 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the trade-off in personalized speech enhancement with cross-task knowledge distillation
Nov 05, 2022


Personalized speech enhancement (PSE) models achieve promising results compared with unconditional speech enhancement models due to their ability to remove interfering speech in addition to background noise. Unlike unconditional speech enhancement, causal PSE models may occasionally remove the target speech by mistake. The PSE models also tend to leak interfering speech when the target speaker is silent for an extended period. We show that existing PSE methods suffer from a trade-off between speech over-suppression and interference leakage by addressing one problem at the expense of the other. We propose a new PSE model training framework using cross-task knowledge distillation to mitigate this trade-off. Specifically, we utilize a personalized voice activity detector (pVAD) during training to exclude the non-target speech frames that are wrongly identified as containing the target speaker with hard or soft classification. This prevents the PSE model from being too aggressive while still allowing the model to learn to suppress the input speech when it is likely to be spoken by interfering speakers. Comprehensive evaluation results are presented, covering various PSE usage scenarios.
Real-Time Joint Personalized Speech Enhancement and Acoustic Echo Cancellation with E3Net
Nov 04, 2022


Personalized speech enhancement (PSE), a process of estimating a clean target speech signal in real time by leveraging a speaker embedding vector of the target talker, has garnered much attention from the research community due to the recent surge of online meetings across the globe. For practical full duplex communication, PSE models require an acoustic echo cancellation (AEC) capability. In this work, we employ a recently proposed causal end-to-end enhancement network (E3Net) and modify it to obtain a joint PSE-AEC model. We dedicate the early layers to the AEC task while encouraging later layers for personalization by adding a bypass connection from the early layers to the mask prediction layer. This allows us to employ a multi-task learning framework for joint PSE and AEC training. We provide extensive evaluation test scenarios with both simulated and real-world recordings. The results show that our joint model comes close to the expert models for each task and performs significantly better for the combined PSE-AEC scenario.
