 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIG-OP: Exploring Large-Scale Unknown Environments on a Fixed Time Budget
Mar 12, 2022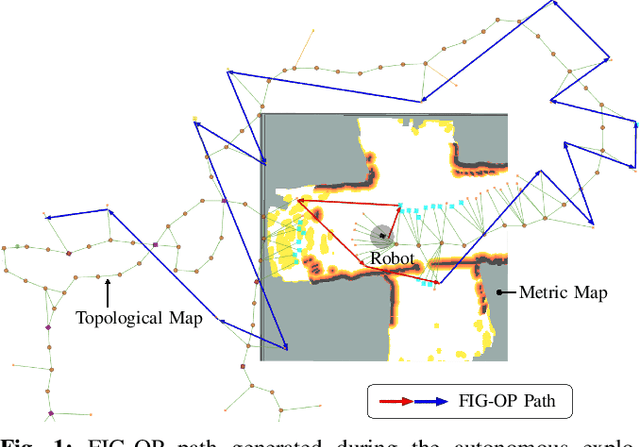
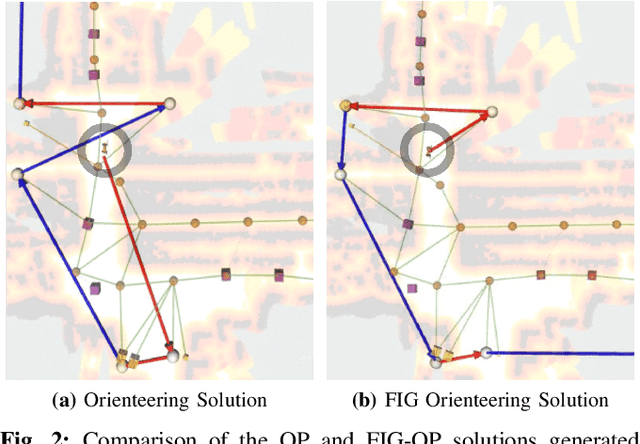
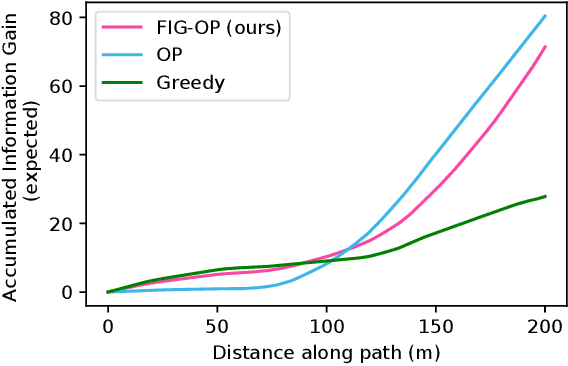
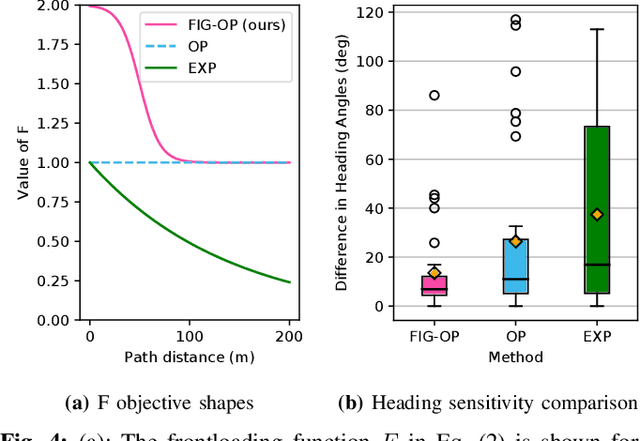
We present a method for autonomous exploration of large-scale unknown environments under mission time constraints. We start by proposing the Frontloaded Information Gain Orienteering Problem (FIG-OP) -- a generalization of the traditional orienteering problem where the assumption of a reliable environmental model no longer holds. The FIG-OP addresses model uncertainty by frontloading expected information gain through the addition of a greedy incentive, effectively expediting the moment in which new area is uncovered. In order to reason across multi-kilometre environments, we solve FIG-OP over an information-efficient world representation, constructed through the aggregation of information from a topological and metric map. Our method was extensively tested and field-hardened across various complex environments, ranging from subway systems to mines. In comparative simulations, we observe that the FIG-OP solution exhibits improved coverage efficiency over solutions generated by greedy and traditional orienteering-based approaches (i.e. severe and minimal model uncertainty assumptions, respectively).
