 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottom-up Higher-Resolution Networks for Multi-Person Pose Estimation
Aug 27, 2019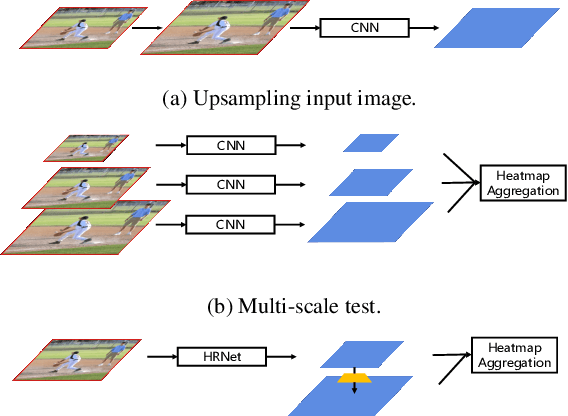
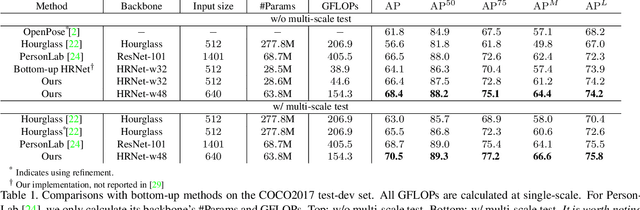
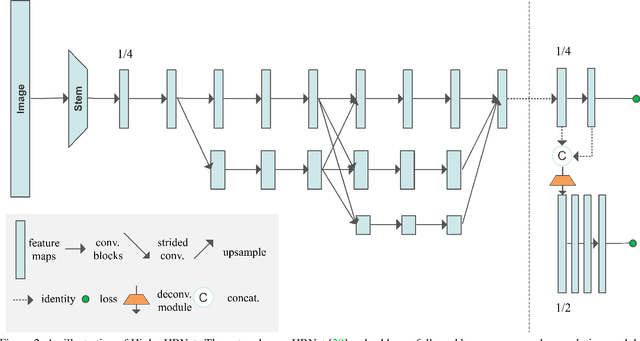
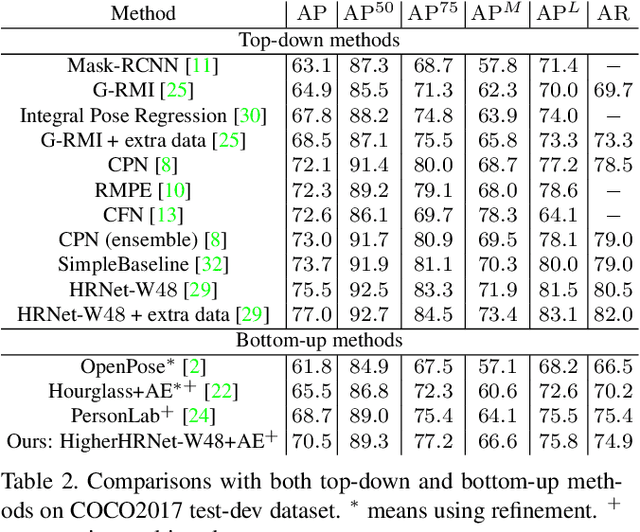
In this paper, we are interested in bottom-up multi-person human pose estimation. A typical bottom-up pipeline consists of two main steps: heatmap prediction and keypoint grouping. We mainly focus on the first step for improving heatmap prediction accuracy. We propose Higher-Resolution Network (HigherHRNet), which is a simple extension of the High-Resolution Network (HRNet). HigherHRNet generates higher-resolution feature maps by deconvolving the high-resolution feature maps outputted by HRNet, which are spatially more accurate for small and medium persons. Then, we build high-quality multi-level features and perform multi-scale pose prediction. The extra computation overhead is marginal and negligible in comparison to existing bottom-up methods that rely on multi-scale image pyramids or large input image size to generate accurate pose heatmaps. HigherHRNet surpasses all existing bottom-up methods on the COCO dataset without using multi-scale test. The code and models will be released.