VarArray Meets t-SOT: Advancing the State of the Art of Streaming Distant Conversational Speech Recognition
Sep 12, 2022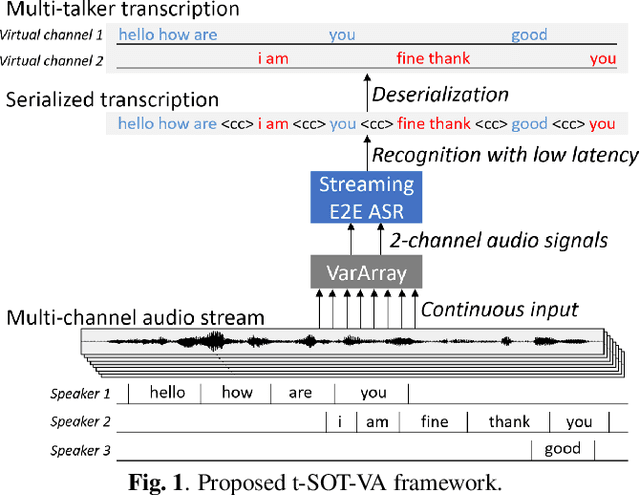
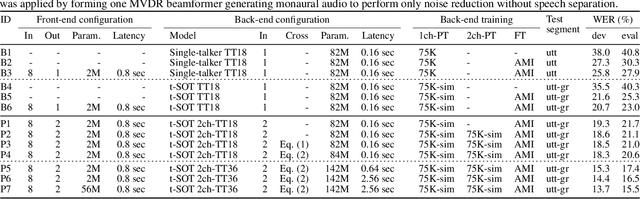
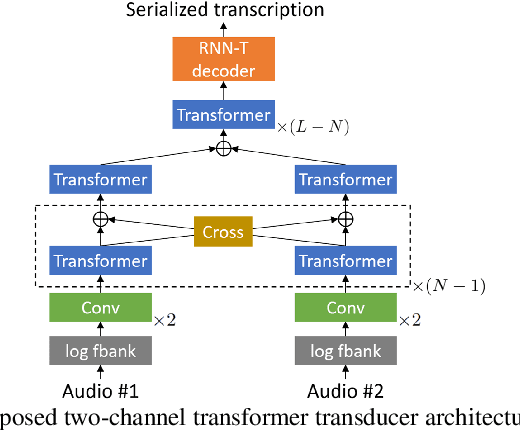

This paper presents a novel streaming automatic speech recognition (ASR) framework for multi-talker overlapping speech captured by a distant microphone array with an arbitrary geometry. Our framework, named t-SOT-VA, capitalizes on independently developed two recent technologies; array-geometry-agnostic continuous speech separation, or VarArray, and streaming multi-talker ASR based on token-level serialized output training (t-SOT). To combine the best of both technologies, we newly design a t-SOT-based ASR model that generates a serialized multi-talker transcription based on two separated speech signals from VarArray. We also propose a pre-training scheme for such an ASR model where we simulate VarArray's output signals based on monaural single-talker ASR training data. Conversation transcription experiments using the AMI meeting corpus show that the system based on the proposed framework significantly outperforms conventional ones. Our system achieves the state-of-the-art word error rates of 13.7% and 15.5% for the AMI development and evaluation sets, respectively, in the multiple-distant-microphone setting while retaining the streaming inference capability.
Target Speaker Voice Activity Detection with Transformers and Its Integration with End-to-End Neural Diarization
Aug 27, 2022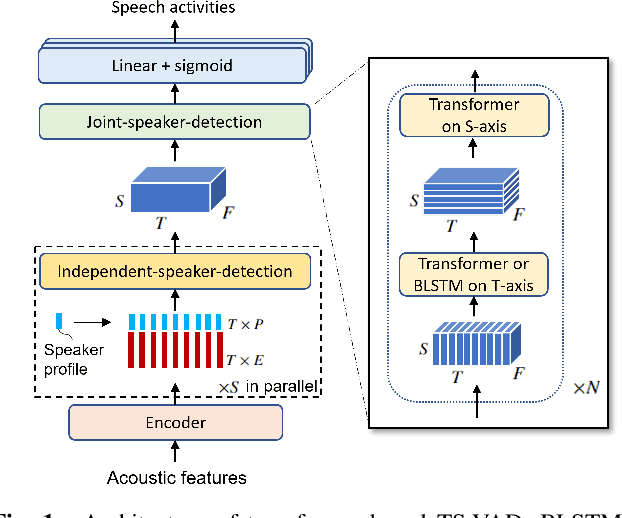
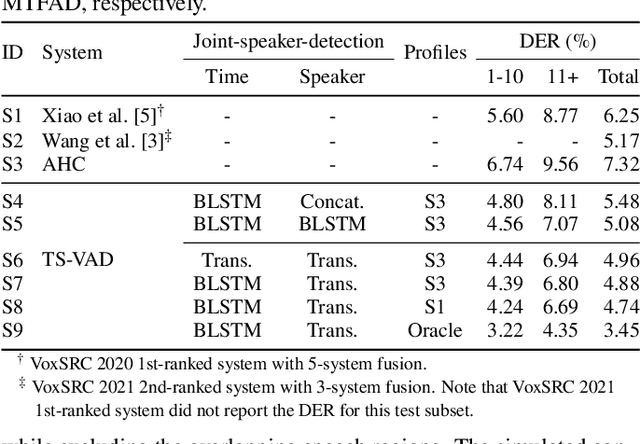
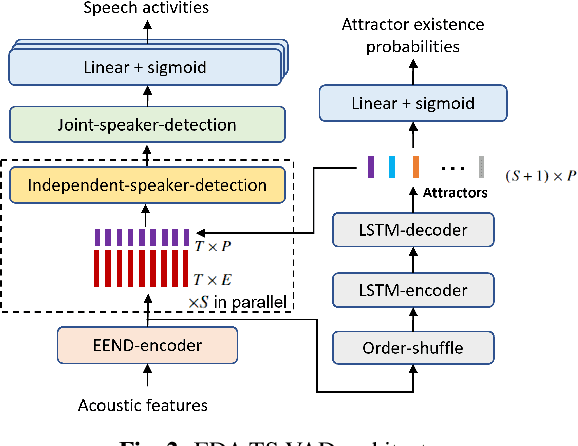
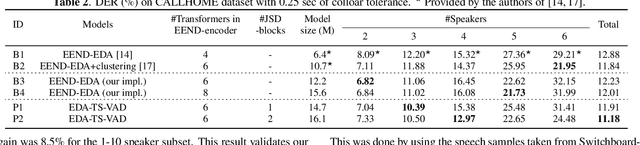
This paper describes a speaker diarization model based on target speaker voice activity detection (TS-VAD) using transformers. To overcome the original TS-VAD model's drawback of being unable to handle an arbitrary number of speakers, we investigate model architectures that use input tensors with variable-length time and speaker dimensions. Transformer layers are applied to the speaker axis to make the model output insensitive to the order of the speaker profiles provided to the TS-VAD model. Time-wise sequential layers