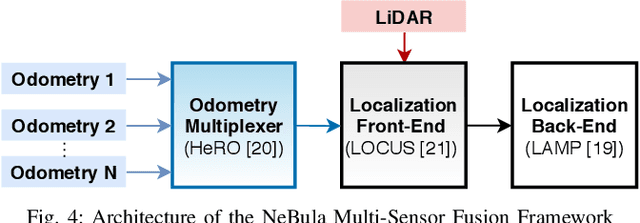
NeBula: Quest for Robotic Autonomy in Challenging Environments; TEAM CoSTAR at the DARPA Subterranean Challenge
Mar 28, 2021

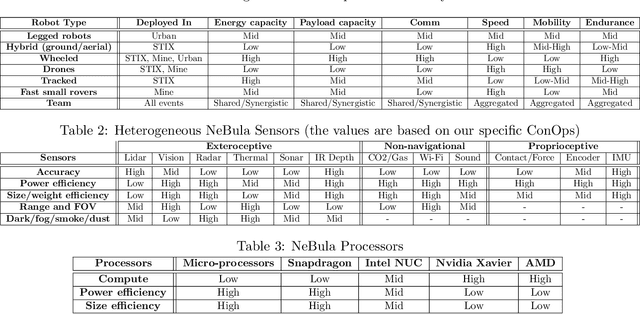
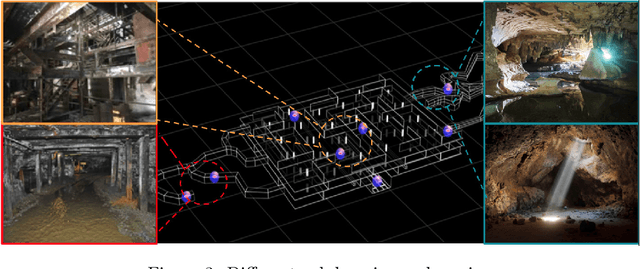
This paper presents and discusses algorithms, hardware, and software architecture developed by the TEAM CoSTAR (Collaborative SubTerranean Autonomous Robots), competing in the DARPA Subterranean Challenge. Specifically, it presents the techniques utilized within the Tunnel (2019) and Urban (2020) competitions, where CoSTAR achieved 2nd and 1st place, respectively. We also discuss CoSTAR's demonstrations in Martian-analog surface and subsurface (lava tubes) exploration. The paper introduces our autonomy solution, referred to as NeBula (Networked Belief-aware Perceptual Autonomy). NeBula is an uncertainty-aware framework that aims at enabling resilient and modular autonomy solutions by performing reasoning and decision making in the belief space (space of probability distributions over the robot and world states). We discuss various components of the NeBula framework, including: (i) geometric and semantic environment mapping; (ii) a multi-modal positioning system; (iii) traversability analysis and local planning; (iv) global motion planning and exploration behavior; (i) risk-aware mission planning; (vi) networking and decentralized reasoning; and (vii) learning-enabled adaptation. We discuss the performance of NeBula on several robot types (e.g. wheeled, legged, flying), in various environments. We discuss the specific results and lessons learned from fielding this solution in the challenging courses of the DARPA Subterranean Challenge competition.
