 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching According to Students' Aptitude: Personalized Mathematics Tutoring via Persona-, Memory-, and Forgetting-Aware LLMs
Nov 19, 2025Large Language Models (LLMs) are increasingly integrated into intelligent tutoring systems to provide human-like and adaptive instruction. However, most existing approaches fail to capture how students' knowledge evolves dynamically across their proficiencies, conceptual gaps, and forgetting patterns. This challenge is particularly acute in mathematics tutoring, where effective instruction requires fine-grained scaffolding precisely calibrated to each student's mastery level and cognitive retention. To address this issue, we propose TASA (Teaching According to Students' Aptitude), a student-aware tutoring framework that integrates persona, memory, and forgetting dynamics for personalized mathematics learning. Specifically, TASA maintains a structured student persona capturing proficiency profiles and an event memory recording prior learning interactions. By incorporating a continuous forgetting curve with knowledge tracing, TASA dynamically updates each student's mastery state and generates contextually appropriate, difficulty-calibrated questions and explanations. Empirical results demonstrate that TASA achieves superior learning outcomes and more adaptive tutoring behavior compared to representative baselines, underscoring the importance of modeling temporal forgetting and learner profiles in LLM-based tutoring systems.
Free Lunch to Meet the Gap: Intermediate Domain Reconstruction for Cross-Domain Few-Shot Learning
Nov 18, 2025Cross-Domain Few-Shot Learning (CDFSL) endeavors to transfer generalized knowledge from the source domain to target domains using only a minimal amount of training data, which faces a triplet of learning challenges in the meantime, i.e., semantic disjoint, large domain discrepancy, and data scarcity. Different from predominant CDFSL works focused on generalized representations, we make novel attempts to construct Intermediate Domain Proxies (IDP) with source feature embeddings as the codebook and reconstruct the target domain feature with this learned codebook. We then conduct an empirical study to explore the intrinsic attributes from perspectives of visual styles and semantic contents in intermediate domain proxies. Reaping benefits from these attributes of intermediate domains, we develop a fast domain alignment method to use these proxies as learning guidance for target domain feature transformation. With the collaborative learning of intermediate domain reconstruction and target feature transformation, our proposed model is able to surpass the state-of-the-art models by a margin on 8 cross-domain few-shot learning benchmarks.
Lean4Physics: Comprehensive Reasoning Framework for College-level Physics in Lean4
Oct 30, 2025We present **Lean4PHYS**, a comprehensive reasoning framework for college-level physics problems in Lean4. **Lean4PHYS** includes *LeanPhysBench*, a college-level benchmark for formal physics reasoning in Lean4, which contains 200 hand-crafted and peer-reviewed statements derived from university textbooks and physics competition problems. To establish a solid foundation for formal reasoning in physics, we also introduce *PhysLib*, a community-driven repository containing fundamental unit systems and theorems essential for formal physics reasoning. Based on the benchmark and Lean4 repository we composed in **Lean4PHYS**, we report baseline results using major expert Math Lean4 provers and state-of-the-art closed-source models, with the best performance of DeepSeek-Prover-V2-7B achieving only 16% and Claude-Sonnet-4 achieving 35%. We also conduct a detailed analysis showing that our *PhysLib* can achieve an average improvement of 11.75% in model performance. This demonstrates the challenging nature of our *LeanPhysBench* and the effectiveness of *PhysLib*. To the best of our knowledge, this is the first study to provide a physics benchmark in Lean4.
Edge Collaborative Gaussian Splatting with Integrated Rendering and Communication
Oct 26, 2025Gaussian splatting (GS) struggles with degraded rendering quality on low-cost devices. To address this issue, we present edge collaborative GS (ECO-GS), where each user can switch between a local small GS model to guarantee timeliness and a remote large GS model to guarantee fidelity. However, deciding how to engage the large GS model is nontrivial, due to the interdependency between rendering requirements and resource conditions. To this end, we propose integrated rendering and communication (IRAC), which jointly optimizes collaboration status (i.e., deciding whether to engage large GS) and edge power allocation (i.e., enabling remote rendering) under communication constraints across different users by minimizing a newly-derived GS switching function. Despite the nonconvexity of the problem, we propose an efficient penalty majorization minimization (PMM) algorithm to obtain the critical point solution. Furthermore, we develop an imitation learning optimization (ILO) algorithm, which reduces the computational time by over 100x compared to PMM. Experiments demonstrate the superiority of PMM and the real-time execution capability of ILO.
