 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Attention Emerges from Recurrent Sparse Reconstruction
Apr 23, 2022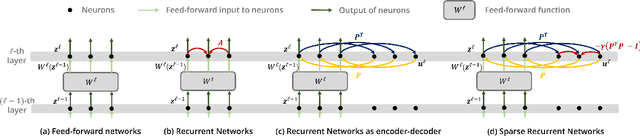
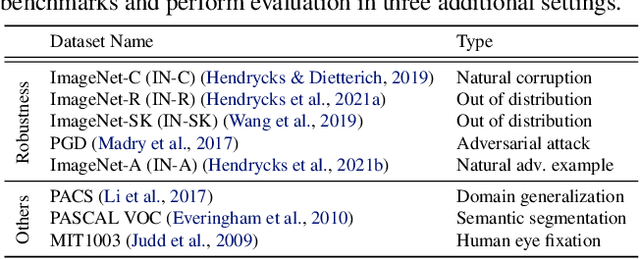
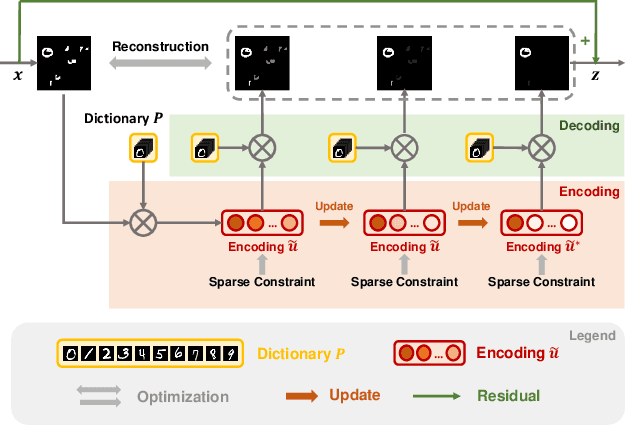
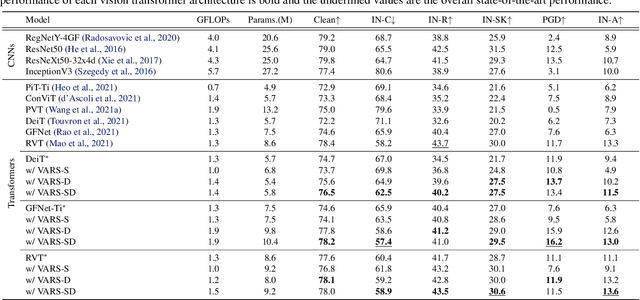
Visual attention helps achieve robust perception under noise, corruption, and distribution shifts in human vision, which are areas where modern neural networks still fall short. We present VARS, Visual Attention from Recurrent Sparse reconstruction, a new attention formulation built on two prominent features of the human visual attention mechanism: recurrency and sparsity. Related features are grouped together via recurrent connections between neurons, with salient objects emerging via sparse regularization. VARS adopts an attractor network with recurrent connections that converges toward a stable pattern over time. Network layers are represented as ordinary differential equations (ODEs), formulating attention as a recurrent attractor network that equivalently optimizes the sparse reconstruction of input using a dictionary of "templates" encoding underlying patterns of data. We show that self-attention is a special case of VARS with a single-step optimization and no sparsity constraint. VARS can be readily used as a replacement for self-attention in popular vision transformers, consistently improving their robustness across various benchmarks. Code is released on GitHub (https://github.com/bfshi/VARS).
