 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models
Feb 12, 2024



Visually-conditioned language models (VLMs) have seen growing adoption in applications such as visual dialogue, scene understanding, and robotic task planning; adoption that has fueled a wealth of new models such as LLaVa, InstructBLIP, and PaLI-3. Despite the volume of new releases, key design decisions around image preprocessing, architecture, and optimization are under-explored, making it challenging to understand what factors account for model performance $-$ a challenge further complicated by the lack of objective, consistent evaluations. To address these gaps, we first compile a suite of standardized evaluations spanning visual question answering, object localization from language, and targeted challenge sets that probe properties such as hallucination; evaluations that provide calibrated, fine-grained insight into a VLM's capabilities. Second, we rigorously investigate VLMs along key design axes, including pretrained visual representations and quantifying the tradeoffs of using base vs. instruct-tuned language models, amongst others. We couple our analysis with three resource contributions: (1) a unified framework for evaluating VLMs, (2) optimized, flexible code for VLM training, and (3) checkpoints for all models, including a family of VLMs at the 7-13B scale that strictly outperform InstructBLIP and LLaVa v1.5, the state-of-the-art in open-source VLMs.
From Propeller Damage Estimation and Adaptation to Fault Tolerant Control: Enhancing Quadrotor Resilience
Oct 19, 2023



Aerial robots are required to remain operational even in the event of system disturbances, damages, or failures to ensure resilient and robust task completion and safety. One common failure case is propeller damage, which presents a significant challenge in both quantification and compensation. We propose a novel adaptive control scheme capable of detecting and compensating for multi-rotor propeller damages, ensuring safe and robust flight performances. Our control scheme includes an L1 adaptive controller for damage inference and compensation of single or dual propellers, with the capability to seamlessly transition to a fault-tolerant solution in case the damage becomes severe. We experimentally identify the conditions under which the L1 adaptive solution remains preferable over a fault-tolerant alternative. Experimental results validate the proposed approach, demonstrating its effectiveness in running the adaptive strategy in real time on a quadrotor even in case of damage to multiple propellers.
Synthetic Cross-language Information Retrieval Training Data
Apr 29, 2023A key stumbling block for neural cross-language information retrieval (CLIR) systems has been the paucity of training data. The appearance of the MS MARCO monolingual training set led to significant advances in the state of the art in neural monolingual retrieval. By translating the MS MARCO documents into other languages using machine translation, this resource has been made useful to the CLIR community. Yet such translation suffers from a number of problems. While MS MARCO is a large resource, it is of fixed size; its genre and domain of discourse are fixed; and the translated documents are not written in the language of a native speaker of the language, but rather in translationese. To address these problems, we introduce the JH-POLO CLIR training set creation methodology. The approach begins by selecting a pair of non-English passages. A generative large language model is then used to produce an English query for which the first passage is relevant and the second passage is not relevant. By repeating this process, collections of arbitrary size can be created in the style of MS MARCO but using naturally-occurring documents in any desired genre and domain of discourse. This paper describes the methodology in detail, shows its use in creating new CLIR training sets, and describes experiments using the newly created training data.
Behavior Retrieval: Few-Shot Imitation Learning by Querying Unlabeled Datasets
Apr 18, 2023



Enabling robots to learn novel visuomotor skills in a data-efficient manner remains an unsolved problem with myriad challenges. A popular paradigm for tackling this problem is through leveraging large unlabeled datasets that have many behaviors in them and then adapting a policy to a specific task using a small amount of task-specific human supervision (i.e. interventions or demonstrations). However, how best to leverage the narrow task-specific supervision and balance it with offline data remains an open question. Our key insight in this work is that task-specific data not only provides new data for an agent to train on but can also inform the type of prior data the agent should use for learning. Concretely, we propose a simple approach that uses a small amount of downstream expert data to selectively query relevant behaviors from an offline, unlabeled dataset (including many sub-optimal behaviors). The agent is then jointly trained on the expert and queried data. We observe that our method learns to query only the relevant transitions to the task, filtering out sub-optimal or task-irrelevant data. By doing so, it is able to learn more effectively from the mix of task-specific and offline data compared to naively mixing the data or only using the task-specific data. Furthermore, we find that our simple querying approach outperforms more complex goal-conditioned methods by 20% across simulated and real robotic manipulation tasks from images. See https://sites.google.com/view/behaviorretrieval for videos and code.
Language-Driven Representation Learning for Robotics
Feb 24, 2023



