 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Lost Information in Lossy Image Compression
Jul 08, 2020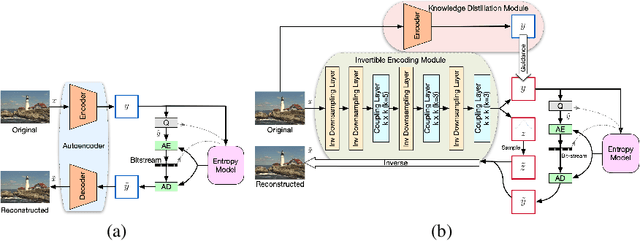
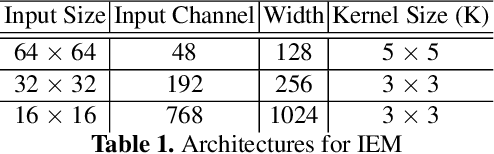

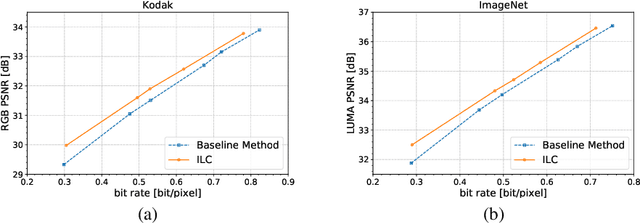
Lossy image compression is one of the most commonly used operators for digital images. Most recently proposed deep-learning-based image compression methods leverage the auto-encoder structure, and reach a series of promising results in this field. The images are encoded into low dimensional latent features first, and entropy coded subsequently by exploiting the statistical redundancy. However, the information lost during encoding is unfortunately inevitable, which poses a significant challenge to the decoder to reconstruct the original images. In this work, we propose a novel invertible framework called Invertible Lossy Compression (ILC) to largely mitigate the information loss problem. Specifically, ILC introduces an invertible encoding module to replace the encoder-decoder structure to produce the low dimensional informative latent representation, meanwhile, transform the lost information into an auxiliary latent variable that won't be further coded or stored. The latent representation is quantized and encoded into bit-stream, and the latent variable is forced to follow a specified distribution, i.e. isotropic Gaussian distribution. In this way, recovering the original image is made tractable by easily drawing a surrogate latent variable and applying the inverse pass of the module with the sampled variable and decoded latent features. Experimental results demonstrate that with a new component replacing the auto-encoder in image compression methods, ILC can significantly outperform the baseline method on extensive benchmark datasets by combining with the existing compression algorithms.
Dynamic of Stochastic Gradient Descent with State-Dependent Noise
Jul 06, 2020
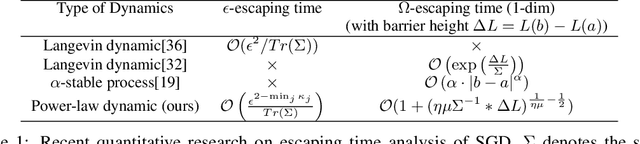
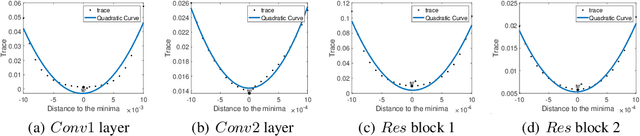
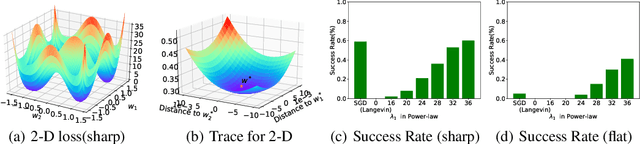
Stochastic gradient descent (SGD) and its variants are mainstream methods to train deep neural networks. Since neural networks are non-convex, more and more works study the dynamic behavior of SGD and the impact to its generalization, especially the escaping efficiency from local minima. However, these works take the over-simplified assumption that the covariance of the noise in SGD is (or can be upper bounded by) constant, although it is actually state-dependent. In this work, we conduct a formal study on the dynamic behavior of SGD with state-dependent noise. Specifically, we show that the covariance of the noise of SGD in the local region of the local minima is a quadratic function of the state. Thus, we propose a novel power-law dynamic with state-dependent diffusion to approximate the dynamic of SGD. We prove that, power-law dynamic can escape from sharp minima exponentially faster than flat minima, while the previous dynamics can only escape sharp minima polynomially faster than flat minima. Our experiments well verified our theoretical results. Inspired by our theory, we propose to add additional state-dependent noise into (large-batch) SGD to further improve its generalization ability. Experiments verify that our method is effective.