are interspersed between these speaker-wise transformer layers to allow the temporal and cross-speaker correlations of the input speech signal to be captured. We also extend a diarization model based on end-to-end neural diarization with encoder-decoder based attractors (EEND-EDA) by replacing its dot-product-based speaker detection layer with the transformer-based TS-VAD. Experimental results on VoxConverse show that using the transformers for the cross-speaker modeling reduces the diarization error rate (DER) of TS-VAD by 10.9%, achieving a new state-of-the-art (SOTA) DER of 4.74%. Also, our extended EEND-EDA reduces DER by 6.9% on the CALLHOME dataset relative to the original EEND-EDA with a similar model size, achieving a new SOTA DER of 11.18% under a widely used training data setting.
i-Code: An Integrative and Composable Multimodal Learning Framework
May 05, 2022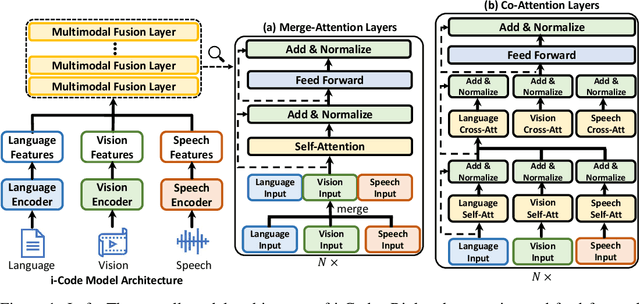
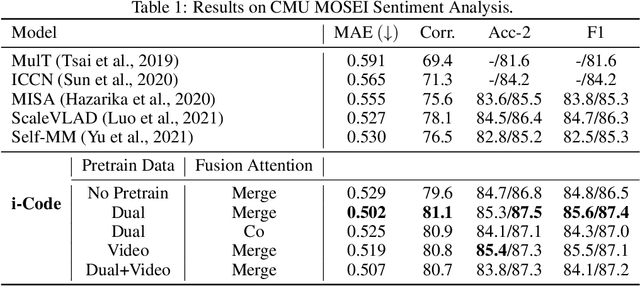
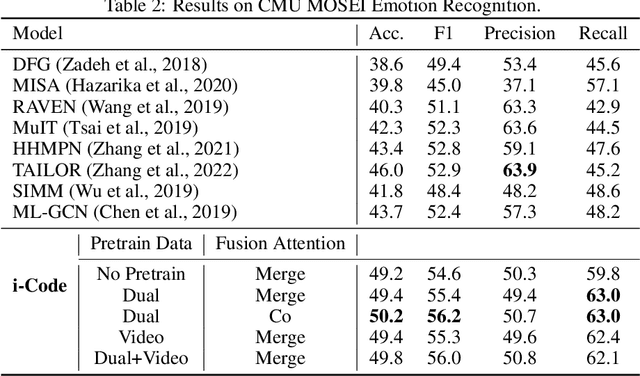

Human intelligence is multimodal; we integrate visual, linguistic, and acoustic signals to maintain a holistic worldview. Most current pretraining methods, however, are limited to one or two modalities. We present i-Code, a self-supervised pretraining framework where users may flexibly combine the modalities of vision, speech, and language into unified and general-purpose vector representations. In this framework, data from each modality are first given to pretrained single-modality encoders. The encoder outputs are then integrated with a multimodal fusion network, which uses novel attention mechanisms and other architectural innovations to effectively combine information from the different modalities. The entire system is pretrained end-to-end with new objectives including masked modality unit modeling and cross-modality contrastive learning. Unlike previous research using only video for pretraining, the i-Code framework can dynamically process single, dual, and triple-modality data during training and inference, flexibly projecting different combinations of modalities into a single representation space. Experimental results demonstrate how i-Code can outperform state-of-the-art techniques on five video understanding tasks and the GLUE NLP benchmark, improving by as much as 11% and demonstrating the power of integrative multimodal pretraining.
