 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseC-AFM: a deep learning method for fast and accurate characterization of MoS$_2$ with C-AFM
Jul 17, 2025The increasing use of two-dimensional (2D) materials in nanoelectronics demands robust metrology techniques for electrical characterization, especially for large-scale production. While atomic force microscopy (AFM) techniques like conductive AFM (C-AFM) offer high accuracy, they suffer from slow data acquisition speeds due to the raster scanning process. To address this, we introduce SparseC-AFM, a deep learning model that rapidly and accurately reconstructs conductivity maps of 2D materials like MoS$_2$ from sparse C-AFM scans. Our approach is robust across various scanning modes, substrates, and experimental conditions. We report a comparison between (a) classic flow implementation, where a high pixel density C-AFM image (e.g., 15 minutes to collect) is manually parsed to extract relevant material parameters, and (b) our SparseC-AFM method, which achieves the same operation using data that requires substantially less acquisition time (e.g., under 5 minutes). SparseC-AFM enables efficient extraction of critical material parameters in MoS$_2$, including film coverage, defect density, and identification of crystalline island boundaries, edges, and cracks. We achieve over 11x reduction in acquisition time compared to manual extraction from a full-resolution C-AFM image. Moreover, we demonstrate that our model-predicted samples exhibit remarkably similar electrical properties to full-resolution data gathered using classic-flow scanning. This work represents a significant step toward translating AI-assisted 2D material characterization from laboratory research to industrial fabrication. Code and model weights are available at github.com/UNITES-Lab/sparse-cafm.
Model Editing as a Double-Edged Sword: Steering Agent Ethical Behavior Toward Beneficence or Harm
Jun 25, 2025



Agents based on Large Language Models (LLMs) have demonstrated strong capabilities across a wide range of tasks. However, deploying LLM-based agents in high-stakes domains comes with significant safety and ethical risks. Unethical behavior by these agents can directly result in serious real-world consequences, including physical harm and financial loss. To efficiently steer the ethical behavior of agents, we frame agent behavior steering as a model editing task, which we term Behavior Editing. Model editing is an emerging area of research that enables precise and efficient modifications to LLMs while preserving their overall capabilities. To systematically study and evaluate this approach, we introduce BehaviorBench, a multi-tier benchmark grounded in psychological moral theories. This benchmark supports both the evaluation and editing of agent behaviors across a variety of scenarios, with each tier introducing more complex and ambiguous scenarios. We first demonstrate that Behavior Editing can dynamically steer agents toward the target behavior within specific scenarios. Moreover, Behavior Editing enables not only scenario-specific local adjustments but also more extensive shifts in an agent's global moral alignment. We demonstrate that Behavior Editing can be used to promote ethical and benevolent behavior or, conversely, to induce harmful or malicious behavior. Through comprehensive evaluations on agents based on frontier LLMs, BehaviorBench shows the effectiveness of Behavior Editing across different models and scenarios. Our findings offer key insights into a new paradigm for steering agent behavior, highlighting both the promise and perils of Behavior Editing.
EQA-RM: A Generative Embodied Reward Model with Test-time Scaling
Jun 12, 2025Reward Models (RMs), vital for large model alignment, are underexplored for complex embodied tasks like Embodied Question Answering (EQA) where nuanced evaluation of agents' spatial, temporal, and logical understanding is critical yet not considered by generic approaches. We introduce EQA-RM, a novel generative multimodal reward model specifically architected for EQA, trained via our innovative Contrastive Group Relative Policy Optimization (C-GRPO) strategy to learn fine-grained behavioral distinctions. The generative nature of EQA-RM provides interpretable, structured reward feedback (beyond simple scalars), uniquely enabling test-time scaling to dynamically adjust evaluation granularity, from concise scores to detailed critiques of reasoning and grounding, at inference without retraining. Concurrently, we introduce EQARewardBench, a new benchmark built on OpenEQA for standardized EQA reward model assessment. Demonstrating high sample efficiency, EQA-RM (fine-tuning Qwen2-VL-2B-Instruct) achieves 61.9\% accuracy on EQA-RM-Bench with only 700 samples, outperforming strong proprietary baselines, including Gemini-2.5-Flash, GPT-4o, Claude-3.5-Haiku, and open-sourced state-of-the-art models such as RoVRM and VisualPRM. The code and dataset can be found here https://github.com/UNITES-Lab/EQA-RM.
