 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Quest for Efficient Reasoning: A Data-Centric Benchmark to CoT Distillation
May 24, 2025Data-centric distillation, including data augmentation, selection, and mixing, offers a promising path to creating smaller, more efficient student Large Language Models (LLMs) that retain strong reasoning abilities. However, there still lacks a comprehensive benchmark to systematically assess the effect of each distillation approach. This paper introduces DC-CoT, the first data-centric benchmark that investigates data manipulation in chain-of-thought (CoT) distillation from method, model and data perspectives. Utilizing various teacher models (e.g., o4-mini, Gemini-Pro, Claude-3.5) and student architectures (e.g., 3B, 7B parameters), we rigorously evaluate the impact of these data manipulations on student model performance across multiple reasoning datasets, with a focus on in-distribution (IID) and out-of-distribution (OOD) generalization, and cross-domain transfer. Our findings aim to provide actionable insights and establish best practices for optimizing CoT distillation through data-centric techniques, ultimately facilitating the development of more accessible and capable reasoning models. The dataset can be found at https://huggingface.co/datasets/rana-shahroz/DC-COT, while our code is shared in https://anonymous.4open.science/r/DC-COT-FF4C/.
MAPLE: Many-Shot Adaptive Pseudo-Labeling for In-Context Learning
May 22, 2025In-Context Learning (ICL) empowers Large Language Models (LLMs) to tackle diverse tasks by incorporating multiple input-output examples, known as demonstrations, into the input of LLMs. More recently, advancements in the expanded context windows of LLMs have led to many-shot ICL, which uses hundreds of demonstrations and outperforms few-shot ICL, which relies on fewer examples. However, this approach is often hindered by the high cost of obtaining large amounts of labeled data. To address this challenge, we propose Many-Shot Adaptive Pseudo-LabEling, namely MAPLE, a novel influence-based many-shot ICL framework that utilizes pseudo-labeled samples to compensate for the lack of label information. We first identify a subset of impactful unlabeled samples and perform pseudo-labeling on them by querying LLMs. These pseudo-labeled samples are then adaptively selected and tailored to each test query as input to improve the performance of many-shot ICL, without significant labeling costs. Extensive experiments on real-world datasets demonstrate the effectiveness of our framework, showcasing its ability to enhance LLM adaptability and performance with limited labeled data.
Plan and Budget: Effective and Efficient Test-Time Scaling on Large Language Model Reasoning
May 22, 2025



Large Language Models (LLMs) have achieved remarkable success in complex reasoning tasks, but their inference remains computationally inefficient. We observe a common failure mode in many prevalent LLMs, overthinking, where models generate verbose and tangential reasoning traces even for simple queries. Recent works have tried to mitigate this by enforcing fixed token budgets, however, this can lead to underthinking, especially on harder problems. Through empirical analysis, we identify that this inefficiency often stems from unclear problem-solving strategies. To formalize this, we develop a theoretical model, BBAM (Bayesian Budget Allocation Model), which models reasoning as a sequence of sub-questions with varying uncertainty, and introduce the $E^3$ metric to capture the trade-off between correctness and computation efficiency. Building on theoretical results from BBAM, we propose Plan-and-Budget, a model-agnostic, test-time framework that decomposes complex queries into sub-questions and allocates token budgets based on estimated complexity using adaptive scheduling. Plan-and-Budget improves reasoning efficiency across a range of tasks and models, achieving up to +70% accuracy gains, -39% token reduction, and +187.5% improvement in $E^3$. Notably, it elevates a smaller model (DS-Qwen-32B) to match the efficiency of a larger model (DS-LLaMA-70B)-demonstrating Plan-and-Budget's ability to close performance gaps without retraining. Our code is available at anonymous.4open.science/r/P-and-B-6513/.