FastSpeech 2: Fast and High-Quality End-to-End Text to Speech
Jun 22, 2020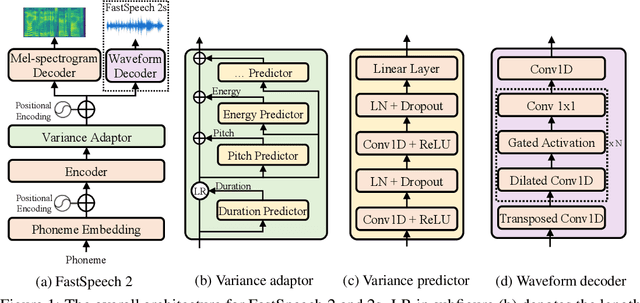
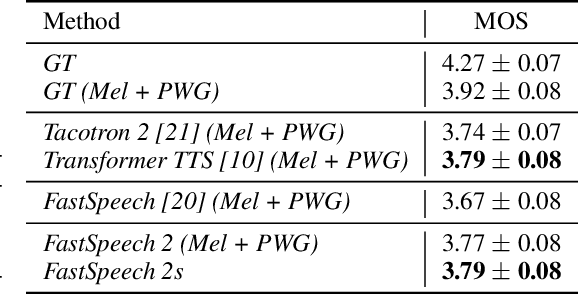
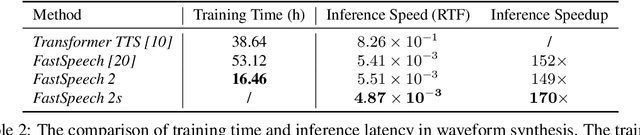
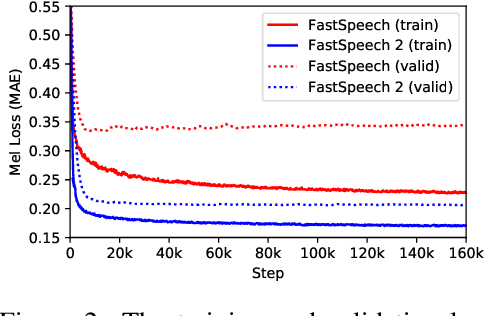
Advanced text to speech (TTS) models such as FastSpeech can synthesize speech significantly faster than previous autoregressive models with comparable quality. The training of FastSpeech model relies on an autoregressive teacher model for duration prediction (to provide more information as input) and knowledge distillation (to simplify the data distribution in output), which can ease the one-to-many mapping problem (i.e., multiple speech variations correspond to the same text) in TTS. However, FastSpeech has several disadvantages: 1) the teacher-student distillation pipeline is complicated, 2) the duration extracted from the teacher model is not accurate enough, and the target mel-spectrograms distilled from teacher model suffer from information loss due to data simplification, both of which limit the voice quality. In this paper, we propose FastSpeech 2, which addresses the issues in FastSpeech and better solves the one-to-many mapping problem in TTS by 1) directly training the model with ground-truth target instead of the simplified output from teacher, and 2) introducing more variation information of speech (e.g., pitch, energy and more accurate duration) as conditional inputs. Specifically, we extract duration, pitch and energy from speech waveform and directly take them as conditional inputs during training and use predicted values during inference. We further design FastSpeech 2s, which is the first attempt to directly generate speech waveform from text in parallel, enjoying the benefit of full end-to-end training and even faster inference than FastSpeech. Experimental results show that 1) FastSpeech 2 and 2s outperform FastSpeech in voice quality with much simplified training pipeline and reduced training time; 2) FastSpeech 2 and 2s can match the voice quality of autoregressive models while enjoying much faster inference speed.