Contrastive Test-Time Adaptation
Apr 21, 2022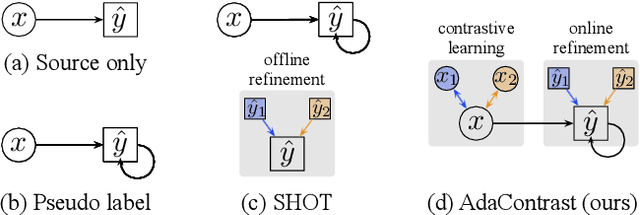
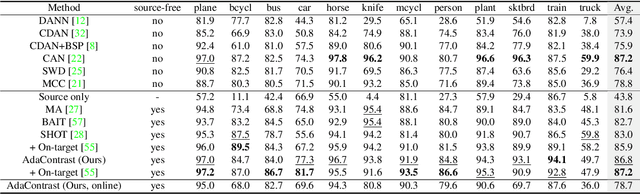
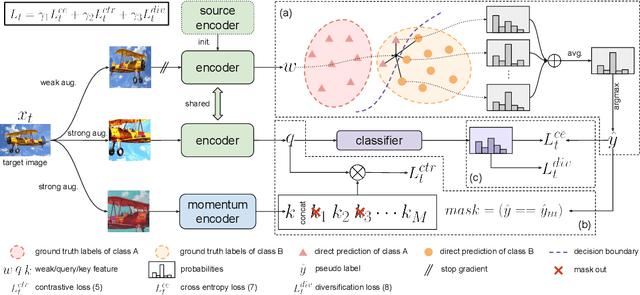
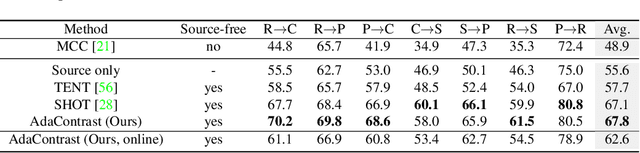
Test-time adaptation is a special setting of unsupervised domain adaptation where a trained model on the source domain has to adapt to the target domain without accessing source data. We propose a novel way to leverage self-supervised contrastive learning to facilitate target feature learning, along with an online pseudo labeling scheme with refinement that significantly denoises pseudo labels. The contrastive learning task is applied jointly with pseudo labeling, contrasting positive and negative pairs constructed similarly as MoCo but with source-initialized encoder, and excluding same-class negative pairs indicated by pseudo labels. Meanwhile, we produce pseudo labels online and refine them via soft voting among their nearest neighbors in the target feature space, enabled by maintaining a memory queue. Our method, AdaContrast, achieves state-of-the-art performance on major benchmarks while having several desirable properties compared to existing works, including memory efficiency, insensitivity to hyper-parameters, and better model calibration. Project page: sites.google.com/view/adacontrast.
K-LITE: Learning Transferable Visual Models with External Knowledge
Apr 20, 2022
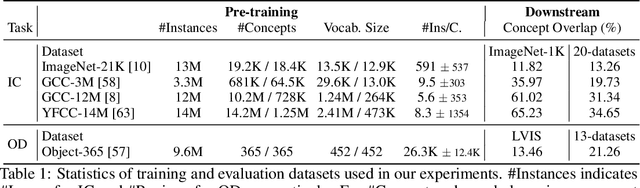
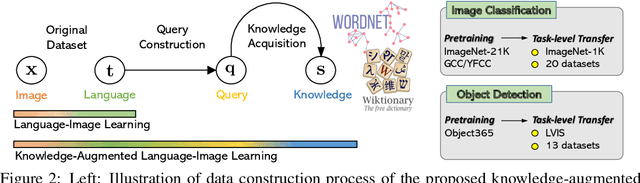
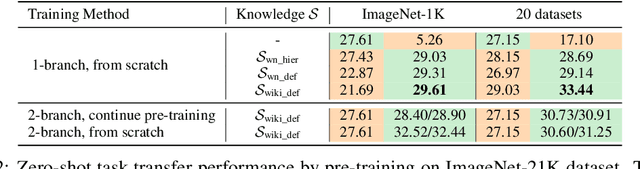
Recent state-of-the-art computer vision systems are trained from natural language supervision, ranging from simple object category names to descriptive captions. This free form of supervision ensures high generality and usability of the learned visual models, based on extensive heuristics on data collection to cover as many visual concepts as possible. Alternatively, learning with external knowledge about images is a promising way which leverages a much more structured source of supervision. In this paper, we propose K-LITE (Knowledge-augmented Language-Image Training and Evaluation), a simple strategy to leverage external knowledge to build transferable visual systems: In training, it enriches entities in natural language with WordNet and Wiktionary knowledge, leading to an efficient and scalable approach to learning image representations that can understand both visual concepts and their knowledge; In evaluation, the natural language is also augmented with external knowledge and then used to reference learned visual concepts (or describe new ones) to enable zero-shot and few-shot transfer of the pre-trained models. We study the performance of K-LITE on two important computer vision problems, image classification and object detection, benchmarking on 20 and 13 different existing datasets, respectively. The proposed knowledge-augmented models show significant improvement in transfer learning performance over existing methods.