PLGRIM: Hierarchical Value Learning for Large-scale Exploration in Unknown Environments
Feb 10, 2021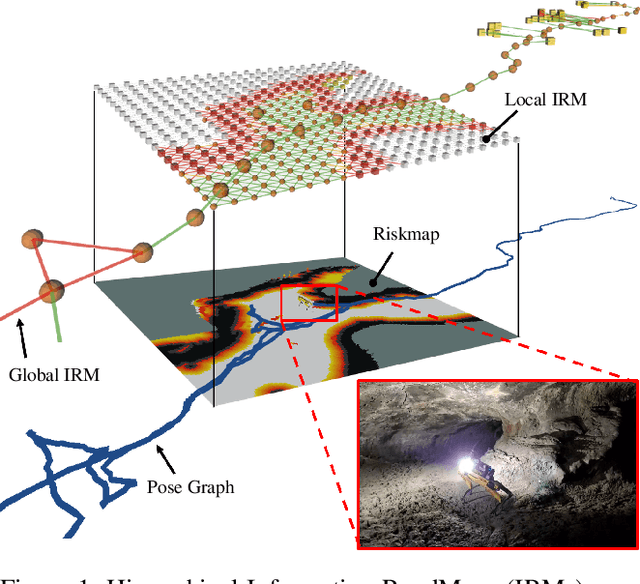
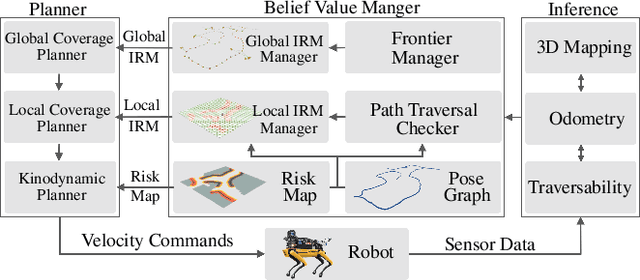
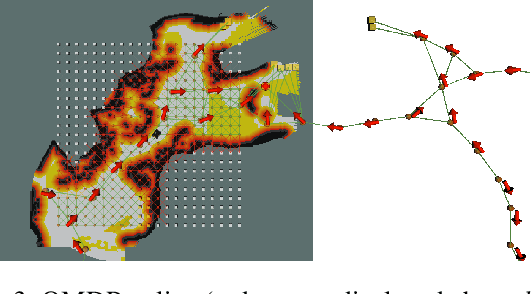
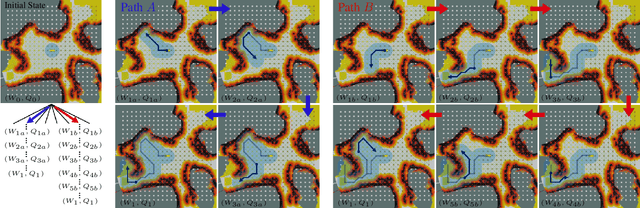
In order for a robot to explore an unknown environment autonomously, it must account for uncertainty in sensor measurements, hazard assessment, localization, and motion execution. Making decisions for maximal reward in a stochastic setting requires learning values and constructing policies over a belief space, i.e., probability distribution of the robot-world state. Value learning over belief spaces suffer from computational challenges in high-dimensional spaces, such as large spatial environments and long temporal horizons for exploration. At the same time, it should be adaptive and resilient to disturbances at run time in order to ensure the robot's safety, as required in many real-world applications. This work proposes a scalable value learning framework, PLGRIM (Probabilistic Local and Global Reasoning on Information roadMaps), that bridges the gap between (i) local, risk-aware resiliency and (ii) global, reward-seeking mission objectives. By leveraging hierarchical belief space planners with information-rich graph structures, PLGRIM can address large-scale exploration problems while providing locally near-optimal coverage plans. PLGRIM is a step toward enabling belief space planners on physical robots operating in unknown and complex environments. We validate our proposed framework with a high-fidelity dynamic simulation in diverse environments and with physical hardware, Boston Dynamics' Spot robot, in a lava tube.
Autonomous Spot: Long-Range Autonomous Exploration of Extreme Environments with Legged Locomotion
Nov 01, 2020
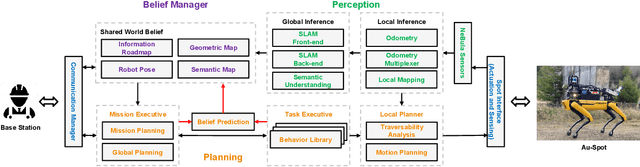

This paper serves as one of the first efforts to enable large-scale and long-duration autonomy using the Boston Dynamics Spot robot. Motivated by exploring extreme environments, particularly those involved in the DARPA Subterranean Challenge, this paper pushes the boundaries of the state-of-practice in enabling legged robotic systems to accomplish real-world complex missions in relevant scenarios. In particular, we discuss the behaviors and capabilities which emerge from the integration of the autonomy architecture NeBula (Networked Belief-aware Perceptual Autonomy) with next-generation mobility systems. We will discuss the hardware and software challenges, and solutions in mobility, perception, autonomy, and very briefly, wireless networking, as well as lessons learned and future directions. We demonstrate the performance of the proposed solutions on physical systems in real-world scenarios.