Recent work in visual representation learning for robotics demonstrates the viability of learning from large video datasets of humans performing everyday tasks. Leveraging methods such as masked autoencoding and contrastive learning, these representations exhibit strong transfer to policy learning for visuomotor control. But, robot learning encompasses a diverse set of problems beyond control including grasp affordance prediction, language-conditioned imitation learning, and intent scoring for human-robot collaboration, amongst others. First, we demonstrate that existing representations yield inconsistent results across these tasks: masked autoencoding approaches pick up on low-level spatial features at the cost of high-level semantics, while contrastive learning approaches capture the opposite. We then introduce Voltron, a framework for language-driven representation learning from human videos and associated captions. Voltron trades off language-conditioned visual reconstruction to learn low-level visual patterns, and visually-grounded language generation to encode high-level semantics. We also construct a new evaluation suite spanning five distinct robot learning problems $\unicode{x2013}$ a unified platform for holistically evaluating visual representations for robotics. Through comprehensive, controlled experiments across all five problems, we find that Voltron's language-driven representations outperform the prior state-of-the-art, especially on targeted problems requiring higher-level features.
Parameter-efficient Zero-shot Transfer for Cross-Language Dense Retrieval with Adapters
Dec 20, 2022A popular approach to creating a zero-shot cross-language retrieval model is to substitute a monolingual pretrained language model in the retrieval model with a multilingual pretrained language model such as Multilingual BERT. This multilingual model is fined-tuned to the retrieval task with monolingual data such as English MS MARCO using the same training recipe as the monolingual retrieval model used. However, such transferred models suffer from mismatches in the languages of the input text during training and inference. In this work, we propose transferring monolingual retrieval models using adapters, a parameter-efficient component for a transformer network. By adding adapters pretrained on language tasks for a specific language with task-specific adapters, prior work has shown that the adapter-enhanced models perform better than fine-tuning the entire model when transferring across languages in various NLP tasks. By constructing dense retrieval models with adapters, we show that models trained with monolingual data are more effective than fine-tuning the entire model when transferring to a Cross Language Information Retrieval (CLIR) setting. However, we found that the prior suggestion of replacing the language adapters to match the target language at inference time is suboptimal for dense retrieval models. We provide an in-depth analysis of this discrepancy between other cross-language NLP tasks and CLIR.
Play it by Ear: Learning Skills amidst Occlusion through Audio-Visual Imitation Learning
May 30, 2022
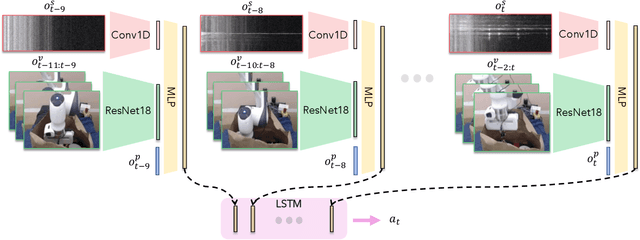
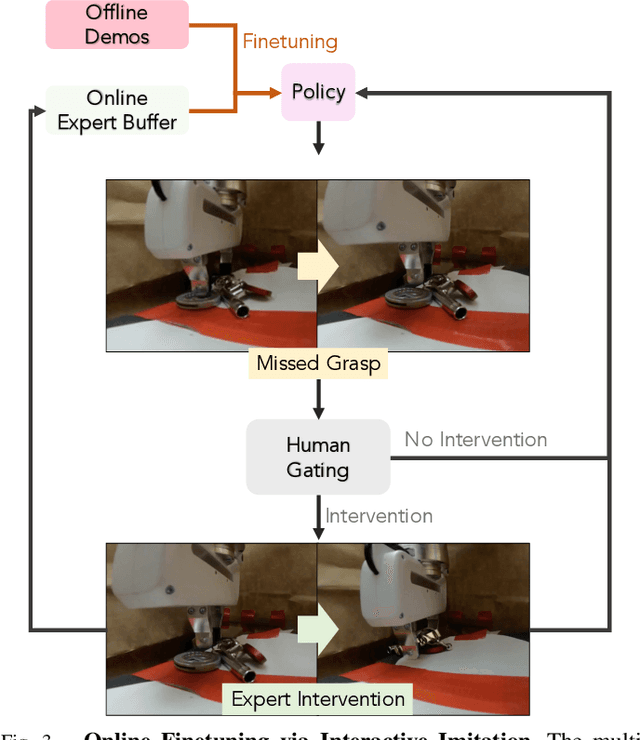