Learning to Listen: Modeling Non-Deterministic Dyadic Facial Motion
Apr 18, 2022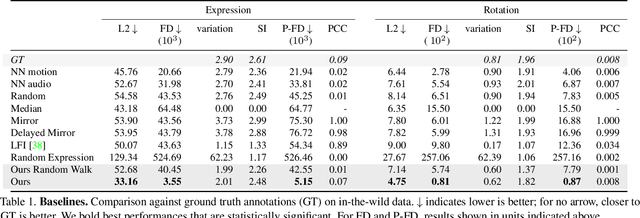
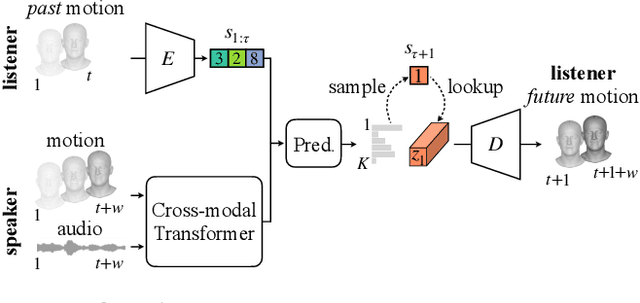
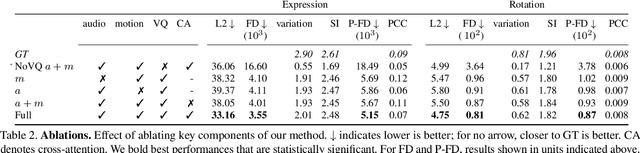
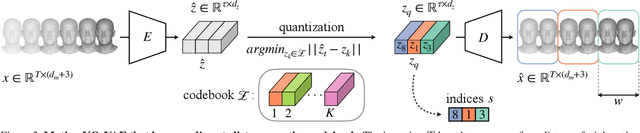
We present a framework for modeling interactional communication in dyadic conversations: given multimodal inputs of a speaker, we autoregressively output multiple possibilities of corresponding listener motion. We combine the motion and speech audio of the speaker using a motion-audio cross attention transformer. Furthermore, we enable non-deterministic prediction by learning a discrete latent representation of realistic listener motion with a novel motion-encoding VQ-VAE. Our method organically captures the multimodal and non-deterministic nature of nonverbal dyadic interactions. Moreover, it produces realistic 3D listener facial motion synchronous with the speaker (see video). We demonstrate that our method outperforms baselines qualitatively and quantitatively via a rich suite of experiments. To facilitate this line of research, we introduce a novel and large in-the-wild dataset of dyadic conversations. Code, data, and videos available at https://evonneng.github.io/learning2listen/.
ReCLIP: A Strong Zero-Shot Baseline for Referring Expression Comprehension
Apr 12, 2022
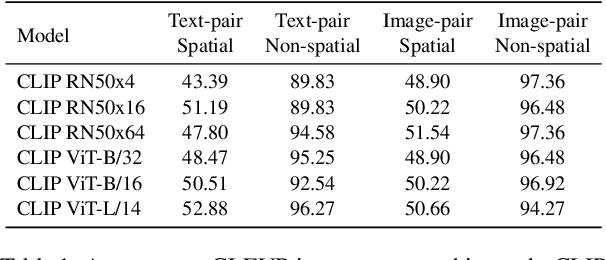
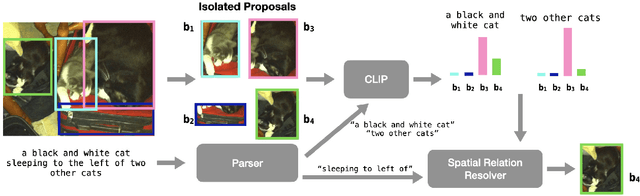
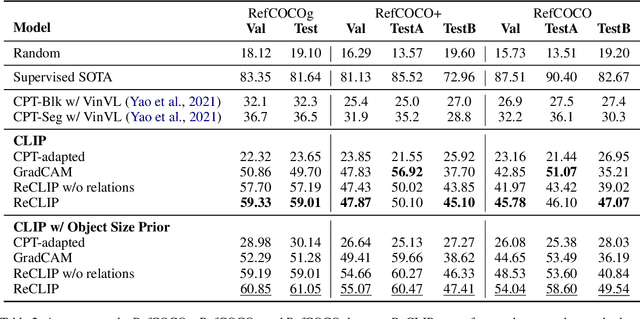
Training a referring expression comprehension (ReC) model for a new visual domain requires collecting referring expressions, and potentially corresponding bounding boxes, for images in the domain. While large-scale pre-trained models are useful for image classification across domains, it remains unclear if they can be applied in a zero-shot manner to more complex tasks like ReC. We present ReCLIP, a simple but strong zero-shot baseline that repurposes CLIP, a state-of-the-art large-scale model, for ReC. Motivated by the close connection between ReC and CLIP's contrastive pre-training objective, the first component of ReCLIP is a region-scoring method that isolates object proposals via cropping and blurring, and passes them to CLIP. However, through controlled experiments on a synthetic dataset, we find that CLIP is largely incapable of performing spatial reasoning off-the-shelf. Thus, the second component of ReCLIP is a spatial relation resolver that handles several types of spatial relations. We reduce the gap between zero-shot baselines from prior work and supervised models by as much as 29% on RefCOCOg, and on RefGTA (video game imagery), ReCLIP's relative improvement over supervised ReC models trained on real images is 8%.
