 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTete Xiao
Something-Else: Compositional Action Recognition with Spatial-Temporal Interaction Networks
Dec 20, 2019
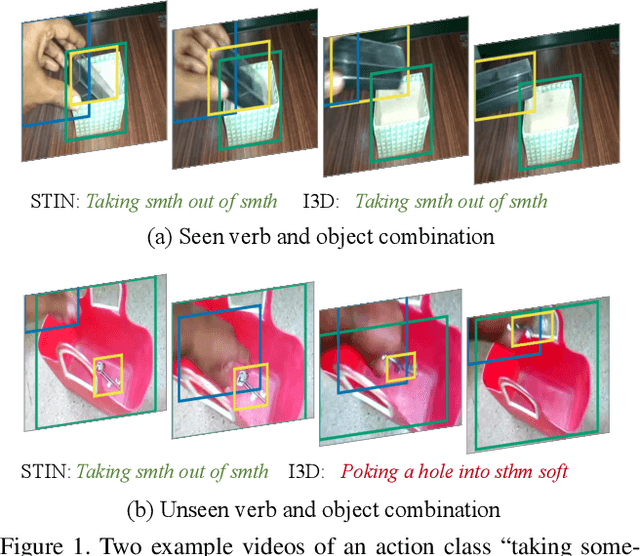
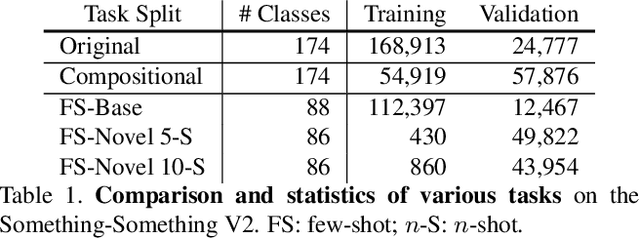
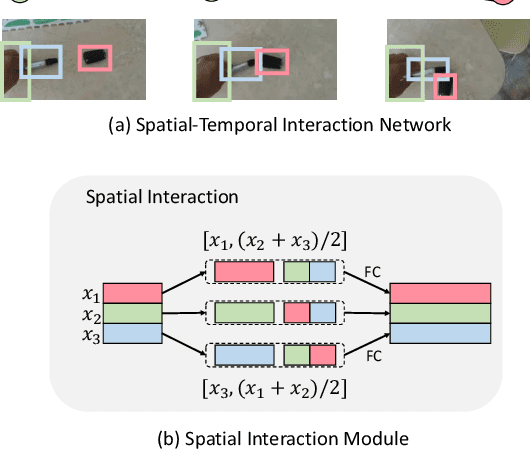
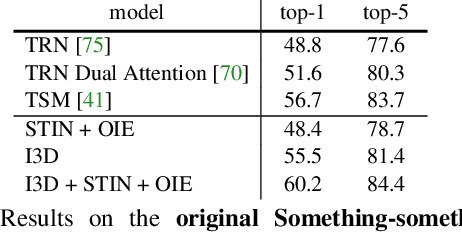
Human action is naturally compositional: humans can easily recognize and perform actions with objects that are different from those used in training demonstrations. In this paper, we study the compositionality of action by looking into the dynamics of subject-object interactions. We propose a novel model which can explicitly reason about the geometric relations between constituent objects and an agent performing an action. To train our model, we collect dense object box annotations on the Something-Something dataset. We propose a novel compositional action recognition task where the training combinations of verbs and nouns do not overlap with the test set. The novel aspects of our model are applicable to activities with prominent object interaction dynamics and to objects which can be tracked using state-of-the-art approaches; for activities without clearly defined spatial object-agent interactions, we rely on baseline scene-level spatio-temporal representations. We show the effectiveness of our approach not only on the proposed compositional action recognition task, but also in a few-shot compositional setting which requires the model to generalize across both object appearance and action category.