Ultra Fast Speech Separation Model with Teacher Student Learning
Apr 27, 2022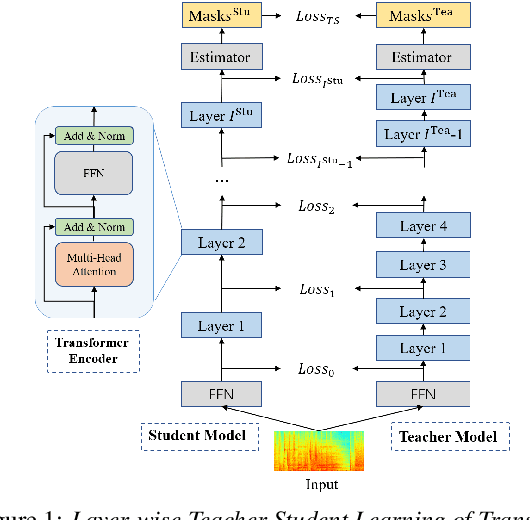
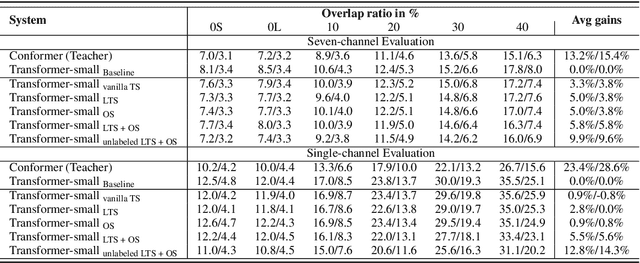
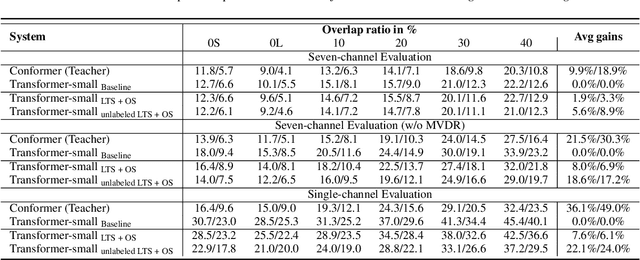
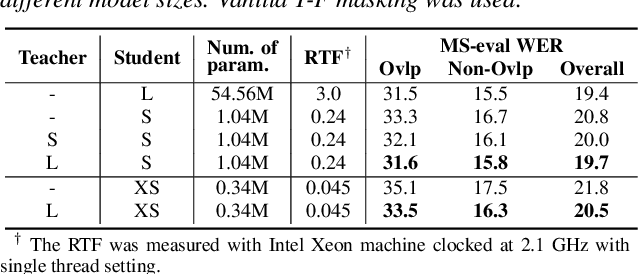
Transformer has been successfully applied to speech separation recently with its strong long-dependency modeling capacity using a self-attention mechanism. However, Transformer tends to have heavy run-time costs due to the deep encoder layers, which hinders its deployment on edge devices. A small Transformer model with fewer encoder layers is preferred for computational efficiency, but it is prone to performance degradation. In this paper, an ultra fast speech separation Transformer model is proposed to achieve both better performance and efficiency with teacher student learning (T-S learning). We introduce layer-wise T-S learning and objective shifting mechanisms to guide the small student model to learn intermediate representations from the large teacher model. Compared with the small Transformer model trained from scratch, the proposed T-S learning method reduces the word error rate (WER) by more than 5% for both multi-channel and single-channel speech separation on LibriCSS dataset. Utilizing more unlabeled speech data, our ultra fast speech separation models achieve more than 10% relative WER reduction.
