like online optimization, which typically converges within five steps for new workloads. In addition, we also propose a method to exploit model level dynamicity based on Supernet for exploiting the trade-off between the scheduling effectiveness and model performance (e.g., accuracy), which dynamically selects a proper sub-network in a Supernet based on the system loads. In our evaluation on five realistic RTMM workload scenarios, SDRM3 reduces the overall UXCost, which is a energy-delay-product (EDP)-equivalent metric for real-time applications defined in the paper, by 37.7% and 53.2% on geometric mean (up to 97.6% and 97.1%) compared to state-of-the-art baselines, which shows the efficacy of our scheduling methodology.
Fast Point Cloud Generation with Straight Flows
Dec 04, 2022



Diffusion models have emerged as a powerful tool for point cloud generation. A key component that drives the impressive performance for generating high-quality samples from noise is iteratively denoise for thousands of steps. While beneficial, the complexity of learning steps has limited its applications to many 3D real-world. To address this limitation, we propose Point Straight Flow (PSF), a model that exhibits impressive performance using one step. Our idea is based on the reformulation of the standard diffusion model, which optimizes the curvy learning trajectory into a straight path. Further, we develop a distillation strategy to shorten the straight path into one step without a performance loss, enabling applications to 3D real-world with latency constraints. We perform evaluations on multiple 3D tasks and find that our PSF performs comparably to the standard diffusion model, outperforming other efficient 3D point cloud generation methods. On real-world applications such as point cloud completion and training-free text-guided generation in a low-latency setup, PSF performs favorably.
XRBench: An Extended Reality (XR) Machine Learning Benchmark Suite for the Metaverse
Nov 16, 2022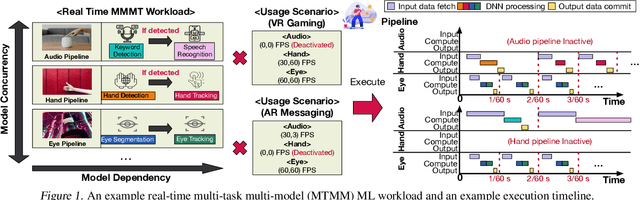
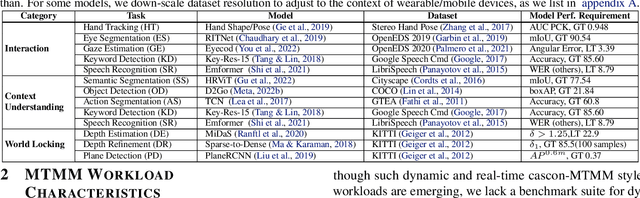

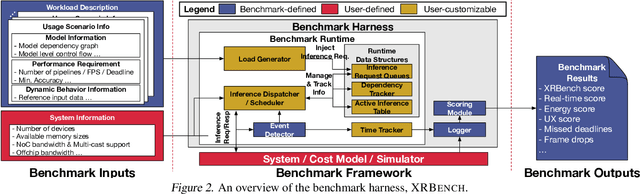
Real-time multi-model multi-task (MMMT) workloads, a new form of deep learning inference workloads, are emerging for applications areas like extended reality (XR) to support metaverse use cases. These workloads combine user interactivity with computationally complex machine learning (ML) activities. Compared to standard ML applications, these ML workloads present unique difficulties and constraints. Real-time MMMT workloads impose heterogeneity and concurrency requirements on future ML systems and devices, necessitating the development of new capabilities. This paper begins with a discussion of the various characteristics of these real-time MMMT ML workloads and presents an ontology for evaluating the performance of future ML hardware for XR systems. Next, we present XRBench, a collection of MMMT ML tasks, models, and usage scenarios that execute these models in three representative ways: cascaded, concurrent, and cascaded-concurrency for XR use cases. Finally, we emphasize the need for new metrics that capture the requirements properly. We hope that our work will stimulate research and lead to the development of a new generation of ML systems for XR use cases.