Teachable Reinforcement Learning via Advice Distillation
Mar 19, 2022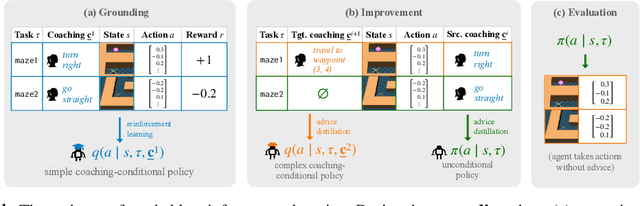
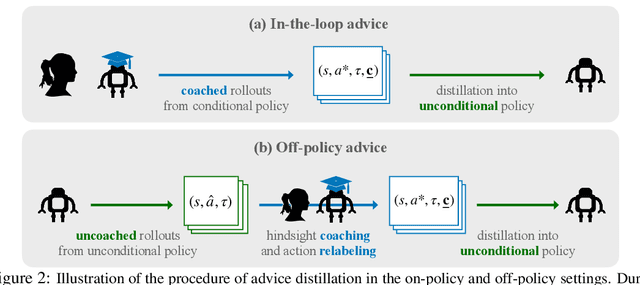
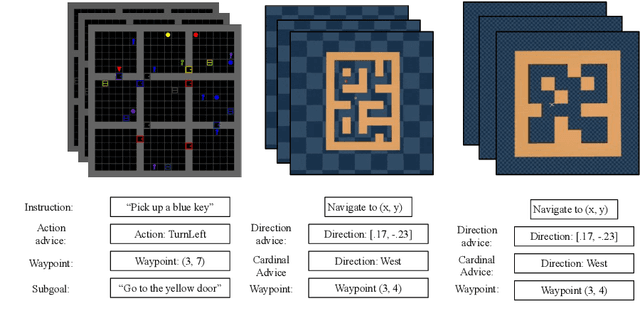
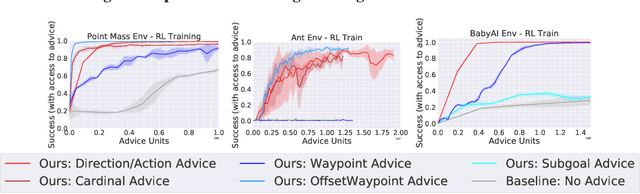
Training automated agents to complete complex tasks in interactive environments is challenging: reinforcement learning requires careful hand-engineering of reward functions, imitation learning requires specialized infrastructure and access to a human expert, and learning from intermediate forms of supervision (like binary preferences) is time-consuming and extracts little information from each human intervention. Can we overcome these challenges by building agents that learn from rich, interactive feedback instead? We propose a new supervision paradigm for interactive learning based on "teachable" decision-making systems that learn from structured advice provided by an external teacher. We begin by formalizing a class of human-in-the-loop decision making problems in which multiple forms of teacher-provided advice are available to a learner. We then describe a simple learning algorithm for these problems that first learns to interpret advice, then learns from advice to complete tasks even in the absence of human supervision. In puzzle-solving, navigation, and locomotion domains, we show that agents that learn from advice can acquire new skills with significantly less human supervision than standard reinforcement learning algorithms and often less than imitation learning.