Leveraging Real Conversational Data for Multi-Channel Continuous Speech Separation
Apr 07, 2022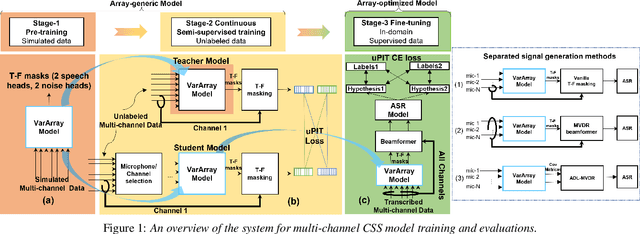
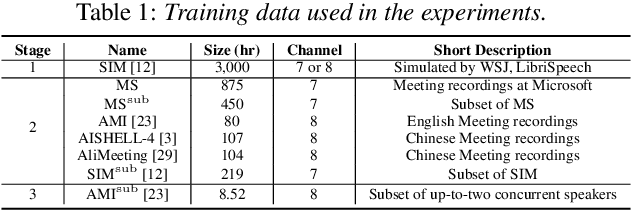

Existing multi-channel continuous speech separation (CSS) models are heavily dependent on supervised data - either simulated data which causes data mismatch between the training and real-data testing, or the real transcribed overlapping data, which is difficult to be acquired, hindering further improvements in the conversational/meeting transcription tasks. In this paper, we propose a three-stage training scheme for the CSS model that can leverage both supervised data and extra large-scale unsupervised real-world conversational data. The scheme consists of two conventional training approaches -- pre-training using simulated data and ASR-loss-based training using transcribed data -- and a novel continuous semi-supervised training between the two, in which the CSS model is further trained by using real data based on the teacher-student learning framework. We apply this scheme to an array-geometry-agnostic CSS model, which can use the multi-channel data collected from any microphone array. Large-scale meeting transcription experiments are carried out on both Microsoft internal meeting data and the AMI meeting corpus. The steady improvement by each training stage has been observed, showing the effect of the proposed method that enables leveraging real conversational data for CSS model training.
Fast Real-time Personalized Speech Enhancement: End-to-End Enhancement Network (E3Net) and Knowledge Distillation
Apr 02, 2022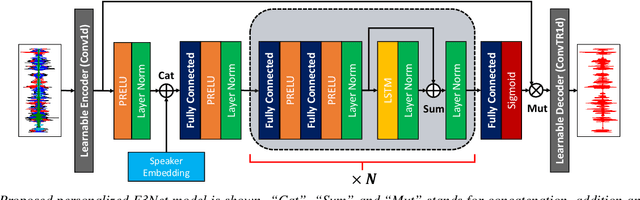
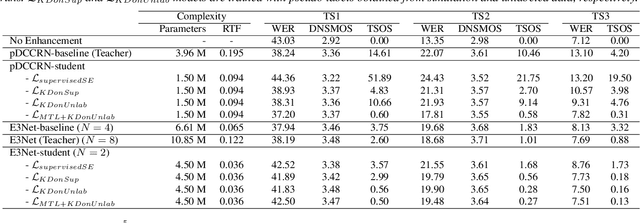
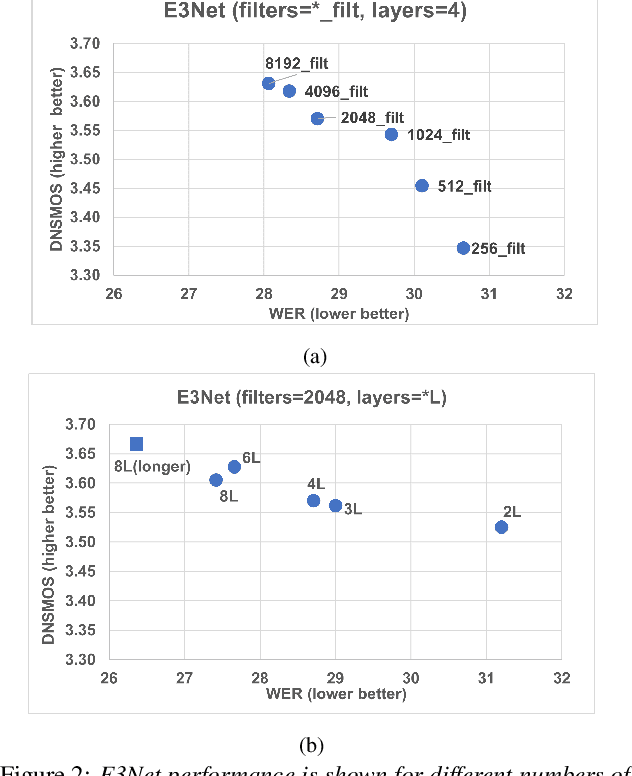