IndustryEQA: Pushing the Frontiers of Embodied Question Answering in Industrial Scenarios
May 27, 2025Existing Embodied Question Answering (EQA) benchmarks primarily focus on household environments, often overlooking safety-critical aspects and reasoning processes pertinent to industrial settings. This drawback limits the evaluation of agent readiness for real-world industrial applications. To bridge this, we introduce IndustryEQA, the first benchmark dedicated to evaluating embodied agent capabilities within safety-critical warehouse scenarios. Built upon the NVIDIA Isaac Sim platform, IndustryEQA provides high-fidelity episodic memory videos featuring diverse industrial assets, dynamic human agents, and carefully designed hazardous situations inspired by real-world safety guidelines. The benchmark includes rich annotations covering six categories: equipment safety, human safety, object recognition, attribute recognition, temporal understanding, and spatial understanding. Besides, it also provides extra reasoning evaluation based on these categories. Specifically, it comprises 971 question-answer pairs generated from small warehouse and 373 pairs from large ones, incorporating scenarios with and without human. We further propose a comprehensive evaluation framework, including various baseline models, to assess their general perception and reasoning abilities in industrial environments. IndustryEQA aims to steer EQA research towards developing more robust, safety-aware, and practically applicable embodied agents for complex industrial environments. Benchmark and codes are available.
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
May 26, 2025The rapid advancement of Large Multimodal Models (LMMs) for 2D images and videos has motivated extending these models to understand 3D scenes, aiming for human-like visual-spatial intelligence. Nevertheless, achieving deep spatial understanding comparable to human capabilities poses significant challenges in model encoding and data acquisition. Existing methods frequently depend on external depth sensors for geometry capture or utilize off-the-shelf algorithms for pre-constructing 3D maps, thereby limiting their scalability, especially with prevalent monocular video inputs and for time-sensitive applications. In this work, we introduce VLM-3R, a unified framework for Vision-Language Models (VLMs) that incorporates 3D Reconstructive instruction tuning. VLM-3R processes monocular video frames by employing a geometry encoder to derive implicit 3D tokens that represent spatial understanding. Leveraging our Spatial-Visual-View Fusion and over 200K curated 3D reconstructive instruction tuning question-answer (QA) pairs, VLM-3R effectively aligns real-world spatial context with language instructions. This enables monocular 3D spatial assistance and embodied reasoning. To facilitate the evaluation of temporal reasoning, we introduce the Vision-Spatial-Temporal Intelligence benchmark, featuring over 138.6K QA pairs across five distinct tasks focused on evolving spatial relationships. Extensive experiments demonstrate that our model, VLM-3R, not only facilitates robust visual-spatial reasoning but also enables the understanding of temporal 3D context changes, excelling in both accuracy and scalability.
DOGe: Defensive Output Generation for LLM Protection Against Knowledge Distillation
May 26, 2025
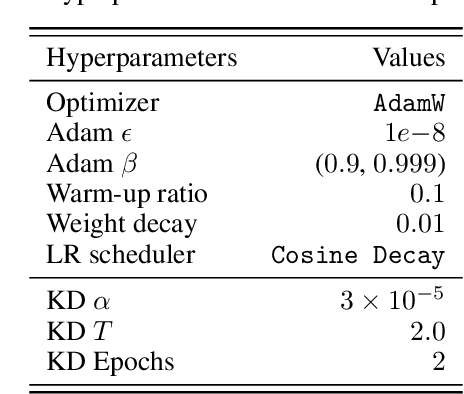
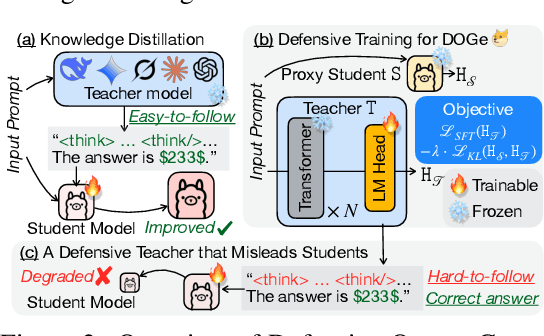

Large Language Models (LLMs) represent substantial intellectual and economic investments, yet their effectiveness can inadvertently facilitate model imitation via knowledge distillation (KD).In practical scenarios, competitors can distill proprietary LLM capabilities by simply observing publicly accessible outputs, akin to reverse-engineering a complex performance by observation alone. Existing protective methods like watermarking only identify imitation post-hoc, while other defenses assume the student model mimics the teacher's internal logits, rendering them ineffective against distillation purely from observed output text. This paper confronts the challenge of actively protecting LLMs within the realistic constraints of API-based access. We introduce an effective and efficient Defensive Output Generation (DOGe) strategy that subtly modifies the output behavior of an LLM. Its outputs remain accurate and useful for legitimate users, yet are designed to be misleading for distillation, significantly undermining imitation attempts. We achieve this by fine-tuning only the final linear layer of the teacher LLM with an adversarial loss. This targeted training approach anticipates and disrupts distillation attempts during inference time. Our experiments show that, while preserving or even improving the original performance of the teacher model, student models distilled from the defensively generated teacher outputs demonstrate catastrophically reduced performance, demonstrating our method's effectiveness as a practical safeguard against KD-based model imitation.