Reasoning About Human-Object Interactions Through Dual Attention Networks
Sep 10, 2019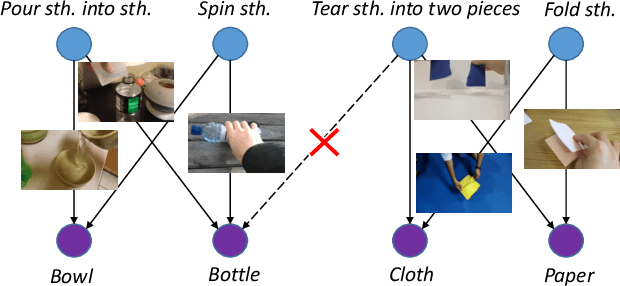

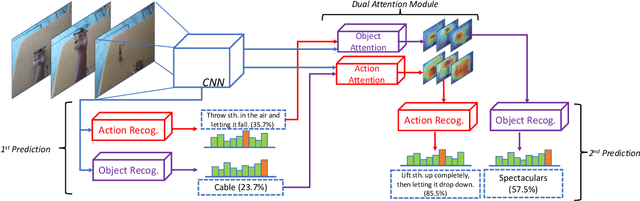
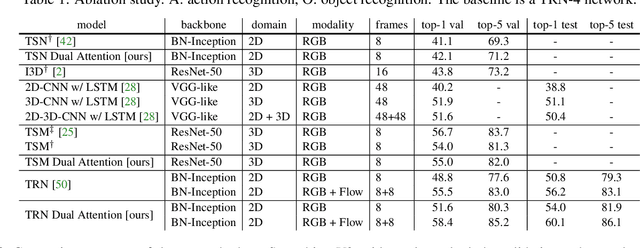
Objects are entities we act upon, where the functionality of an object is determined by how we interact with it. In this work we propose a Dual Attention Network model which reasons about human-object interactions. The dual-attentional framework weights the important features for objects and actions respectively. As a result, the recognition of objects and actions mutually benefit each other. The proposed model shows competitive classification performance on the human-object interaction dataset Something-Something. Besides, it can perform weak spatiotemporal localization and affordance segmentation, despite being trained only with video-level labels. The model not only finds when an action is happening and which object is being manipulated, but also identifies which part of the object is being interacted with. Project page: \url{https://dual-attention-network.github.io/}.
Semantic Understanding of Scenes through the ADE20K Dataset
Oct 16, 2018
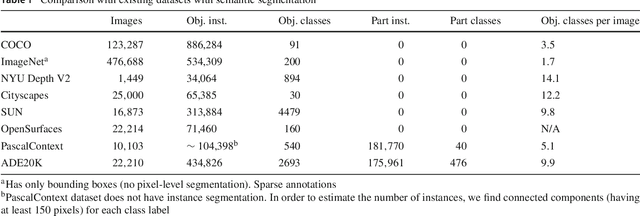

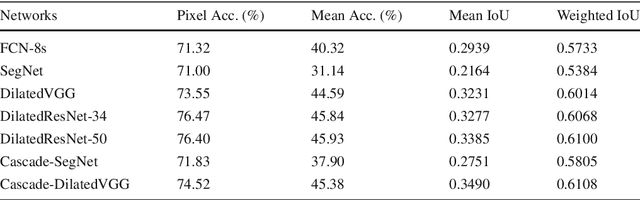
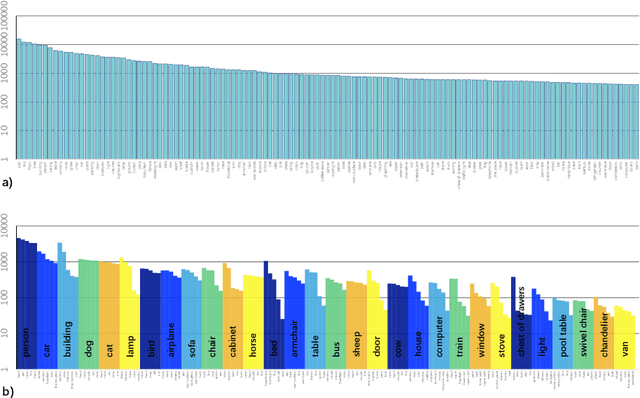
Scene parsing, or recognizing and segmenting objects and stuff in an image, is one of the key problems in computer vision. Despite the community's efforts in data collection, there are still few image datasets covering a wide range of scenes and object categories with dense and detailed annotations for scene parsing. In this paper, we introduce and analyze the ADE20K dataset, spanning diverse annotations of scenes, objects, parts of objects, and in some cases even parts of parts. A generic network design called Cascade Segmentation Module is then proposed to enable the segmentation networks to parse a scene into stuff, objects, and object parts in a cascade. We evaluate the proposed module integrated within two existing semantic segmentation networks, yielding significant improvements for scene parsing. We further show that the scene parsing networks trained on ADE20K can be applied to a wide variety of scenes and objects.