Masked Visual Pre-training for Motor Control
Mar 11, 2022
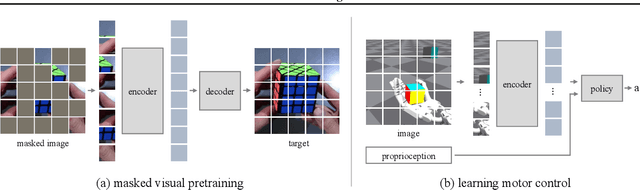

This paper shows that self-supervised visual pre-training from real-world images is effective for learning motor control tasks from pixels. We first train the visual representations by masked modeling of natural images. We then freeze the visual encoder and train neural network controllers on top with reinforcement learning. We do not perform any task-specific fine-tuning of the encoder; the same visual representations are used for all motor control tasks. To the best of our knowledge, this is the first self-supervised model to exploit real-world images at scale for motor control. To accelerate progress in learning from pixels, we contribute a benchmark suite of hand-designed tasks varying in movements, scenes, and robots. Without relying on labels, state-estimation, or expert demonstrations, we consistently outperform supervised encoders by up to 80% absolute success rate, sometimes even matching the oracle state performance. We also find that in-the-wild images, e.g., from YouTube or Egocentric videos, lead to better visual representations for various manipulation tasks than ImageNet images.
On Guiding Visual Attention with Language Specification
Feb 17, 2022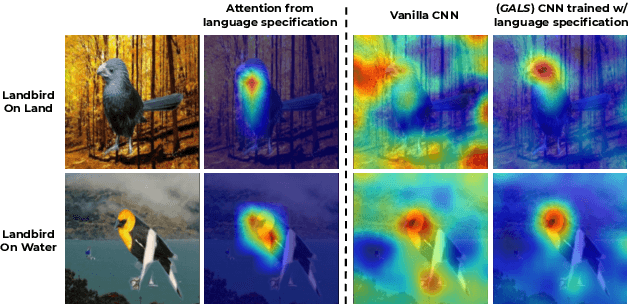

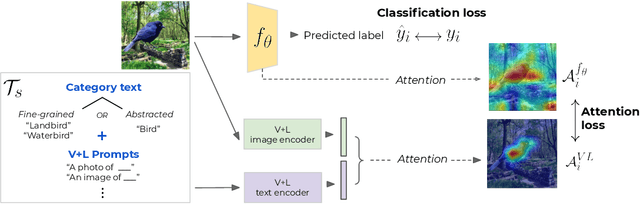
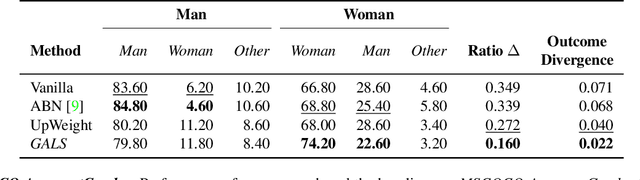
While real world challenges typically define visual categories with language words or phrases, most visual classification methods define categories with numerical indices. However, the language specification of the classes provides an especially useful prior for biased and noisy datasets, where it can help disambiguate what features are task-relevant. Recently, large-scale multimodal models have been shown to recognize a wide variety of high-level concepts from a language specification even without additional image training data, but they are often unable to distinguish classes for more fine-grained tasks. CNNs, in contrast, can extract subtle image features that are required for fine-grained discrimination, but will overfit to any bias or noise in datasets. Our insight is to use high-level language specification as advice for constraining the classification evidence to task-relevant features, instead of distractors. To do this, we ground task-relevant words or phrases with attention maps from a pretrained large-scale model. We then use this grounding to supervise a classifier's spatial attention away from distracting context. We show that supervising spatial attention in this way improves performance on classification tasks with biased and noisy data, including about 3-15% worst-group accuracy improvements and 41-45% relative improvements on fairness metrics.