Revisiting Pre-training: An Efficient Training Method for Image Classification
Nov 23, 2018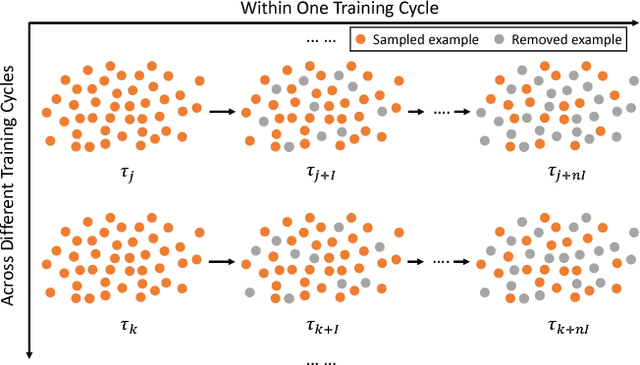

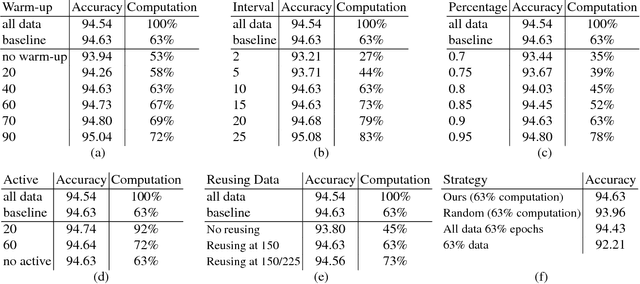

The training method of repetitively feeding all samples into a pre-defined network for image classification has been widely adopted by current state-of-the-art. In this work, we provide a new method, which can be leveraged to train classification networks in a more efficient way. Starting with a warm-up step, we propose to continually repeat a Drop-and-Pick (DaP) learning strategy. In particular, we drop those easy samples to encourage the network to focus on studying hard ones. Meanwhile, by picking up all samples periodically during training, we aim to recall the memory of the networks to prevent catastrophic forgetting of previously learned knowledge. Our DaP learning method can recover 99.88%, 99.60%, 99.83% top-1 accuracy on ImageNet for ResNet-50, DenseNet-121, and MobileNet-V1 but only requires 75% computation in training compared to those using the classic training schedule. Furthermore, our pre-trained models are equipped with strong knowledge transferability when used for downstream tasks, especially for hard cases. Extensive experiments on object detection, instance segmentation and pose estimation can well demonstrate the effectiveness of our DaP training method.
Connecting Image Denoising and High-Level Vision Tasks via Deep Learning
Sep 06, 2018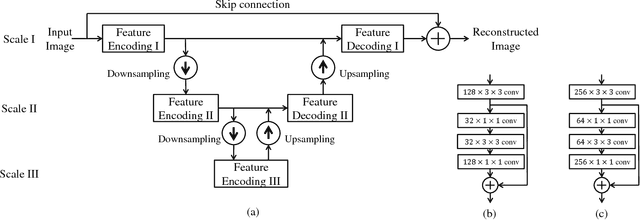
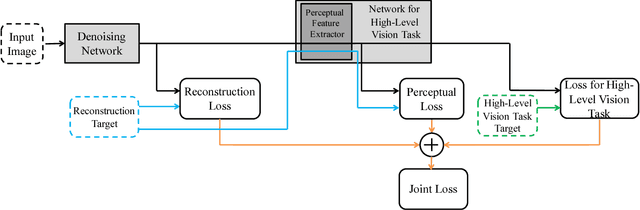

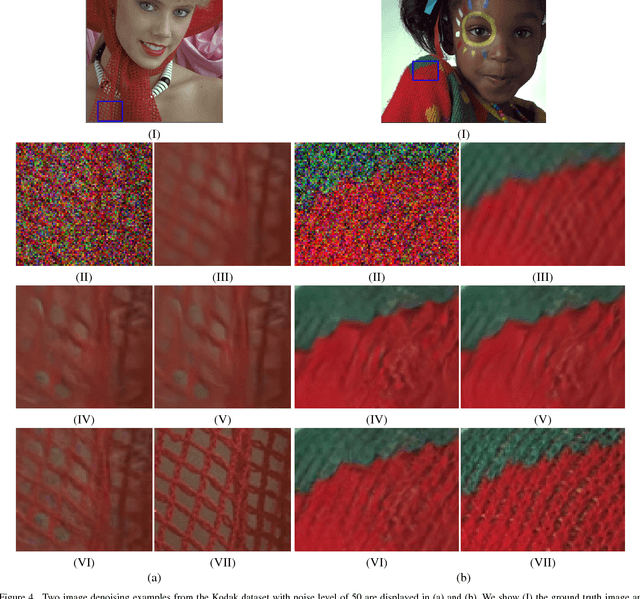
Image denoising and high-level vision tasks are usually handled independently in the conventional practice of computer vision, and their connection is fragile. In this paper, we cope with the two jointly and explore the mutual influence between them with the focus on two questions, namely (1) how image denoising can help improving high-level vision tasks, and (2) how the semantic information from