 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOGe: Defensive Output Generation for LLM Protection Against Knowledge Distillation
Paper and Code

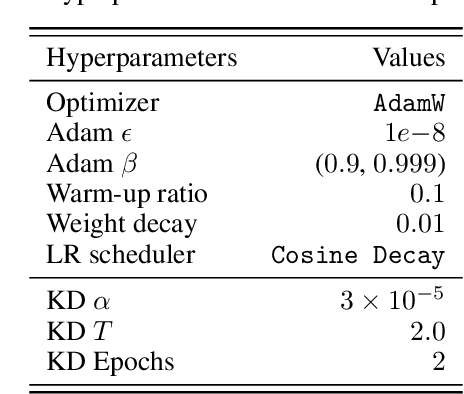
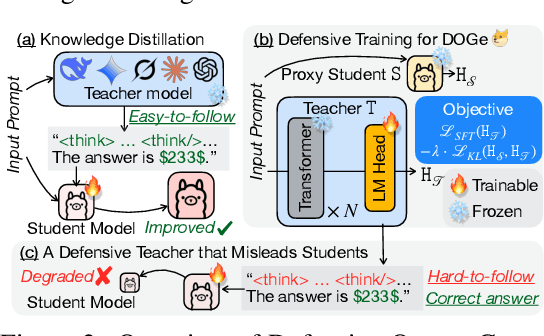

Large Language Models (LLMs) represent substantial intellectual and economic investments, yet their effectiveness can inadvertently facilitate model imitation via knowledge distillation (KD).In practical scenarios, competitors can distill proprietary LLM capabilities by simply observing publicly accessible outputs, akin to reverse-engineering a complex performance by observation alone. Existing protective methods like watermarking only identify imitation post-hoc, while other defenses assume the student model mimics the teacher's internal logits, rendering them ineffective against distillation purely from observed output text. This paper confronts the challenge of actively protecting LLMs within the realistic constraints of API-based access. We introduce an effective and efficient Defensive Output Generation (DOGe) strategy that subtly modifies the output behavior of an LLM. Its outputs remain accurate and useful for legitimate users, yet are designed to be misleading for distillation, significantly undermining imitation attempts. We achieve this by fine-tuning only the final linear layer of the teacher LLM with an adversarial loss. This targeted training approach anticipates and disrupts distillation attempts during inference time. Our experiments show that, while preserving or even improving the original performance of the teacher model, student models distilled from the defensively generated teacher outputs demonstrate catastrophically reduced performance, demonstrating our method's effectiveness as a practical safeguard against KD-based model imitation.