Acquisition of Localization Confidence for Accurate Object Detection
Jul 30, 2018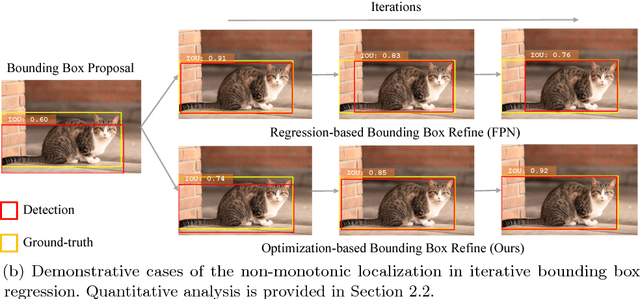
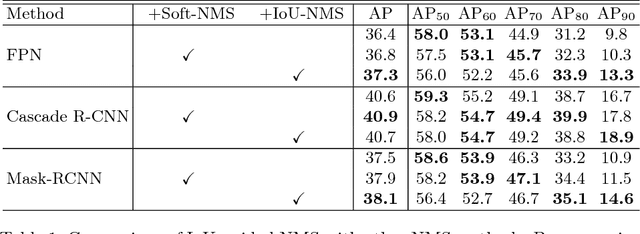
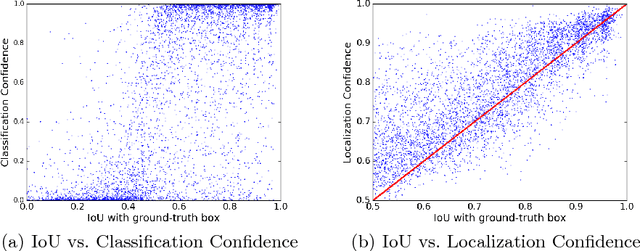
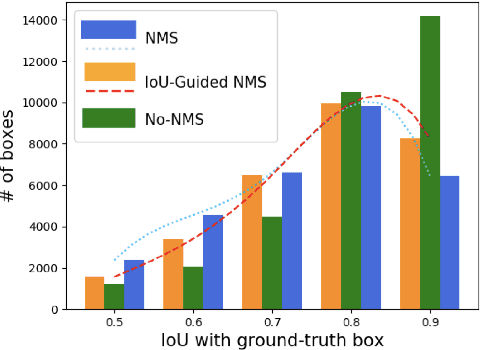
Modern CNN-based object detectors rely on bounding box regression and non-maximum suppression to localize objects. While the probabilities for class labels naturally reflect classification confidence, localization confidence is absent. This makes properly localized bounding boxes degenerate during iterative regression or even suppressed during NMS. In the paper we propose IoU-Net learning to predict the IoU between each detected bounding box and the matched ground-truth. The network acquires this confidence of localization, which improves the NMS procedure by preserving accurately localized bounding boxes. Furthermore, an optimization-based bounding box refinement method is proposed, where the predicted IoU is formulated as the objective. Extensive experiments on the MS-COCO dataset show the effectiveness of IoU-Net, as well as its compatibility with and adaptivity to several state-of-the-art object detectors.