I2MoE: Interpretable Multimodal Interaction-aware Mixture-of-Experts
May 25, 2025



Modality fusion is a cornerstone of multimodal learning, enabling information integration from diverse data sources. However, vanilla fusion methods are limited by (1) inability to account for heterogeneous interactions between modalities and (2) lack of interpretability in uncovering the multimodal interactions inherent in the data. To this end, we propose I2MoE (Interpretable Multimodal Interaction-aware Mixture of Experts), an end-to-end MoE framework designed to enhance modality fusion by explicitly modeling diverse multimodal interactions, as well as providing interpretation on a local and global level. First, I2MoE utilizes different interaction experts with weakly supervised interaction losses to learn multimodal interactions in a data-driven way. Second, I2MoE deploys a reweighting model that assigns importance scores for the output of each interaction expert, which offers sample-level and dataset-level interpretation. Extensive evaluation of medical and general multimodal datasets shows that I2MoE is flexible enough to be combined with different fusion techniques, consistently improves task performance, and provides interpretation across various real-world scenarios. Code is available at https://github.com/Raina-Xin/I2MoE.
The Quest for Efficient Reasoning: A Data-Centric Benchmark to CoT Distillation
May 24, 2025Data-centric distillation, including data augmentation, selection, and mixing, offers a promising path to creating smaller, more efficient student Large Language Models (LLMs) that retain strong reasoning abilities. However, there still lacks a comprehensive benchmark to systematically assess the effect of each distillation approach. This paper introduces DC-CoT, the first data-centric benchmark that investigates data manipulation in chain-of-thought (CoT) distillation from method, model and data perspectives. Utilizing various teacher models (e.g., o4-mini, Gemini-Pro, Claude-3.5) and student architectures (e.g., 3B, 7B parameters), we rigorously evaluate the impact of these data manipulations on student model performance across multiple reasoning datasets, with a focus on in-distribution (IID) and out-of-distribution (OOD) generalization, and cross-domain transfer. Our findings aim to provide actionable insights and establish best practices for optimizing CoT distillation through data-centric techniques, ultimately facilitating the development of more accessible and capable reasoning models. The dataset can be found at https://huggingface.co/datasets/rana-shahroz/DC-COT, while our code is shared in https://anonymous.4open.science/r/DC-COT-FF4C/.
Occult: Optimizing Collaborative Communication across Experts for Accelerated Parallel MoE Training and Inference
May 19, 2025Mixture-of-experts (MoE) architectures could achieve impressive computational efficiency with expert parallelism, which relies heavily on all-to-all communication across devices. Unfortunately, such communication overhead typically constitutes a significant portion of the total runtime, hampering the scalability of distributed training and inference for modern MoE models (consuming over $40\%$ runtime in large-scale training). In this paper, we first define collaborative communication to illustrate this intrinsic limitation, and then propose system- and algorithm-level innovations to reduce communication costs. Specifically, given a pair of experts co-activated by one token, we call them "collaborated", which comprises $2$ cases as intra- and inter-collaboration, depending on whether they are kept on the same device. Our pilot investigations reveal that augmenting the proportion of intra-collaboration can accelerate expert parallelism at scale. It motivates us to strategically optimize collaborative communication for accelerated MoE training and inference, dubbed Occult. Our designs are capable of either delivering exact results with reduced communication cost or controllably minimizing the cost with collaboration pruning, materialized by modified fine-tuning. Comprehensive experiments on various MoE-LLMs demonstrate that Occult can be faster than popular state-of-the-art inference or training frameworks (more than $1.5\times$ speed up across multiple tasks and models) with comparable or superior quality compared to the standard fine-tuning. Code is available at $\href{https://github.com/UNITES-Lab/Occult}{https://github.com/UNITES-Lab/Occult}$.
DD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.