high-level vision tasks can be used to guide image denoising. First for image denoising we propose a convolutional neural network in which convolutions are conducted in various spatial resolutions via downsampling and upsampling operations in order to fuse and exploit contextual information on different scales. Second we propose a deep neural network solution that cascades two modules for image denoising and various high-level tasks, respectively, and use the joint loss for updating only the denoising network via back-propagation. We experimentally show that on one hand, the proposed denoiser has the generality to overcome the performance degradation of different high-level vision tasks. On the other hand, with the guidance of high-level vision information, the denoising network produces more visually appealing results. Extensive experiments demonstrate the benefit of exploiting image semantics simultaneously for image denoising and high-level vision tasks via deep learning. The code is available online: https://github.com/Ding-Liu/DeepDenoising
Free-Form Image Inpainting with Gated Convolution
Jun 10, 2018

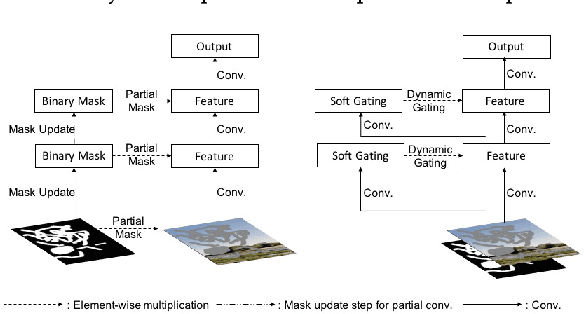

We present a novel deep learning based image inpainting system to complete images with free-form masks and inputs. The system is based on gated convolutions learned from millions of images without additional labelling efforts. The proposed gated convolution solves the issue of vanilla convolution that treats all input pixels as valid ones, generalizes partial convolution by providing a learnable dynamic feature selection mechanism for each channel at each spatial location across all layers. Moreover, as free-form masks may appear anywhere in images with any shapes, global and local GANs designed for a single rectangular mask are not suitable. To this end, we also present a novel GAN loss, named SN-PatchGAN, by applying spectral-normalized discriminators on dense image patches. It is simple in