This paper investigates how to improve the runtime speed of personalized speech enhancement (PSE) networks while maintaining the model quality. Our approach includes two aspects: architecture and knowledge distillation (KD). We propose an end-to-end enhancement (E3Net) model architecture, which is $3\times$ faster than a baseline STFT-based model. Besides, we use KD techniques to develop compressed student models without significantly degrading quality. In addition, we investigate using noisy data without reference clean signals for training the student models, where we combine KD with multi-task learning (MTL) using automatic speech recognition (ASR) loss. Our results show that E3Net provides better speech and transcription quality with a lower target speaker over-suppression (TSOS) rate than the baseline model. Furthermore, we show that the KD methods can yield student models that are $2-4\times$ faster than the teacher and provides reasonable quality. Combining KD and MTL improves the ASR and TSOS metrics without degrading the speech quality.
Streaming Speaker-Attributed ASR with Token-Level Speaker Embeddings
Mar 30, 2022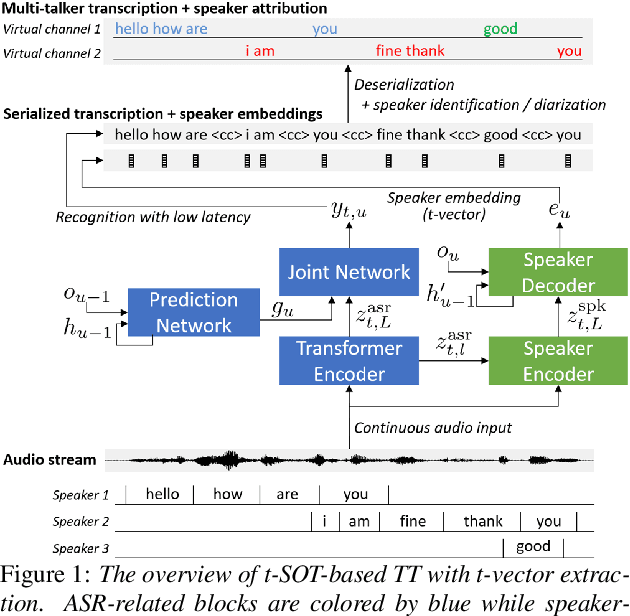
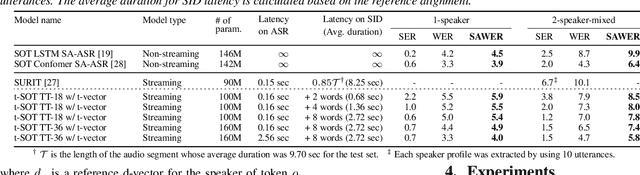
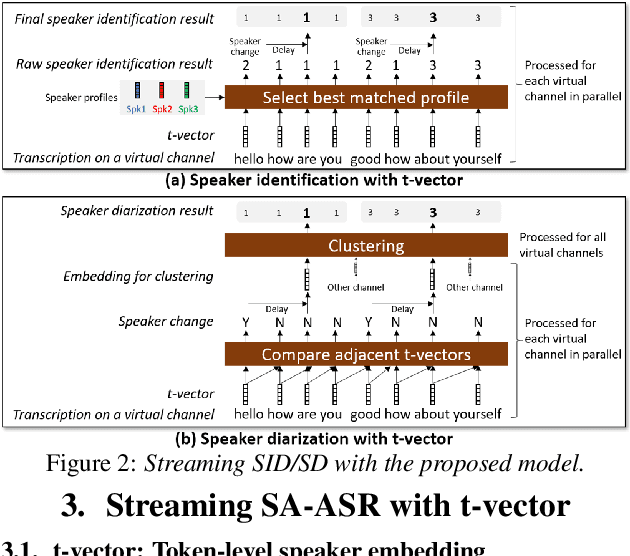
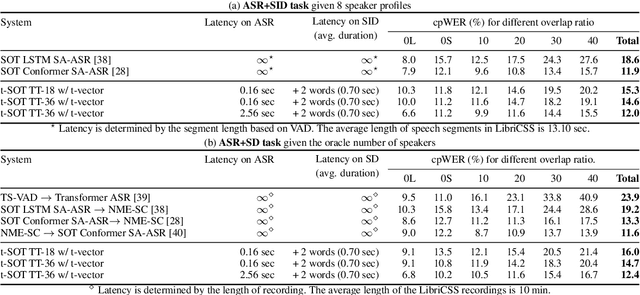
This paper presents a streaming speaker-attributed automatic speech recognition (SA-ASR) model that can recognize "who spoke what" with low latency even when multiple people are speaking simultaneously. Our model is based on token-level serialized output training (t-SOT) which was recently proposed to transcribe multi-talker speech in a streaming fashion. To further recognize speaker identities, we propose an encoder-decoder based speaker embedding extractor that can estimate a speaker representation for each recognized token not only from non-overlapping speech but also from overlapping