Physics-Driven Local-Whole Elastic Deformation Modeling for Point Cloud Representation Learning
May 20, 2025Existing point cloud representation learning tend to learning the geometric distribution of objects through data-driven approaches, emphasizing structural features while overlooking the relationship between the local information and the whole structure. Local features reflect the fine-grained variations of an object, while the whole structure is determined by the interaction and combination of these local features, collectively defining the object's shape. In real-world, objects undergo elastic deformation under external forces, and this deformation gradually affects the whole structure through the propagation of forces from local regions, thereby altering the object's geometric properties. Inspired by this, we propose a physics-driven self-supervised learning method for point cloud representation, which captures the relationship between parts and the whole by constructing a local-whole force propagation mechanism. Specifically, we employ a dual-task encoder-decoder framework, integrating the geometric modeling capability of implicit fields with physics-driven elastic deformation. The encoder extracts features from the point cloud and its tetrahedral mesh representation, capturing both geometric and physical properties. These features are then fed into two decoders: one learns the whole geometric shape of the point cloud through an implicit field, while the other predicts local deformations using two specifically designed physics information loss functions, modeling the deformation relationship between local and whole shapes. Experimental results show that our method outperforms existing approaches in object classification, few-shot learning, and segmentation, demonstrating its effectiveness.
MPRM: A Markov Path-based Rule Miner for Efficient and Interpretable Knowledge Graph Reasoning
May 18, 2025Rule mining in knowledge graphs enables interpretable link prediction. However, deep learning-based rule mining methods face significant memory and time challenges for large-scale knowledge graphs, whereas traditional approaches, limited by rigid confidence metrics, incur high computational costs despite sampling techniques. To address these challenges, we propose MPRM, a novel rule mining method that models rule-based inference as a Markov chain and uses an efficient confidence metric derived from aggregated path probabilities, significantly lowering computational demands. Experiments on multiple datasets show that MPRM efficiently mines knowledge graphs with over a million facts, sampling less than 1% of facts on a single CPU in 22 seconds, while preserving interpretability and boosting inference accuracy by up to 11% over baselines.
DPSeg: Dual-Prompt Cost Volume Learning for Open-Vocabulary Semantic Segmentation
May 16, 2025Open-vocabulary semantic segmentation aims to segment images into distinct semantic regions for both seen and unseen categories at the pixel level. Current methods utilize text embeddings from pre-trained vision-language models like CLIP but struggle with the inherent domain gap between image and text embeddings, even after extensive alignment during training. Additionally, relying solely on deep text-aligned features limits shallow-level feature guidance, which is crucial for detecting small objects and fine details, ultimately reducing segmentation accuracy. To address these limitations, we propose a dual prompting framework, DPSeg, for this task. Our approach combines dual-prompt cost volume generation, a cost volume-guided decoder, and a semantic-guided prompt refinement strategy that leverages our dual prompting scheme to mitigate alignment issues in visual prompt generation. By incorporating visual embeddings from a visual prompt encoder, our approach reduces the domain gap between text and image embeddings while providing multi-level guidance through shallow features. Extensive experiments demonstrate that our method significantly outperforms existing state-of-the-art approaches on multiple public datasets.
Uncertainty-Aware Large Language Models for Explainable Disease Diagnosis
May 06, 2025



Explainable disease diagnosis, which leverages patient information (e.g., signs and symptoms) and computational models to generate probable diagnoses and reasonings, offers clear clinical values. However, when clinical notes encompass insufficient evidence for a definite diagnosis, such as the absence of definitive symptoms, diagnostic uncertainty usually arises, increasing the risk of misdiagnosis and adverse outcomes. Although explicitly identifying and explaining diagnostic uncertainties is essential for trustworthy diagnostic systems, it remains under-explored. To fill this gap, we introduce ConfiDx, an uncertainty-aware large language model (LLM) created by fine-tuning open-source LLMs with diagnostic criteria. We formalized the task and assembled richly annotated datasets that capture varying degrees of diagnostic ambiguity. Evaluating ConfiDx on real-world datasets demonstrated that it excelled in identifying diagnostic uncertainties, achieving superior diagnostic performance, and generating trustworthy explanations for diagnoses and uncertainties. To our knowledge, this is the first study to jointly address diagnostic uncertainty recognition and explanation, substantially enhancing the reliability of automatic diagnostic systems.