formulation, fast and stable in training. Results on automatic image inpainting and user-guided extension demonstrate that our system generates higher-quality and more flexible results than previous methods. We show that our system helps users quickly remove distracting objects, modify image layouts, clear watermarks, edit faces and interactively create novel objects in images. Furthermore, visualization of learned feature representations reveals the effectiveness of gated convolution and provides an interpretation of how the proposed neural network fills in missing regions. More high-resolution results and video materials are available at http://jiahuiyu.com/deepfill2
Non-Local Recurrent Network for Image Restoration
Jun 07, 2018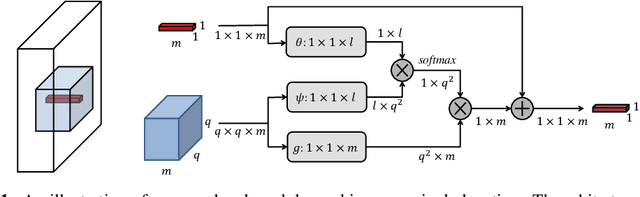
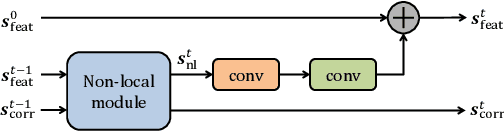
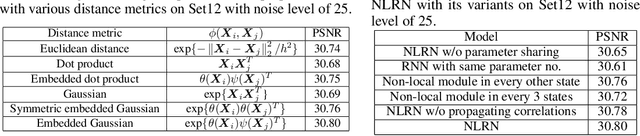
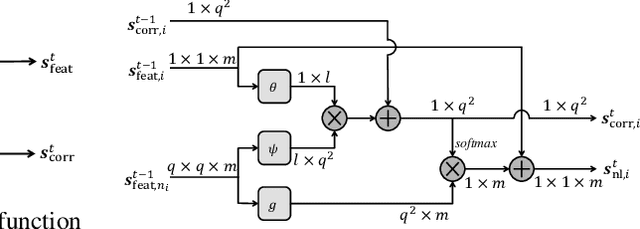
Many classic methods have shown non-local self-similarity in natural images to be an effective prior for image restoration. However, it remains unclear and challenging to make use of this intrinsic property via deep networks. In this paper, we propose a non-local recurrent network (NLRN) as the first attempt to incorporate non-local operations into a recurrent neural network (RNN) for image restoration. The main contributions of this work are: (1) Unlike existing methods that measure self-similarity in an isolated manner, the proposed non-local module can be flexibly integrated into existing deep networks for end-to-end training to capture deep feature correlation between each location and its neighborhood. (2) We fully employ the RNN structure for its parameter efficiency and allow deep feature correlation to be propagated along adjacent recurrent states. This new design boosts robustness against inaccurate correlation estimation due to severely degraded images. (3) We show that it is essential to maintain a confined neighborhood for computing deep feature