Task-Informed Fidelity Management for Speeding Up Robotics Simulation
Oct 27, 2019

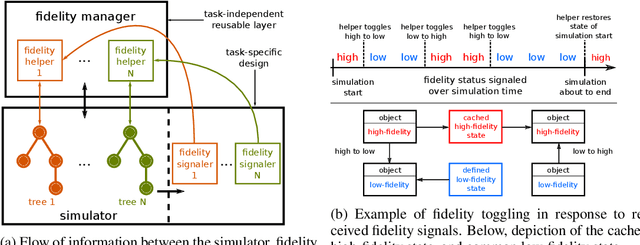

Simulators are an important tool in robotics that is used to develop robot software and generate synthetic data for machine learning algorithms. Faster simulation can result in better software validation and larger amounts of data. Previous efforts for speeding up simulators have been performed at the level of simulator building blocks, and robot systems. Our key insight, motivating this work, is that further speedups can be obtained at the level of the robot task. Building on the observation that not all parts of a scene need to be simulated in high fidelity at all times, our approach is to toggle between high- and low-fidelity states for scene objects in a task-informed manner. Our contribution is a framework for speeding up robot simulation by exploiting task knowledge. The framework is agnostic to the underlying simulator, and preserves simulation fidelity. As a case study, we consider a complex material-handling task. For the associated simulation, which contains many of the characteristics that make robot simulation slow, we achieve a speedup that can be up to three times faster than high fidelity without compromising on the quality of the results. We also demonstrate that faster simulation allows us to train better policies for performing the task at hand in a short period of time. A video summarizing our contributions can be found at https://youtu.be/PEzypDyqc3o .
Planning, Learning and Reasoning Framework for Robot Truck Unloading
Oct 21, 2019
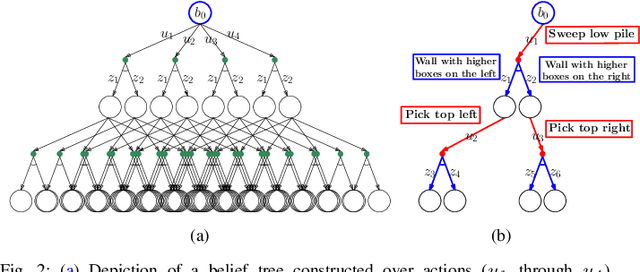
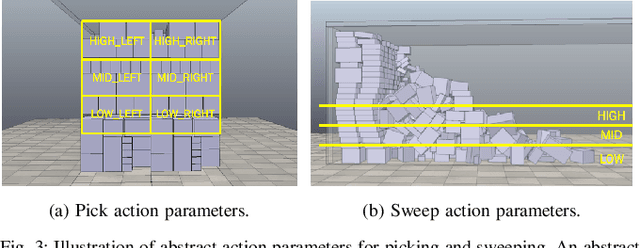
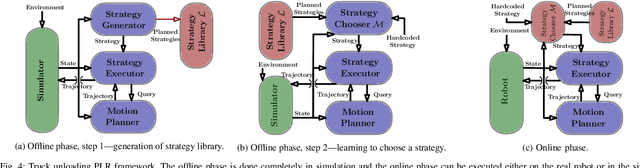
We consider the task of autonomously unloading boxes from trucks using an industrial manipulator robot. There are multiple challenges that arise: (1) real-time motion planning for a complex robotic system carrying two articulated mechanisms, an arm and a scooper, (2) decision-making in terms of what action to execute next given imperfect information about boxes such as their masses, (3) accounting for the sequential nature of the problem where current actions affect future state of the boxes, and (4) real-time execution that interleaves high-level decision-making with lower level motion planning. In this work, we propose a planning, learning, and reasoning framework to tackle these challenges, and describe its components including motion planning, belief space planning for offline learning, online decision-making based on offline learning, and an execution module to combine decision-making with motion planning. We analyze the performance of the framework on real-world scenarios. In particular, motion planning and execution modules are evaluated in simulation and on a real robot, while offline learning and online decision-making are evaluated in simulated real-world scenarios.