PointLoRA: Low-Rank Adaptation with Token Selection for Point Cloud Learning
Apr 22, 2025



Self-supervised representation learning for point cloud has demonstrated effectiveness in improving pre-trained model performance across diverse tasks. However, as pre-trained models grow in complexity, fully fine-tuning them for downstream applications demands substantial computational and storage resources. Parameter-efficient fine-tuning (PEFT) methods offer a promising solution to mitigate these resource requirements, yet most current approaches rely on complex adapter and prompt mechanisms that increase tunable parameters. In this paper, we propose PointLoRA, a simple yet effective method that combines low-rank adaptation (LoRA) with multi-scale token selection to efficiently fine-tune point cloud models. Our approach embeds LoRA layers within the most parameter-intensive components of point cloud transformers, reducing the need for tunable parameters while enhancing global feature capture. Additionally, multi-scale token selection extracts critical local information to serve as prompts for downstream fine-tuning, effectively complementing the global context captured by LoRA. The experimental results across various pre-trained models and three challenging public datasets demonstrate that our approach achieves competitive performance with only 3.43% of the trainable parameters, making it highly effective for resource-constrained applications. Source code is available at: https://github.com/songw-zju/PointLoRA.
Acquire and then Adapt: Squeezing out Text-to-Image Model for Image Restoration
Apr 21, 2025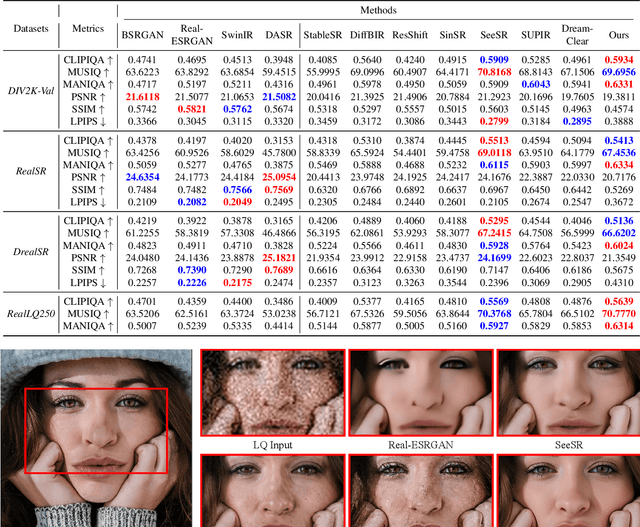
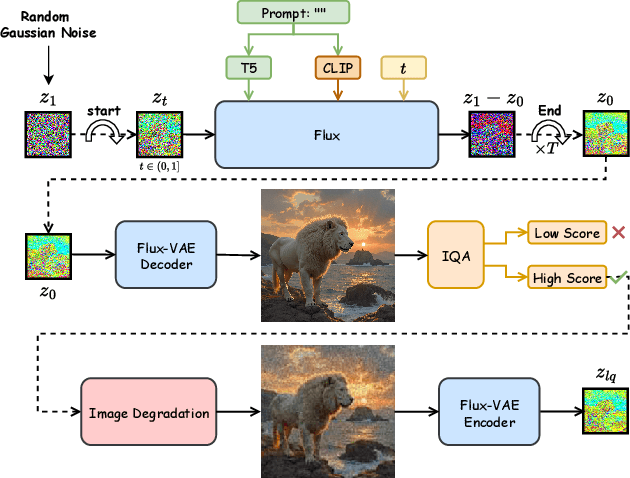
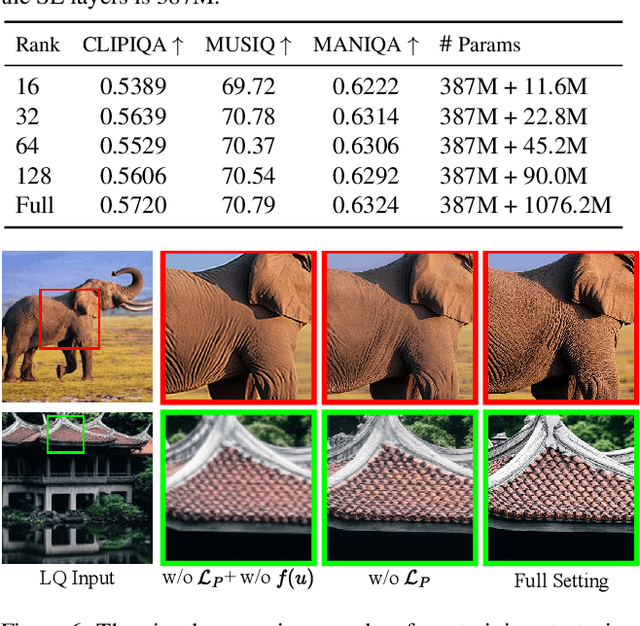
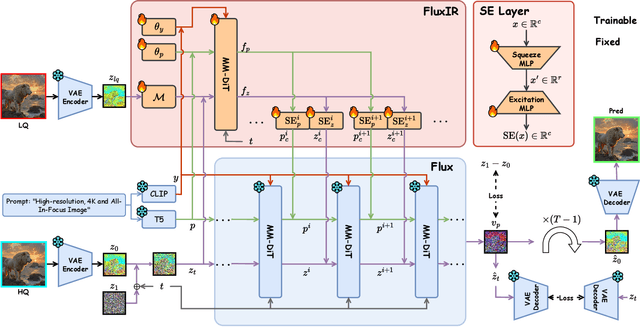
Recently, pre-trained text-to-image (T2I) models have been extensively adopted for real-world image restoration because of their powerful generative prior. However, controlling these large models for image restoration usually requires a large number of high-quality images and immense computational resources for training, which is costly and not privacy-friendly. In this paper, we find that the well-trained large T2I model (i.e., Flux) is