correlation given degraded images. This is in contrast to existing practice that deploys the whole image. Extensive experiments on both image denoising and super-resolution tasks are conducted. Thanks to the recurrent non-local operations and correlation propagation, the proposed NLRN achieves superior results to state-of-the-art methods with much fewer parameters.
Revisiting Dilated Convolution: A Simple Approach for Weakly- and Semi- Supervised Semantic Segmentation
May 28, 2018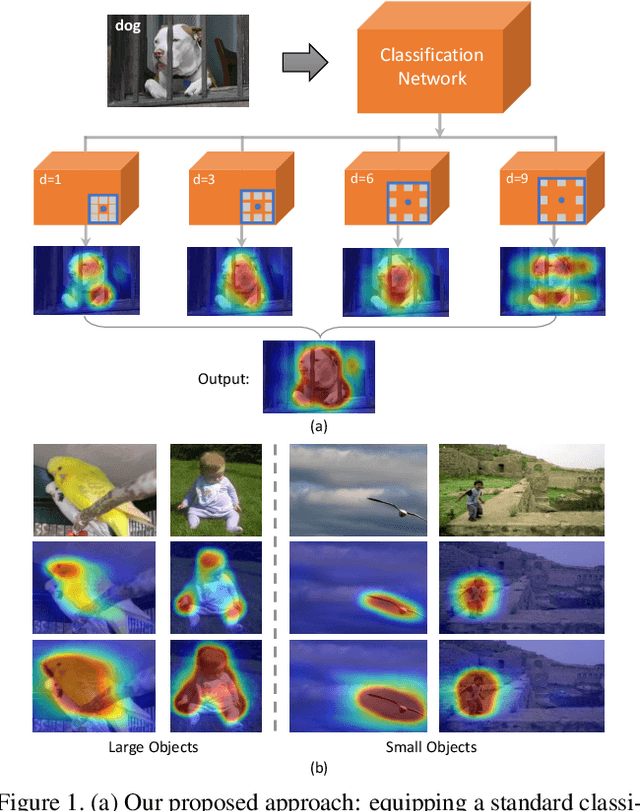
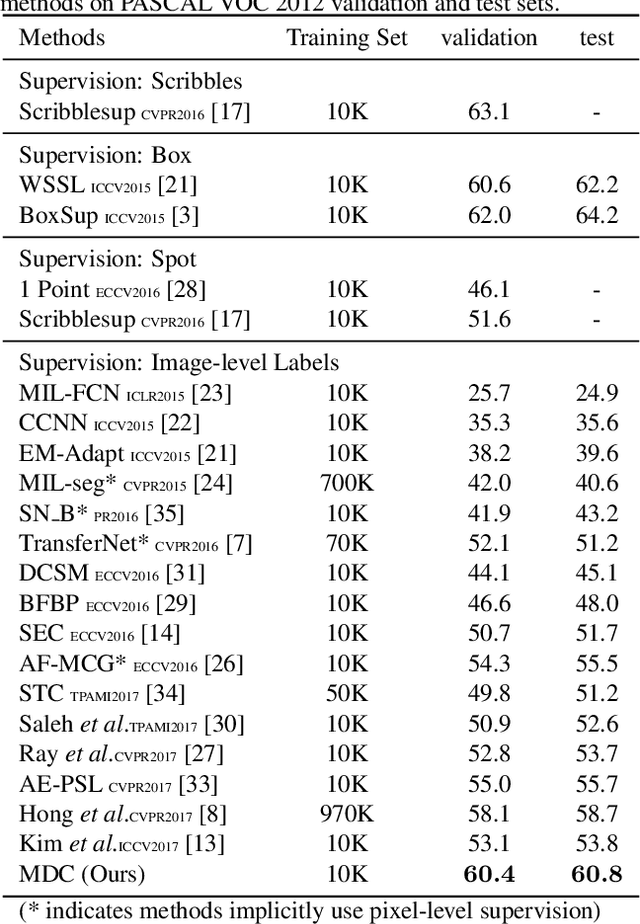


Despite the remarkable progress, weakly supervised segmentation approaches are still inferior to their fully supervised counterparts. We obverse the performance gap mainly comes from their limitation on learning to produce high-quality dense object localization maps from image-level supervision. To mitigate such a gap, we revisit the dilated convolution [1] and reveal how it can be utilized in a novel way to effectively overcome this critical limitation of weakly supervised segmentation approaches. Specifically, we find that varying dilation rates can effectively enlarge the receptive fields of convolutional kernels and more importantly transfer the surrounding discriminative information to non-discriminative object regions, promoting the emergence of these regions in the object localization maps. Then, we design a generic classification network equipped with convolutional blocks of different dilated rates. It can produce dense and reliable object localization maps and effectively benefit both weakly- and semi- supervised semantic segmentation. Despite the apparent simplicity, our proposed approach obtains superior performance over state-of-the-arts. In particular, it achieves 60.8% and 67.6% mIoU scores on Pascal VOC 2012 test set in weakly- (only image-level labels are available) and semi- (1,464 segmentation masks are available) supervised settings, which are the new state-of-the-arts.