ERA: Transforming VLMs into Embodied Agents via Embodied Prior Learning and Online Reinforcement Learning
Oct 14, 2025Recent advances in embodied AI highlight the potential of vision language models (VLMs) as agents capable of perception, reasoning, and interaction in complex environments. However, top-performing systems rely on large-scale models that are costly to deploy, while smaller VLMs lack the necessary knowledge and skills to succeed. To bridge this gap, we present \textit{Embodied Reasoning Agent (ERA)}, a two-stage framework that integrates prior knowledge learning and online reinforcement learning (RL). The first stage, \textit{Embodied Prior Learning}, distills foundational knowledge from three types of data: (1) Trajectory-Augmented Priors, which enrich existing trajectory data with structured reasoning generated by stronger models; (2) Environment-Anchored Priors, which provide in-environment knowledge and grounding supervision; and (3) External Knowledge Priors, which transfer general knowledge from out-of-environment datasets. In the second stage, we develop an online RL pipeline that builds on these priors to further enhance agent performance. To overcome the inherent challenges in agent RL, including long horizons, sparse rewards, and training instability, we introduce three key designs: self-summarization for context management, dense reward shaping, and turn-level policy optimization. Extensive experiments on both high-level planning (EB-ALFRED) and low-level control (EB-Manipulation) tasks demonstrate that ERA-3B surpasses both prompting-based large models and previous training-based baselines. Specifically, it achieves overall improvements of 8.4\% on EB-ALFRED and 19.4\% on EB-Manipulation over GPT-4o, and exhibits strong generalization to unseen tasks. Overall, ERA offers a practical path toward scalable embodied intelligence, providing methodological insights for future embodied AI systems.
Reinforce-Ada: An Adaptive Sampling Framework for Reinforce-Style LLM Training
Oct 06, 2025Reinforcement learning applied to large language models (LLMs) for reasoning tasks is often bottlenecked by unstable gradient estimates due to fixed and uniform sampling of responses across prompts. Prior work such as GVM-RAFT addresses this by dynamically allocating inference budget per prompt to minimize stochastic gradient variance under a budget constraint. Inspired by this insight, we propose Reinforce-Ada, an adaptive sampling framework for online RL post-training of LLMs that continuously reallocates sampling effort to the prompts with the greatest uncertainty or learning potential. Unlike conventional two-stage allocation methods, Reinforce-Ada interleaves estimation and sampling in an online successive elimination process, and automatically stops sampling for a prompt once sufficient signal is collected. To stabilize updates, we form fixed-size groups with enforced reward diversity and compute advantage baselines using global statistics aggregated over the adaptive sampling phase. Empirical results across multiple model architectures and reasoning benchmarks show that Reinforce-Ada accelerates convergence and improves final performance compared to GRPO, especially when using the balanced sampling variant. Our work highlights the central role of variance-aware, adaptive data curation in enabling efficient and reliable reinforcement learning for reasoning-capable LLMs. Code is available at https://github.com/RLHFlow/Reinforce-Ada.