Unified Perceptual Parsing for Scene Understanding
Jul 26, 2018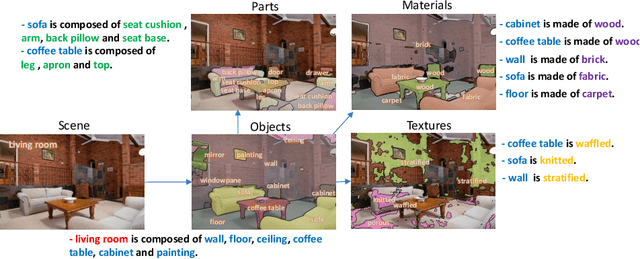

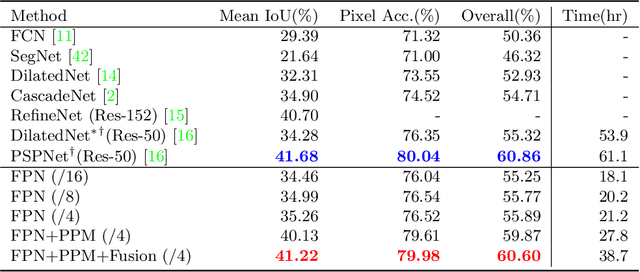
Humans recognize the visual world at multiple levels: we effortlessly categorize scenes and detect objects inside, while also identifying the textures and surfaces of the objects along with their different compositional parts. In this paper, we study a new task called Unified Perceptual Parsing, which requires the machine vision systems to recognize as many visual concepts as possible from a given image. A multi-task framework called UPerNet and a training strategy are developed to learn from heterogeneous image annotations. We benchmark our framework on Unified Perceptual Parsing and show that it is able to effectively segment a wide range of concepts from images. The trained networks are further applied to discover visual knowledge in natural scenes. Models are available at \url{https://github.com/CSAILVision/unifiedparsing}.
Learning Visually-Grounded Semantics from Contrastive Adversarial Samples
Jun 27, 2018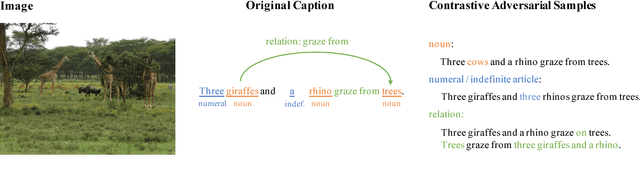

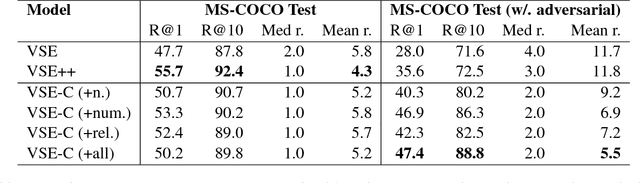

We study the problem of grounding distributional representations of texts on the visual domain, namely visual-semantic embeddings (VSE for short). Begin with an insightful adversarial attack on VSE embeddings, we show the limitation of current frameworks and image-text datasets (e.g., MS-COCO) both quantitatively and qualitatively. The large gap between the number of possible constitutions of real-world semantics and the size of parallel data, to a large extent, restricts the model to establish the link between textual semantics and visual concepts. We alleviate this problem by augmenting the MS-COCO image captioning datasets with textual contrastive adversarial samples. These samples are synthesized using linguistic rules and the WordNet knowledge base. The construction procedure is both syntax- and semantics-aware. The samples enforce the model to ground learned embeddings to concrete concepts within the image. This simple but powerful technique brings a noticeable improvement over the baselines on a diverse set of downstream tasks, in addition to defending known-type adversarial attacks. We release the codes at https://github.com/ExplorerFreda/VSE-C.