Image Super-Resolution via Dual-State Recurrent Networks
May 07, 2018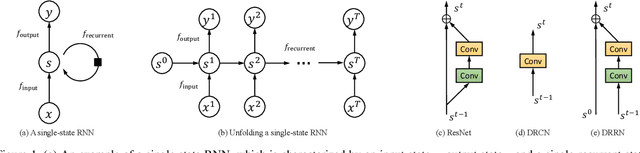
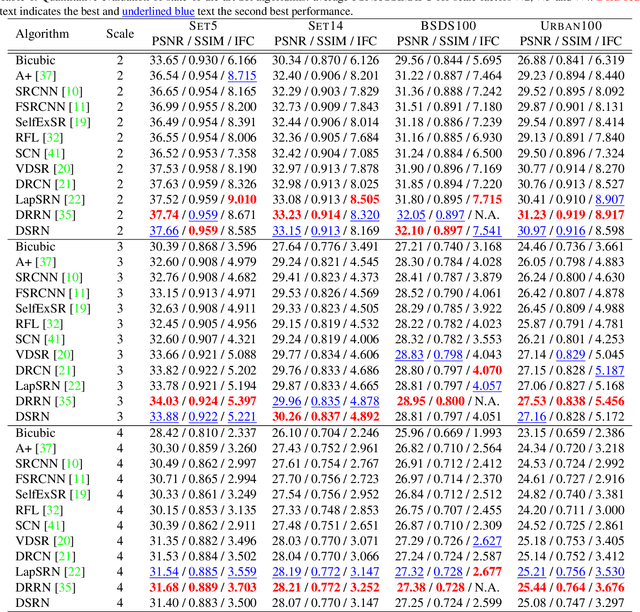
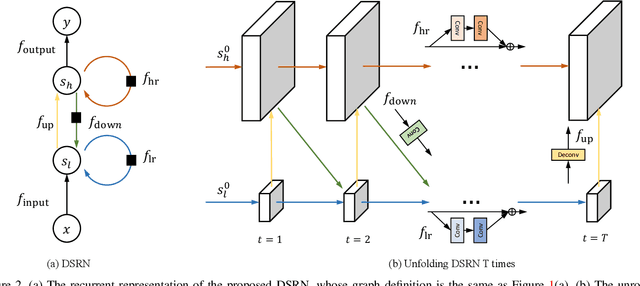
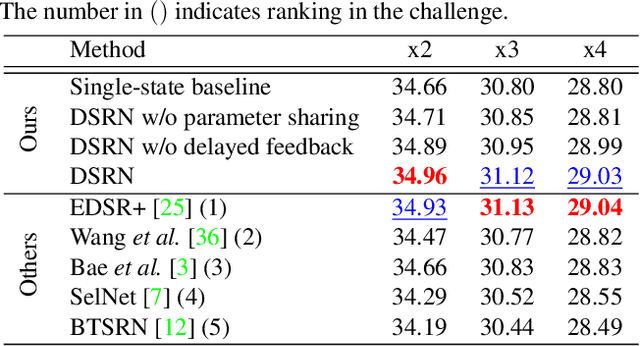
Advances in image super-resolution (SR) have recently benefited significantly from rapid developments in deep neural networks. Inspired by these recent discoveries, we note that many state-of-the-art deep SR architectures can be reformulated as a single-state recurrent neural network (RNN) with finite unfoldings. In this paper, we explore new structures for SR based on this compact RNN view, leading us to a dual-state design, the Dual-State Recurrent Network (DSRN). Compared to its single state counterparts that operate at a fixed spatial resolution, DSRN exploits both low-resolution (LR) and high-resolution (HR) signals jointly. Recurrent signals are exchanged between these states in both directions (both LR to HR and HR to LR) via delayed feedback. Extensive quantitative and qualitative evaluations on benchmark datasets and on a recent challenge demonstrate that the proposed DSRN performs favorably against state-of-the-art algorithms in terms of both memory consumption and predictive accuracy.