Generalizable Geometric Image Caption Synthesis
Sep 18, 2025Multimodal large language models have various practical applications that demand strong reasoning abilities. Despite recent advancements, these models still struggle to solve complex geometric problems. A key challenge stems from the lack of high-quality image-text pair datasets for understanding geometric images. Furthermore, most template-based data synthesis pipelines typically fail to generalize to questions beyond their predefined templates. In this paper, we bridge this gap by introducing a complementary process of Reinforcement Learning with Verifiable Rewards (RLVR) into the data generation pipeline. By adopting RLVR to refine captions for geometric images synthesized from 50 basic geometric relations and using reward signals derived from mathematical problem-solving tasks, our pipeline successfully captures the key features of geometry problem-solving. This enables better task generalization and yields non-trivial improvements. Furthermore, even in out-of-distribution scenarios, the generated dataset enhances the general reasoning capabilities of multimodal large language models, yielding accuracy improvements of $2.8\%\text{-}4.8\%$ in statistics, arithmetic, algebraic, and numerical tasks with non-geometric input images of MathVista and MathVerse, along with $2.4\%\text{-}3.9\%$ improvements in Art, Design, Tech, and Engineering tasks in MMMU.
Theoretical Analysis on how Learning Rate Warmup Accelerates Convergence
Sep 09, 2025Learning rate warmup is a popular and practical technique in training large-scale deep neural networks. Despite the huge success in practice, the theoretical advantages of this strategy of gradually increasing the learning rate at the beginning of the training process have not been fully understood. To resolve this gap between theory and practice, we first propose a novel family of generalized smoothness assumptions, and validate its applicability both theoretically and empirically. Under the novel smoothness assumption, we study the convergence properties of gradient descent (GD) in both deterministic and stochastic settings. It is shown that learning rate warmup consistently accelerates GD, and GD with warmup can converge at most $\Theta(T)$ times faster than with a non-increasing learning rate schedule in some specific cases, providing insights into the benefits of this strategy from an optimization theory perspective.
CANDY: Benchmarking LLMs' Limitations and Assistive Potential in Chinese Misinformation Fact-Checking
Sep 04, 2025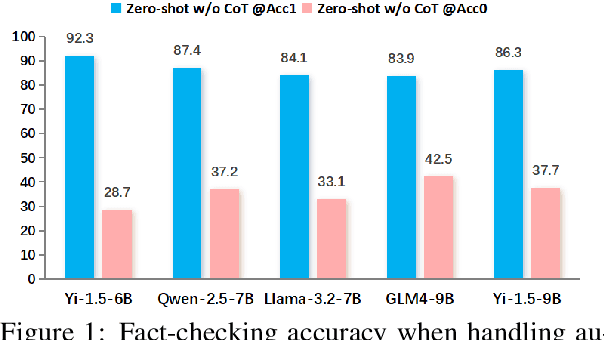
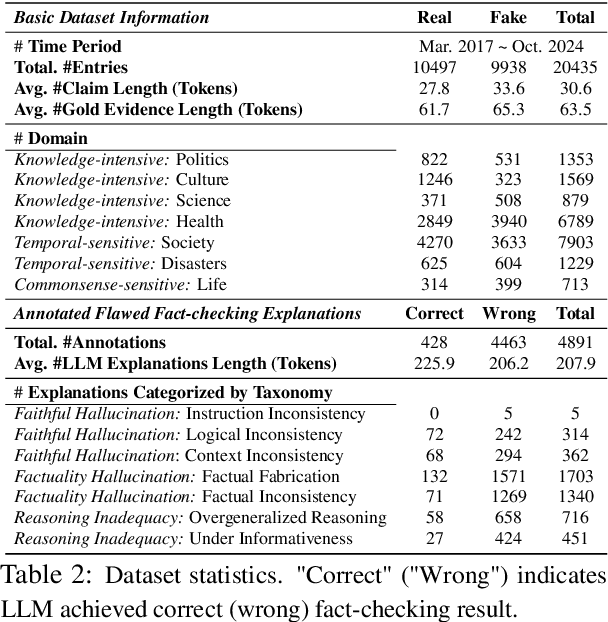
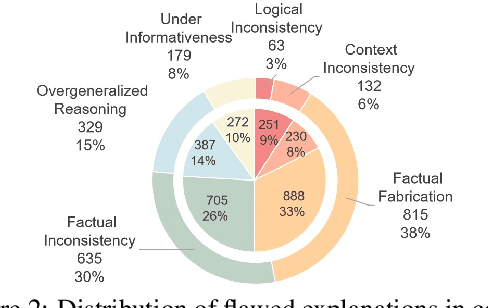