CrowdHuman: A Benchmark for Detecting Human in a Crowd
Apr 30, 2018
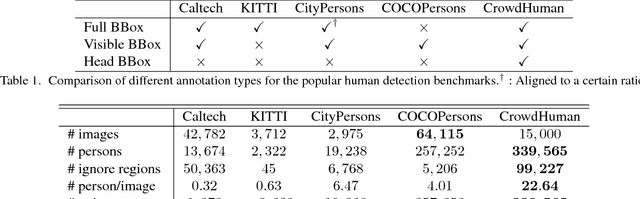

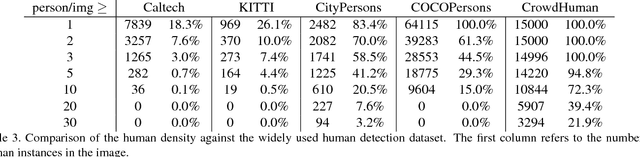
Human detection has witnessed impressive progress in recent years. However, the occlusion issue of detecting human in highly crowded environments is far from solved. To make matters worse, crowd scenarios are still under-represented in current human detection benchmarks. In this paper, we introduce a new dataset, called CrowdHuman, to better evaluate detectors in crowd scenarios. The CrowdHuman dataset is large, rich-annotated and contains high diversity. There are a total of $470K$ human instances from the train and validation subsets, and $~22.6$ persons per image, with various kinds of occlusions in the dataset. Each human instance is annotated with a head bounding-box, human visible-region bounding-box and human full-body bounding-box. Baseline performance of state-of-the-art detection frameworks on CrowdHuman is presented. The cross-dataset generalization results of CrowdHuman dataset demonstrate state-of-the-art performance on previous dataset including Caltech-USA, CityPersons, and Brainwash without bells and whistles. We hope our dataset will serve as a solid baseline and help promote future research in human detection tasks.
MegDet: A Large Mini-Batch Object Detector
Apr 11, 2018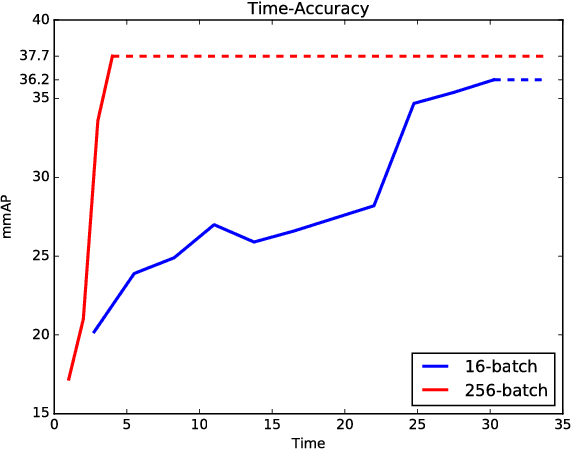
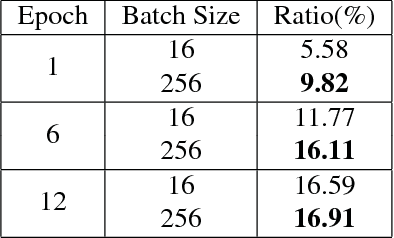

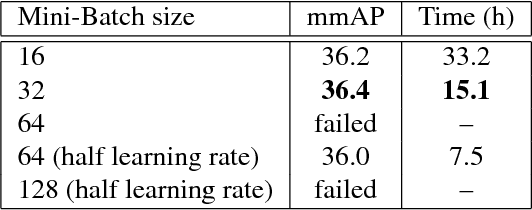
The improvements in recent CNN-based object detection works, from R-CNN [11], Fast/Faster R-CNN [10, 31] to recent Mask R-CNN [14] and RetinaNet [24], mainly come from new network, new framework, or novel loss design. But mini-batch size, a key factor in the training, has not been well studied. In this paper, we propose a Large MiniBatch Object Detector (MegDet) to enable the training with much larger mini-batch size than before (e.g. from 16 to 256), so that we can effectively utilize multiple GPUs (up to 128 in our experiments) to significantly shorten the training time. Technically, we suggest a learning rate policy and Cross-GPU Batch Normalization, which together allow us to successfully train a large mini-batch detector in much less time (e.g., from 33 hours to 4 hours), and achieve even better accuracy. The MegDet is the backbone of our submission (mmAP 52.5%) to COCO 2017 Challenge, where we won the 1st place of Detection task.