Multi-branch Attentive Transformer
Jun 18, 2020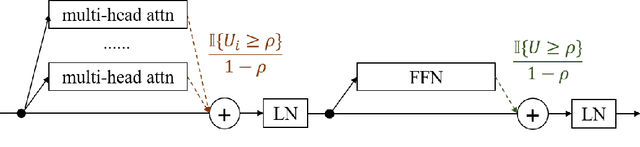
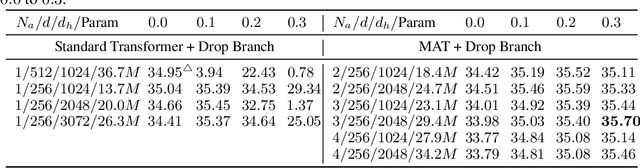
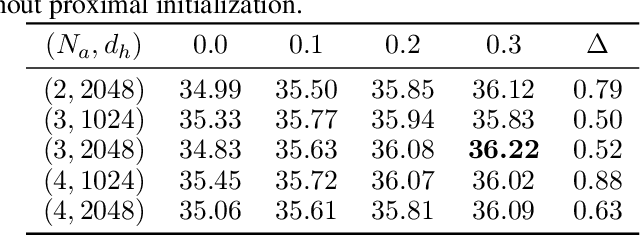
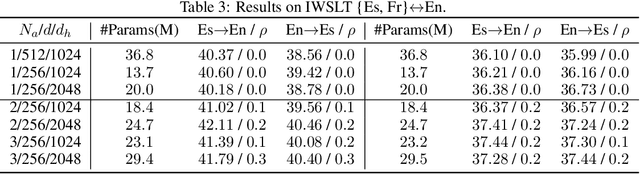
While the multi-branch architecture is one of the key ingredients to the success of computer vision tasks, it has not been well investigated in natural language processing, especially sequence learning tasks. In this work, we propose a simple yet effective variant of Transformer called multi-branch attentive Transformer (briefly, MAT), where the attention layer is the average of multiple branches and each branch is an independent multi-head attention layer. We leverage two training techniques to regularize the training: drop-branch, which randomly drops individual branches during training, and proximal initialization, which uses a pre-trained Transformer model to initialize multiple branches. Experiments on machine translation, code generation and natural language understanding demonstrate that such a simple variant of Transformer brings significant improvements. Our code is available at \url{https://github.com/HA-Transformer}.
MC-BERT: Efficient Language Pre-Training via a Meta Controller
Jun 16, 2020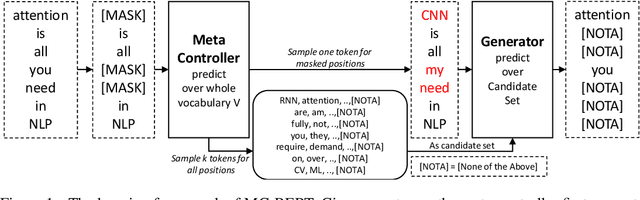

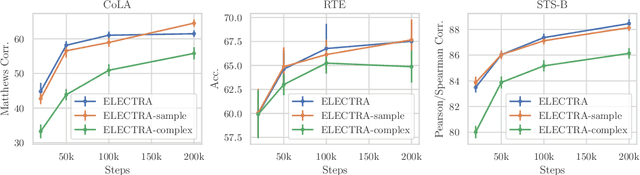

Pre-trained contextual representations (e.g., BERT) have become the foundation to achieve state-of-the-art results on many NLP tasks. However, large-scale pre-training is computationally expensive. ELECTRA, an early attempt to accelerate pre-training, trains a discriminative model that predicts whether each input token was replaced by a generator. Our studies reveal that ELECTRA's success is mainly due to its reduced complexity of the pre-training task: the binary classification (replaced token detection) is more efficient to learn than the generation task (masked language modeling). However, such a simplified task is less semantically informative. To achieve better efficiency and effectiveness, we propose a novel meta-learning framework, MC-BERT. The pre-training task is a multi-choice cloze test with a reject option, where a meta controller network provides training input and candidates. Results over GLUE natural language understanding benchmark demonstrate that our proposed method is both efficient and effective: it outperforms baselines on GLUE semantic tasks given the same computational budget.