able to produce a variety of high-quality images aligned with real-world distributions, offering an unlimited supply of training samples to mitigate the above issue. Specifically, we proposed a training data construction pipeline for image restoration, namely FluxGen, which includes unconditional image generation, image selection, and degraded image simulation. A novel light-weighted adapter (FluxIR) with squeeze-and-excitation layers is also carefully designed to control the large Diffusion Transformer (DiT)-based T2I model so that reasonable details can be restored. Experiments demonstrate that our proposed method enables the Flux model to adapt effectively to real-world image restoration tasks, achieving superior scores and visual quality on both synthetic and real-world degradation datasets - at only about 8.5\% of the training cost compared to current approaches.
Efficient MAP Estimation of LLM Judgment Performance with Prior Transfer
Apr 17, 2025



LLM ensembles are widely used for LLM judges. However, how to estimate their accuracy, especially in an efficient way, is unknown. In this paper, we present a principled maximum a posteriori (MAP) framework for an economical and precise estimation of the performance of LLM ensemble judgment. We first propose a mixture of Beta-Binomial distributions to model the judgment distribution, revising from the vanilla Binomial distribution. Next, we introduce a conformal prediction-driven approach that enables adaptive stopping during iterative sampling to balance accuracy with efficiency. Furthermore, we design a prior transfer mechanism that utilizes learned distributions on open-source datasets to improve estimation on a target dataset when only scarce annotations are available. Finally, we present BetaConform, a framework that integrates our distribution assumption, adaptive stopping, and the prior transfer mechanism to deliver a theoretically guaranteed distribution estimation of LLM ensemble judgment with minimum labeled samples. BetaConform is also validated empirically. For instance, with only 10 samples from the TruthfulQA dataset, for a Llama ensembled judge, BetaConform gauges its performance with error margin as small as 3.37%.