Explaining Reinforcement Learning Policies through Counterfactual Trajectories
Jan 29, 2022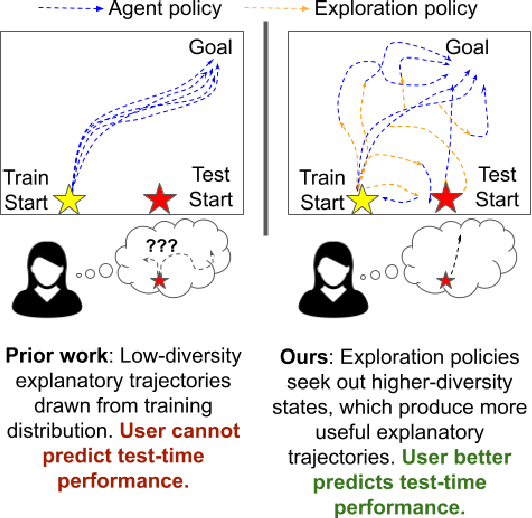
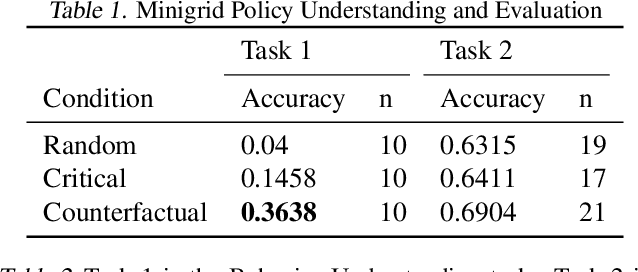
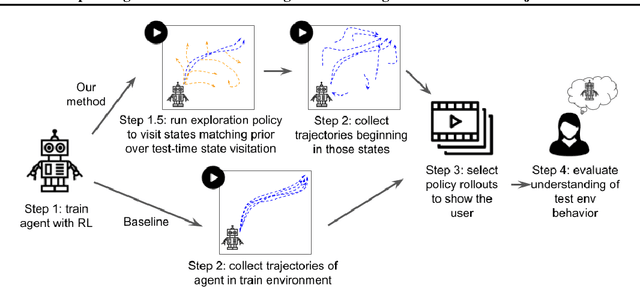
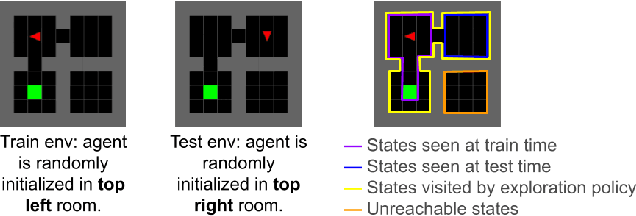
In order for humans to confidently decide where to employ RL agents for real-world tasks, a human developer must validate that the agent will perform well at test-time. Some policy interpretability methods facilitate this by capturing the policy's decision making in a set of agent rollouts. However, even the most informative trajectories of training time behavior may give little insight into the agent's behavior out of distribution. In contrast, our method conveys how the agent performs under