UWSpeech: Speech to Speech Translation for Unwritten Languages
Jun 14, 2020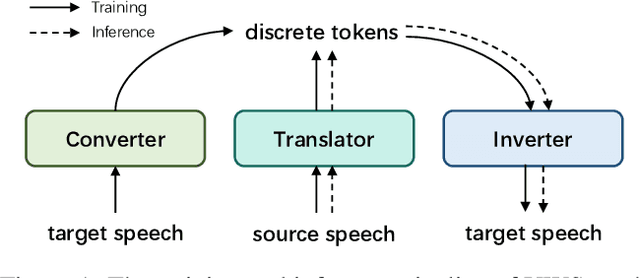
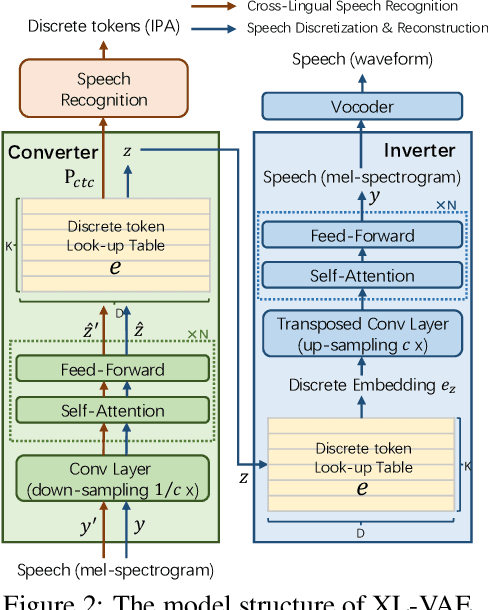


Existing speech to speech translation systems heavily rely on the text of target language: they usually translate source language either to target text and then synthesize target speech from text, or directly to target speech with target text for auxiliary training. However, those methods cannot be applied to unwritten target languages, which have no written text or phoneme available. In this paper, we develop a translation system for unwritten languages, named as UWSpeech, which converts target unwritten speech into discrete tokens with a converter, and then translates source-language speech into target discrete tokens with a translator, and finally synthesizes target speech from target discrete tokens with an inverter. We propose a method called XL-VAE, which enhances vector quantized variational autoencoder (VQ-VAE) with cross-lingual (XL) speech recognition, to train the converter and inverter of UWSpeech jointly. Experiments on Fisher Spanish-English conversation translation dataset show that UWSpeech outperforms direct translation and VQ-VAE baseline by about 16 and 10 BLEU points respectively, which demonstrate the advantages and potentials of UWSpeech.
Dual Learning: Theoretical Study and an Algorithmic Extension
May 17, 2020
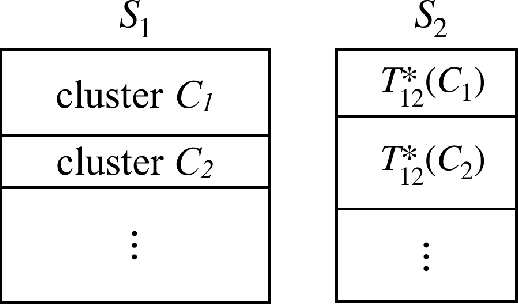
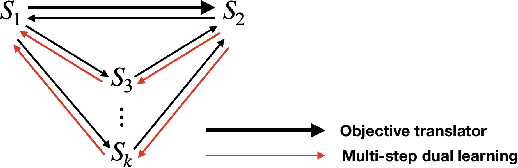
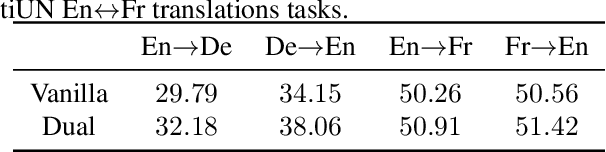
Dual learning has been successfully applied in many machine learning applications including machine translation, image-to-image transformation, etc. The high-level idea of dual learning is very intuitive: if we map an $x$ from one domain to another and then map it back, we should recover the original $x$. Although its effectiveness has been empirically verified, theoretical understanding of dual learning is still very limited. In this paper, we aim at understanding why and when dual learning works. Based on our theoretical analysis, we further extend dual learning by introducing more related mappings and propose multi-step dual learning, in which we leverage feedback signals from additional domains to improve the qualities of the mappings. We prove that multi-step dual learn-ing can boost the performance of standard dual learning under mild conditions. Experiments on WMT 14 English$\leftrightarrow$German and MultiUNEnglish$\leftrightarrow$French translations verify our theoretical findings on dual learning, and the results on the translations among English, French, and Spanish of MultiUN demonstrate the effectiveness of multi-step dual learning.