Bi-directional Value Learning for Risk-aware Planning Under Uncertainty: Extended Version
Apr 06, 2019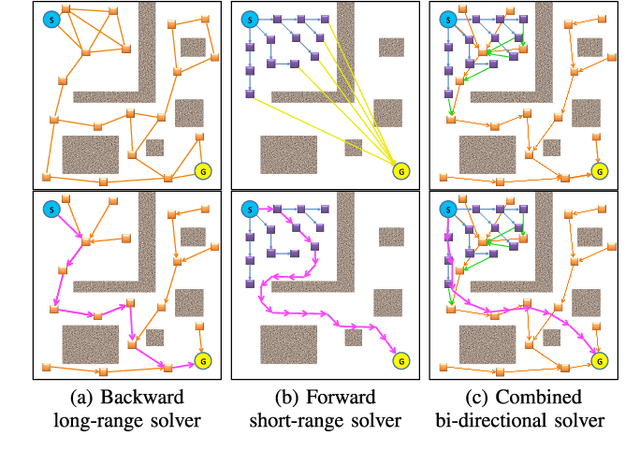
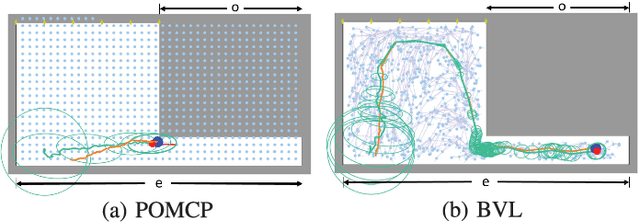
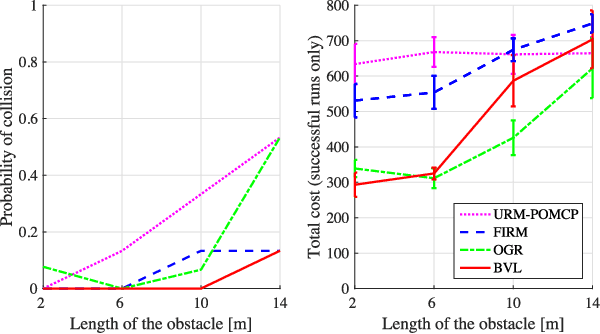
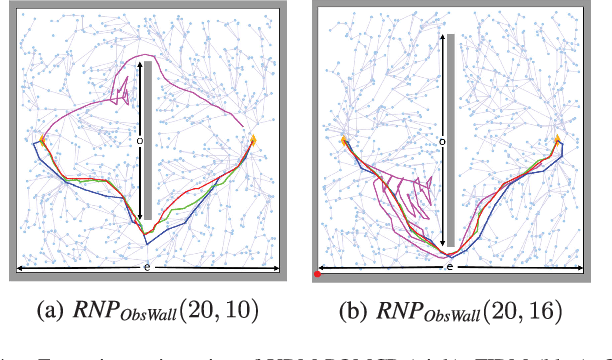
Decision-making under uncertainty is a crucial ability for autonomous systems. In its most general form, this problem can be formulated as a Partially Observable Markov Decision Process (POMDP). The solution policy of a POMDP can be implicitly encoded as a value function. In partially observable settings, the value function is typically learned via forward simulation of the system evolution. Focusing on accurate and long-range risk assessment, we propose a novel method, where the value function is learned in different phases via a bi-directional search in belief space. A backward value learning process provides a long-range and risk-aware base policy. A forward value learning process ensures local optimality and updates the policy via forward simulations. We consider a class of scalable and continuous-space rover navigation problems (RNP) to assess the safety, scalability, and optimality of the proposed algorithm. The results demonstrate the capabilities of the proposed algorithm in evaluating long-range risk/safety of the planner while addressing continuous problems with long planning horizons.
SLAP: Simultaneous Localization and Planning Under Uncertainty for Physical Mobile Robots via Dynamic Replanning in Belief Space: Extended version