When Image Denoising Meets High-Level Vision Tasks: A Deep Learning Approach
Apr 16, 2018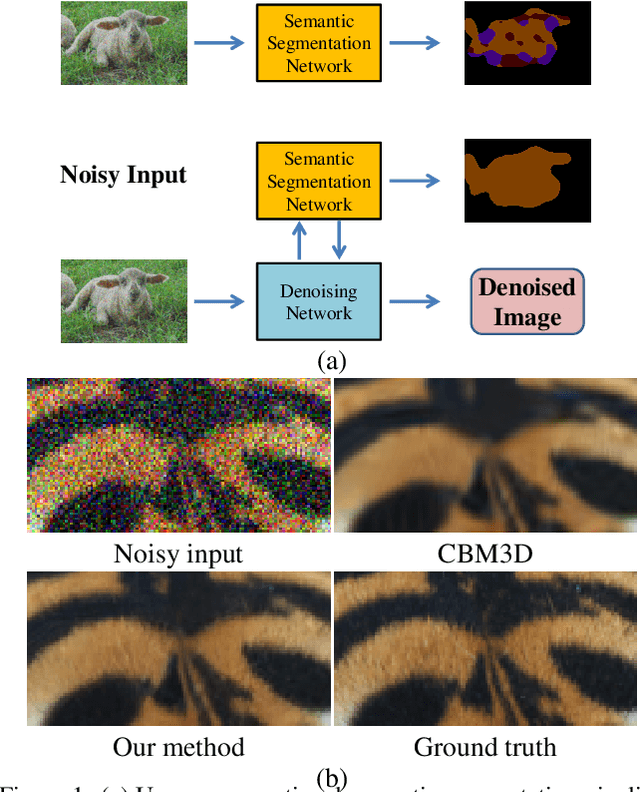
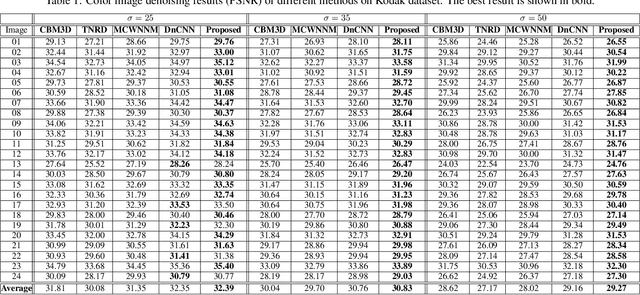
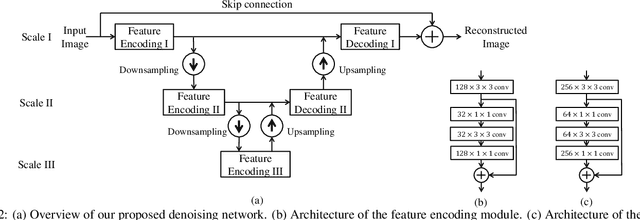
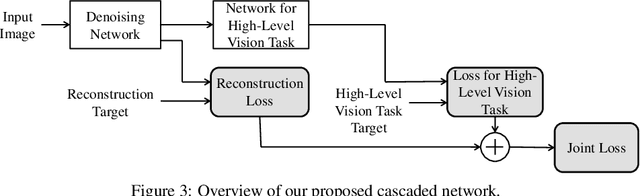
Conventionally, image denoising and high-level vision tasks are handled separately in computer vision. In this paper, we cope with the two jointly and explore the mutual influence between them. First we propose a convolutional neural network for image denoising which achieves the state-of-the-art performance. Second we propose a deep neural network solution that cascades two modules for image denoising and various high-level tasks, respectively, and use the joint loss for updating only the denoising network via back-propagation. We demonstrate that on one hand, the proposed denoiser has the generality to overcome the performance degradation of different high-level vision tasks. On the other hand, with the guidance of high-level vision information, the denoising network can generate more visually appealing results. To the best of our knowledge, this is the first work investigating the benefit of exploiting image semantics simultaneously for image denoising and high-level vision tasks via deep learning. The code is available online https://github.com/Ding-Liu/DeepDenoising.