Invertible Image Rescaling
May 12, 2020
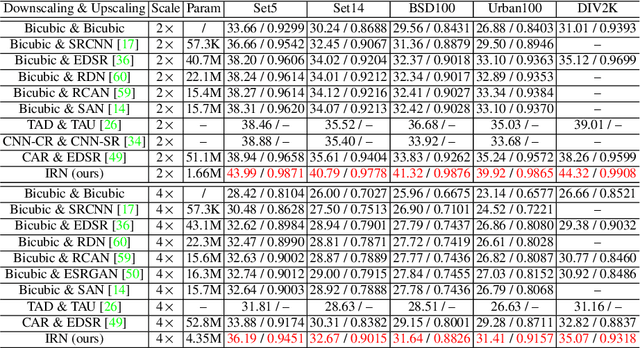
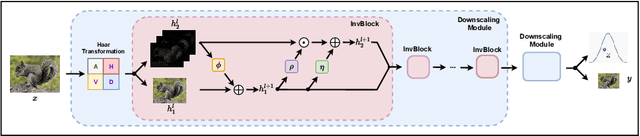
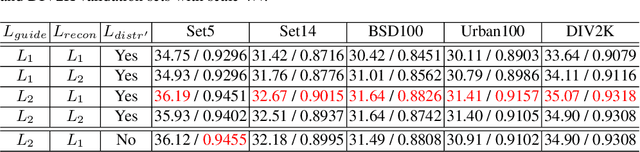
High-resolution digital images are usually downscaled to fit various display screens or save the cost of storage and bandwidth, meanwhile the post-upscaling is adpoted to recover the original resolutions or the details in the zoom-in images. However, typical image downscaling is a non-injective mapping due to the loss of high-frequency information, which leads to the ill-posed problem of the inverse upscaling procedure and poses great challenges for recovering details from the downscaled low-resolution images. Simply upscaling with image super-resolution methods results in unsatisfactory recovering performance. In this work, we propose to solve this problem by modeling the downscaling and upscaling processes from a new perspective, i.e. an invertible bijective transformation, which can largely mitigate the ill-posed nature of image upscaling. We develop an Invertible Rescaling Net (IRN) with deliberately designed framework and objectives to produce visually-pleasing low-resolution images and meanwhile capture the distribution of the lost information using a latent variable following a specified distribution in the downscaling process. In this way, upscaling is made tractable by inversely passing a randomly-drawn latent variable with the low-resolution image through the network. Experimental results demonstrate the significant improvement of our model over existing methods in terms of both quantitative and qualitative evaluations of image upscaling reconstruction from downscaled images.
A Study of Non-autoregressive Model for Sequence Generation
May 11, 2020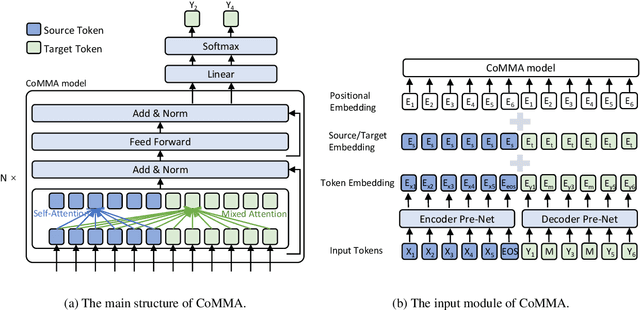

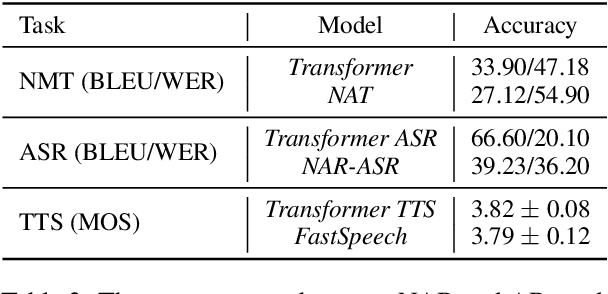
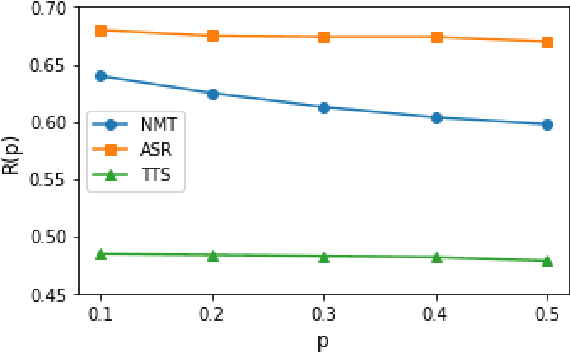
Non-autoregressive (NAR) models generate all the tokens of a sequence in parallel, resulting in faster generation speed compared to their autoregressive (AR) counterparts but at the cost of lower accuracy. Different techniques including knowledge distillation and source-target alignment have been proposed to bridge the gap between AR and NAR models in various tasks such as neural machine translation (NMT), automatic speech recognition (ASR), and text to speech (TTS). With the help of those techniques, NAR models can catch up with the accuracy of AR models in some tasks but