The effectiveness of large language models (LLMs) to fact-check misinformation remains uncertain, despite their growing use. To this end, we present CANDY, a benchmark designed to systematically evaluate the capabilities and limitations of LLMs in fact-checking Chinese misinformation. Specifically, we curate a carefully annotated dataset of ~20k instances. Our analysis shows that current LLMs exhibit limitations in generating accurate fact-checking conclusions, even when enhanced with chain-of-thought reasoning and few-shot prompting. To understand these limitations, we develop a taxonomy to categorize flawed LLM-generated explanations for their conclusions and identify factual fabrication as the most common failure mode. Although LLMs alone are unreliable for fact-checking, our findings indicate their considerable potential to augment human performance when deployed as assistive tools in scenarios. Our dataset and code can be accessed at https://github.com/SCUNLP/CANDY
Beyond Correctness: Harmonizing Process and Outcome Rewards through RL Training
Sep 03, 2025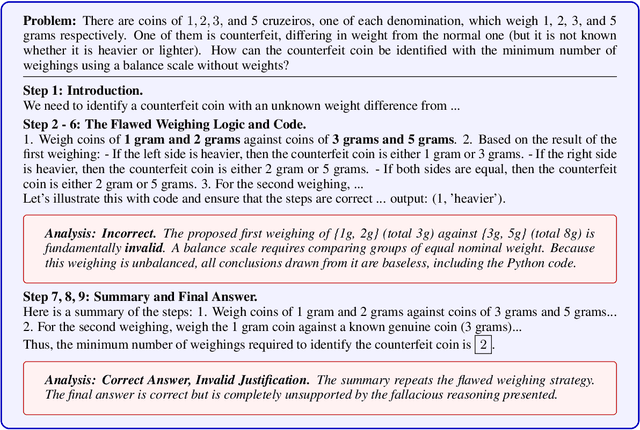

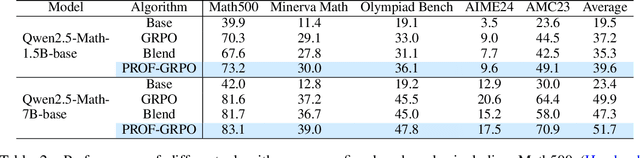
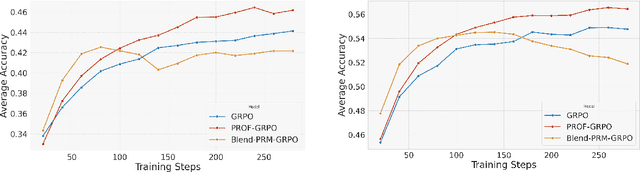
Reinforcement learning with verifiable rewards (RLVR) has emerged to be a predominant paradigm for mathematical reasoning tasks, offering stable improvements in reasoning ability. However, Outcome Reward Models (ORMs) in RLVR are too coarse-grained to distinguish flawed reasoning within correct answers or valid reasoning within incorrect answers. This lack of granularity introduces noisy and misleading gradients significantly and hinders further progress in reasoning process quality. While Process Reward Models (PRMs) offer fine-grained guidance for intermediate steps, they frequently suffer from inaccuracies and are susceptible to reward hacking. To resolve this dilemma, we introduce PRocess cOnsistency Filter (PROF), an effective data process curation method that harmonizes noisy, fine-grained process rewards with accurate, coarse-grained outcome rewards. Rather than naively blending PRM and ORM in the objective function (arXiv:archive/2506.18896), PROF leverages their complementary strengths through consistency-driven sample selection. Our approach retains correct responses with higher averaged process values and incorrect responses with lower averaged process values, while maintaining positive/negative training sample balance. Extensive experiments demonstrate that our method not only consistently improves the final accuracy over $4\%$ compared to the blending approaches, but also strengthens the quality of intermediate reasoning steps. Codes and training recipes are available at https://github.com/Chenluye99/PROF.