Humans are capable of completing a range of challenging manipulation tasks that require reasoning jointly over modalities such as vision, touch, and sound. Moreover, many such tasks are partially-observed; for example, taking a notebook out of a backpack will lead to visual occlusion and require reasoning over the history of audio or tactile information. While robust tactile sensing can be costly to capture on robots, microphones near or on a robot's gripper are a cheap and easy way to acquire audio feedback of contact events, which can be a surprisingly valuable data source for perception in the absence of vision. Motivated by the potential for sound to mitigate visual occlusion, we aim to learn a set of challenging partially-observed manipulation tasks from visual and audio inputs. Our proposed system learns these tasks by combining offline imitation learning from a modest number of tele-operated demonstrations and online finetuning using human provided interventions. In a set of simulated tasks, we find that our system benefits from using audio, and that by using online interventions we are able to improve the success rate of offline imitation learning by ~20%. Finally, we find that our system can complete a set of challenging, partially-observed tasks on a Franka Emika Panda robot, like extracting keys from a bag, with a 70% success rate, 50% higher than a policy that does not use audio.
C3: Continued Pretraining with Contrastive Weak Supervision for Cross Language Ad-Hoc Retrieval
Apr 25, 2022
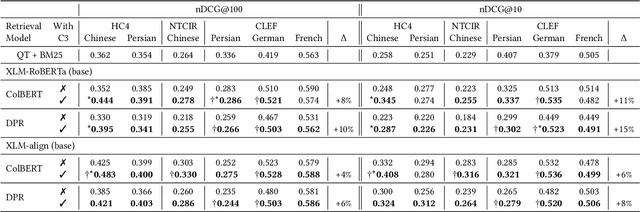
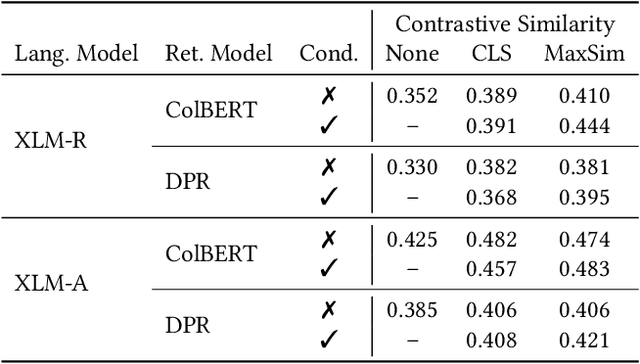
Pretrained language models have improved effectiveness on numerous tasks, including ad-hoc retrieval. Recent work has shown that continuing to pretrain a language model with auxiliary objectives before fine-tuning on the retrieval task can further improve retrieval effectiveness. Unlike monolingual retrieval, designing an appropriate auxiliary task for cross-language mappings is challenging. To address this challenge, we use comparable Wikipedia articles in different languages to further pretrain off-the-shelf multilingual pretrained models before fine-tuning on the retrieval task. We show that our approach yields improvements in retrieval effectiveness.
R3M: A Universal Visual Representation for Robot Manipulation
Mar 23, 2022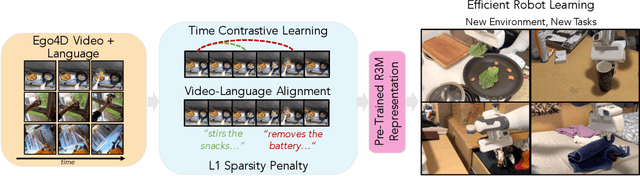
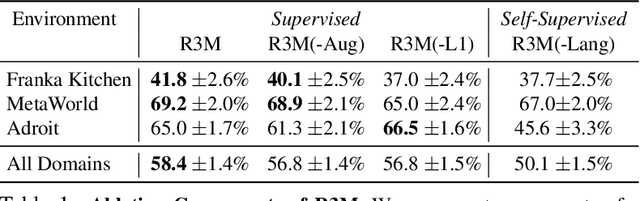
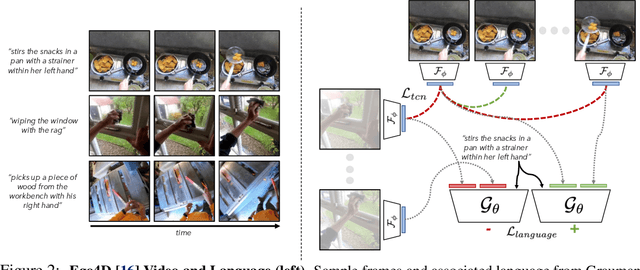
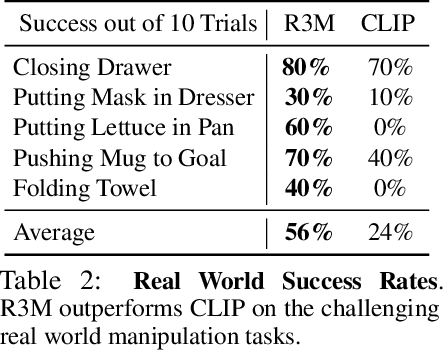
We study how visual representations pre-trained on diverse human video data can enable data-efficient learning of downstream robotic manipulation tasks. Concretely, we pre-train a visual representation using the Ego4D human video dataset using a combination of time-contrastive learning, video-language alignment, and an L1 penalty to encourage sparse and compact representations. The resulting representation, R3M, can be used as a frozen perception module for downstream policy learning. Across a suite of 12 simulated robot manipulation tasks, we find that R3M improves task success by over 20% compared to training from scratch and by over 10% compared to state-of-the-art visual representations like CLIP and MoCo. Furthermore, R3M enables a Franka Emika Panda arm to learn a range of manipulation tasks in a real, cluttered apartment given just 20 demonstrations. Code and pre-trained models are available at https://tinyurl.com/robotr3m.