not in some others. In this work, we conduct a study to understand the difficulty of NAR sequence generation and try to answer: (1) Why NAR models can catch up with AR models in some tasks but not all? (2) Why techniques like knowledge distillation and source-target alignment can help NAR models. Since the main difference between AR and NAR models is that NAR models do not use dependency among target tokens while AR models do, intuitively the difficulty of NAR sequence generation heavily depends on the strongness of dependency among target tokens. To quantify such dependency, we propose an analysis model called CoMMA to characterize the difficulty of different NAR sequence generation tasks. We have several interesting findings: 1) Among the NMT, ASR and TTS tasks, ASR has the most target-token dependency while TTS has the least. 2) Knowledge distillation reduces the target-token dependency in target sequence and thus improves the accuracy of NAR models. 3) Source-target alignment constraint encourages dependency of a target token on source tokens and thus eases the training of NAR models.
SEEK: Segmented Embedding of Knowledge Graphs
May 02, 2020
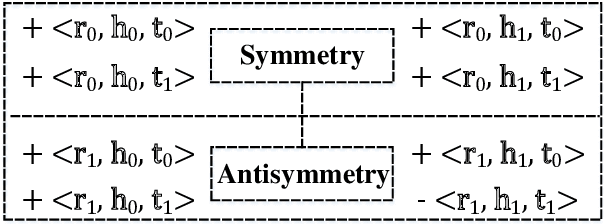
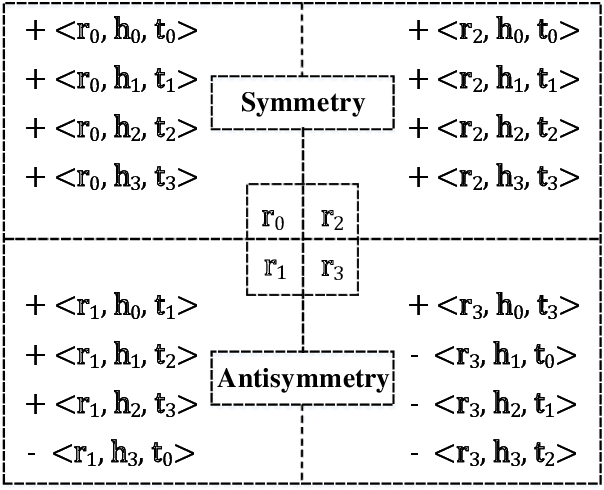
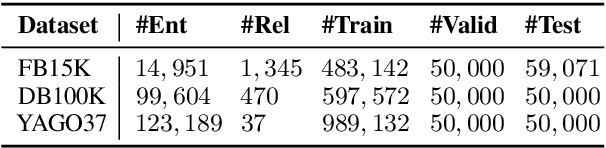
In recent years, knowledge graph embedding becomes a pretty hot research topic of artificial intelligence and plays increasingly vital roles in various downstream applications, such as recommendation and question answering. However, existing methods for knowledge graph embedding can not make a proper trade-off between the model complexity and the model expressiveness, which makes them still far from satisfactory. To mitigate this problem, we propose a lightweight modeling framework that can achieve highly competitive relational expressiveness without increasing the model complexity. Our framework focuses on the design of scoring functions and highlights two critical characteristics: 1) facilitating sufficient feature interactions; 2) preserving both symmetry and antisymmetry properties of relations. It is noteworthy that owing to the general and elegant design of scoring functions, our framework can incorporate many famous existing methods as special cases. Moreover, extensive experiments on public benchmarks demonstrate the efficiency and effectiveness of our framework. Source codes and data can be found at \url{https://github.com/Wentao-Xu/SEEK}.