speech. The proposed speaker embedding, named t-vector, is extracted synchronously with the t-SOT ASR model, enabling joint execution of speaker identification (SID) or speaker diarization (SD) with the multi-talker transcription with low latency. We evaluate the proposed model for a joint task of ASR and SID/SD by using LibriSpeechMix and LibriCSS corpora. The proposed model achieves substantially better accuracy than a prior streaming model and shows comparable or sometimes even superior results to the state-of-the-art offline SA-ASR model.
ICASSP 2022 Deep Noise Suppression Challenge
Feb 27, 2022
The Deep Noise Suppression (DNS) challenge is designed to foster innovation in the area of noise suppression to achieve superior perceptual speech quality. This is the 4th DNS challenge, with the previous editions held at INTERSPEECH 2020, ICASSP 2021, and INTERSPEECH 2021. We open-source datasets and test sets for researchers to train their deep noise suppression models, as well as a subjective evaluation framework based on ITU-T P.835 to rate and rank-order the challenge entries. We provide access to DNSMOS P.835 and word accuracy (WAcc) APIs to challenge participants to help with iterative model improvements. In this challenge, we introduced the following changes: (i) Included mobile device scenarios in the blind test set; (ii) Included a personalized noise suppression track with baseline; (iii) Added WAcc as an objective metric; (iv) Included DNSMOS P.835; (v) Made the training datasets and test sets fullband (48 kHz). We use an average of WAcc and subjective scores P.835 SIG, BAK, and OVRL to get the final score for ranking the DNS models. We believe that as a research community, we still have a long way to go in achieving excellent speech quality in challenging noisy real-world scenarios.