distribution shifts by showing the agent's behavior across a wider trajectory distribution. We generate these trajectories by guiding the agent to more diverse unseen states and showing the agent's behavior there. In a user study, we demonstrate that our method enables users to score better than baseline methods on one of two agent validation tasks.
A ConvNet for the 2020s
Jan 10, 2022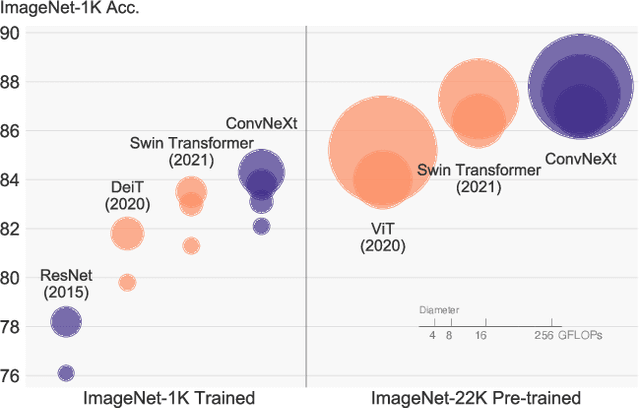
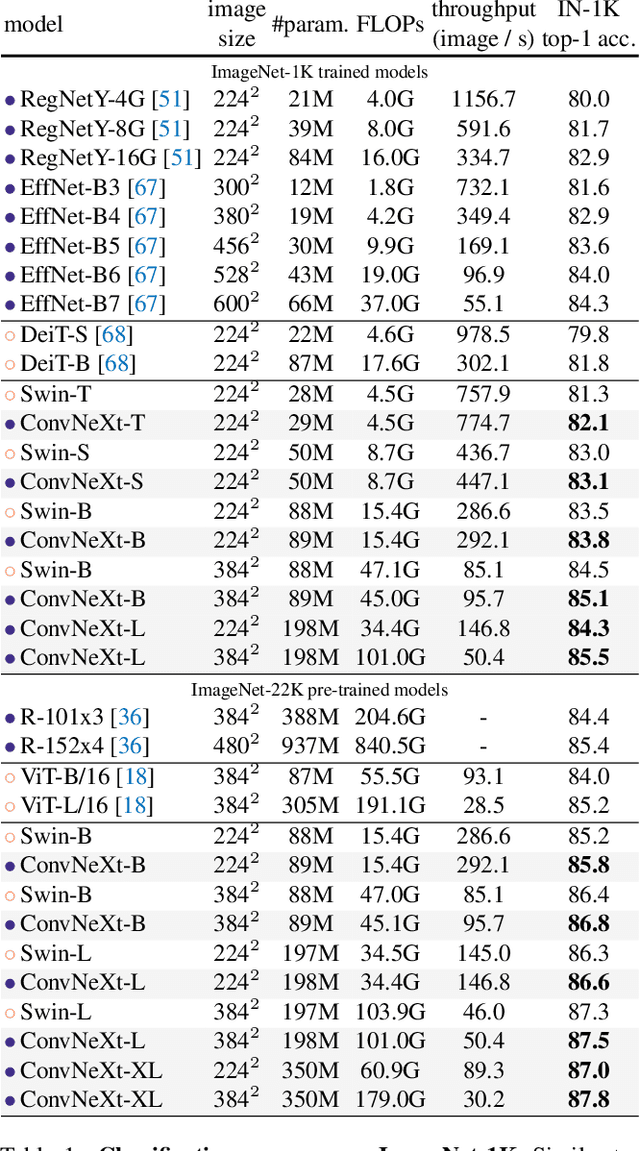
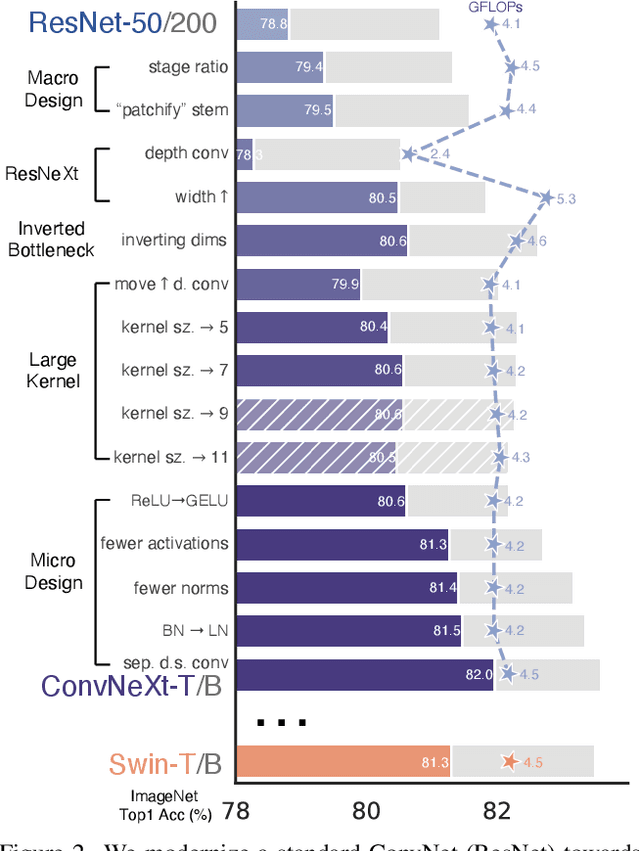
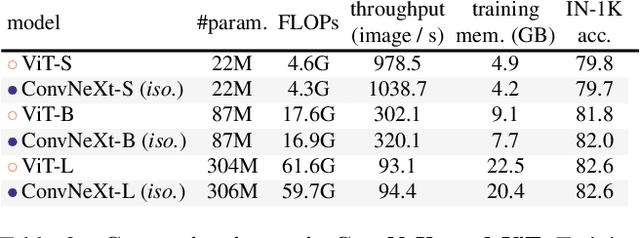
The "Roaring 20s" of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers (e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually "modernize" a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.