Repulsion Loss: Detecting Pedestrians in a Crowd
Mar 26, 2018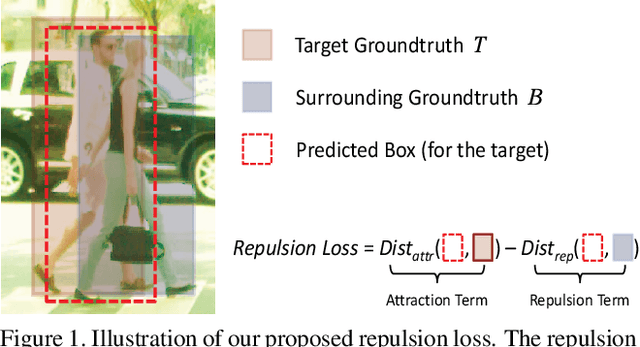
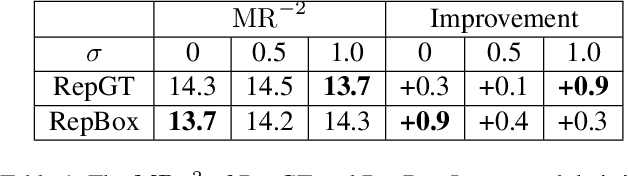
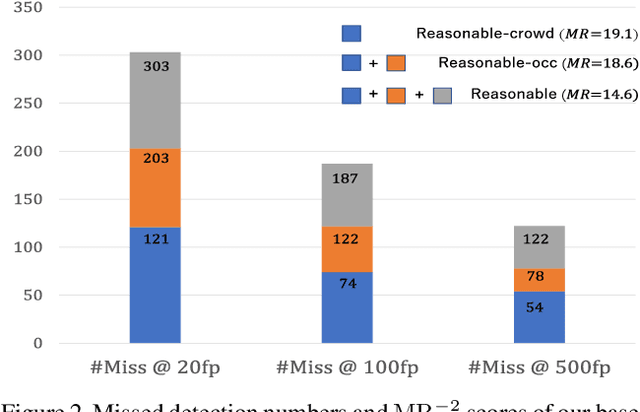
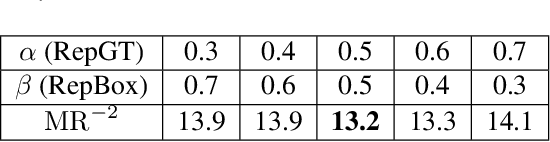
Detecting individual pedestrians in a crowd remains a challenging problem since the pedestrians often gather together and occlude each other in real-world scenarios. In this paper, we first explore how a state-of-the-art pedestrian detector is harmed by crowd occlusion via experimentation, providing insights into the crowd occlusion problem. Then, we propose a novel bounding box regression loss specifically designed for crowd scenes, termed repulsion loss. This loss is driven by two motivations: the attraction by target, and the repulsion by other surrounding objects. The repulsion term prevents the proposal from shifting to surrounding objects thus leading to more crowd-robust localization. Our detector trained by repulsion loss outperforms all the state-of-the-art methods with a significant improvement in occlusion cases.
What Can Help Pedestrian Detection?
May 08, 2017
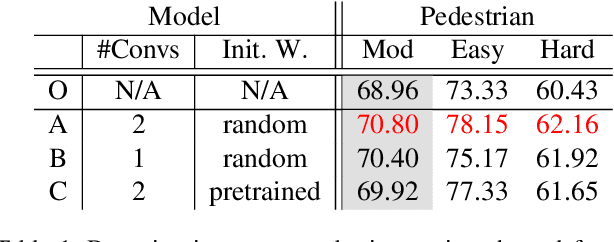

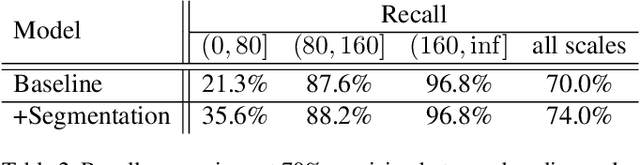
Aggregating extra features has been considered as an effective approach to boost traditional pedestrian detection methods. However, there is still a lack of studies on whether and how CNN-based pedestrian detectors can benefit from these extra features. The first contribution of this paper is exploring this issue by aggregating extra features into CNN-based pedestrian detection framework. Through extensive experiments, we evaluate the effects of different kinds of extra features quantitatively. Moreover, we propose a novel network architecture, namely HyperLearner, to jointly learn pedestrian detection as well as the given extra feature. By multi-task training, HyperLearner is able to utilize the information of given features and improve detection performance without extra inputs in inference. The experimental results on multiple pedestrian benchmarks validate the effectiveness of the proposed HyperLearner.