Generative Image Inpainting with Contextual Attention
Mar 21, 2018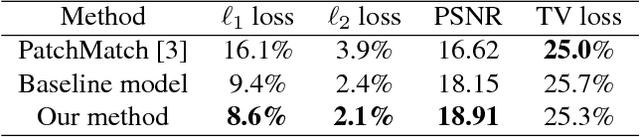

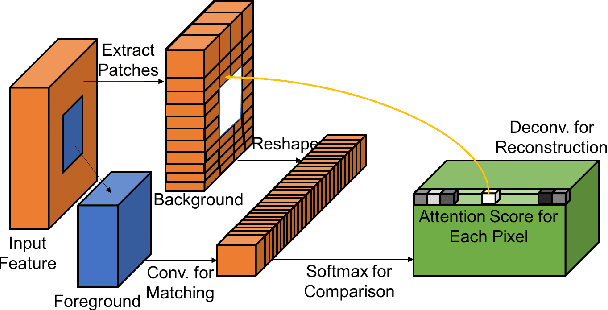
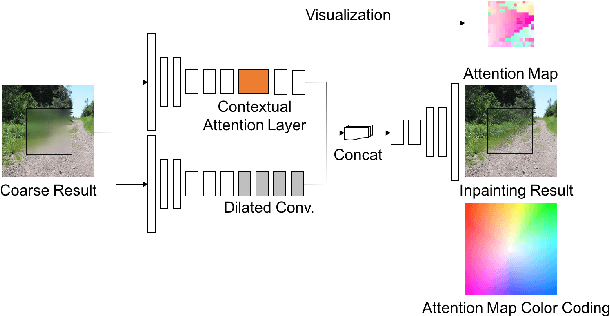
Recent deep learning based approaches have shown promising results for the challenging task of inpainting large missing regions in an image. These methods can generate visually plausible image structures and textures, but often create distorted structures or blurry textures inconsistent with surrounding areas. This is mainly due to ineffectiveness of convolutional neural networks in explicitly borrowing or copying information from distant spatial locations. On the other hand, traditional texture and patch synthesis approaches are particularly suitable when it needs to borrow textures from the surrounding regions. Motivated by these observations, we propose a new deep generative model-based approach which can not only synthesize novel image structures but also explicitly utilize surrounding image features as references during network training to make better predictions. The model is a feed-forward, fully convolutional neural network which can process images with multiple holes at arbitrary locations and with variable sizes during the test time. Experiments on multiple datasets including faces (CelebA, CelebA-HQ), textures (DTD) and natural images (ImageNet, Places2) demonstrate that our proposed approach generates higher-quality inpainting results than existing ones. Code, demo and models are available at: https://github.com/JiahuiYu/generative_inpainting.
Enhance Visual Recognition under Adverse Conditions via Deep Networks
Dec 20, 2017

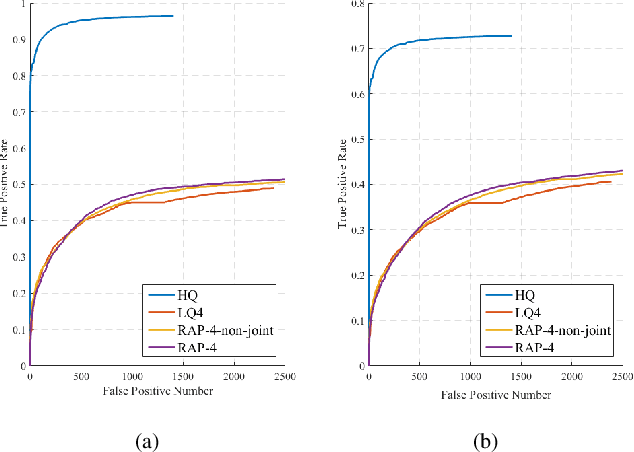

Visual recognition under adverse conditions is a very important and challenging problem of high practical value, due to the ubiquitous existence of quality distortions during image acquisition, transmission, or storage. While deep neural networks have been extensively exploited in the techniques of low-quality image restoration and high-quality image recognition tasks respectively, few studies have been done on the important problem of recognition from very low-quality images. This paper proposes a deep learning based framework for improving the performance of image and video recognition models under adverse conditions, using robust adverse pre-training or its aggressive variant. The robust adverse pre-training algorithms leverage the power of pre-training and generalizes conventional unsupervised pre-training and data augmentation methods. We further develop a transfer learning approach to cope with real-world datasets of unknown adverse conditions. The proposed framework is comprehensively evaluated on a number of image and video recognition benchmarks, and obtains significant performance improvements under various single or mixed adverse conditions. Our visualization and analysis further add to the explainability of results.