May 13, 2018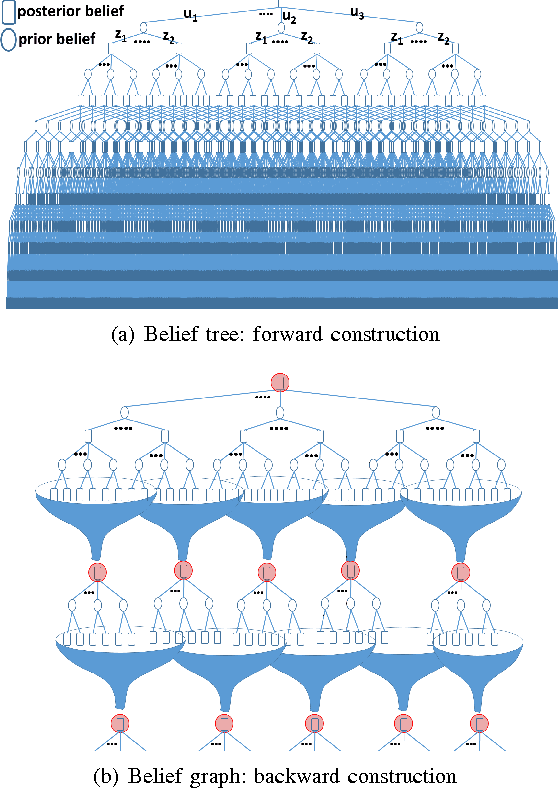
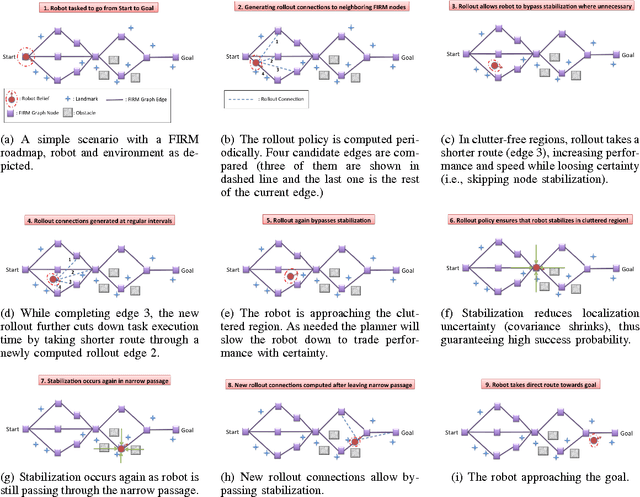
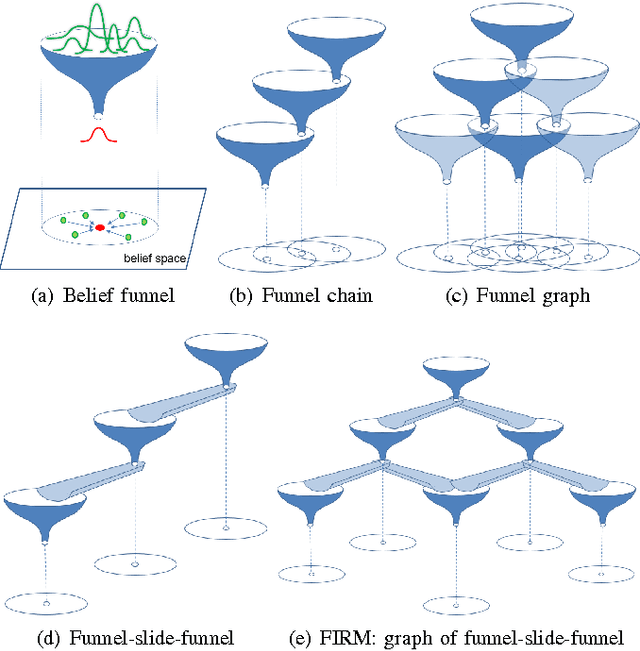
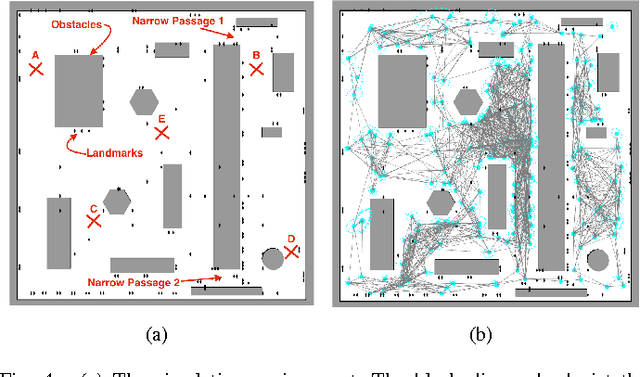
Simultaneous localization and Planning (SLAP) is a crucial ability for an autonomous robot operating under uncertainty. In its most general form, SLAP induces a continuous POMDP (partially-observable Markov decision process), which needs to be repeatedly solved online. This paper addresses this problem and proposes a dynamic replanning scheme in belief space. The underlying POMDP, which is continuous in state, action, and observation space, is approximated offline via sampling-based methods, but operates in a replanning loop online to admit local improvements to the coarse offline policy. This construct enables the proposed method to combat changing environments and large localization errors, even when the change alters the homotopy class of the optimal trajectory. It further outperforms the state-of-the-art FIRM (Feedback-based Information RoadMap) method by eliminating unnecessary stabilization steps. Applying belief space planning to physical systems brings with it a plethora of challenges. A key focus of this paper is to implement the proposed planner on a physical robot and show the SLAP solution performance under uncertainty, in changing environments and in the presence of large disturbances, such as a kidnapped robot situation.