 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
VisualLens: Personalization through Visual History
Nov 25, 2024



We hypothesize that a user's visual history with images reflecting their daily life, offers valuable insights into their interests and preferences, and can be leveraged for personalization. Among the many challenges to achieve this goal, the foremost is the diversity and noises in the visual history, containing images not necessarily related to a recommendation task, not necessarily reflecting the user's interest, or even not necessarily preference-relevant. Existing recommendation systems either rely on task-specific user interaction logs, such as online shopping history for shopping recommendations, or focus on text signals. We propose a novel approach, VisualLens, that extracts, filters, and refines image representations, and leverages these signals for personalization. We created two new benchmarks with task-agnostic visual histories, and show that our method improves over state-of-the-art recommendations by 5-10% on Hit@3, and improves over GPT-4o by 2-5%. Our approach paves the way for personalized recommendations in scenarios where traditional methods fail.
CoDi: Conversational Distillation for Grounded Question Answering
Aug 20, 2024



Distilling conversational skills into Small Language Models (SLMs) with approximately 1 billion parameters presents significant challenges. Firstly, SLMs have limited capacity in their model parameters to learn extensive knowledge compared to larger models. Secondly, high-quality conversational datasets are often scarce, small, and domain-specific. Addressing these challenges, we introduce a novel data distillation framework named CoDi (short for Conversational Distillation, pronounced "Cody"), allowing us to synthesize large-scale, assistant-style datasets in a steerable and diverse manner. Specifically, while our framework is task agnostic at its core, we explore and evaluate the potential of CoDi on the task of conversational grounded reasoning for question answering. This is a typical on-device scenario for specialist SLMs, allowing for open-domain model responses, without requiring the model to "memorize" world knowledge in its limited weights. Our evaluations show that SLMs trained with CoDi-synthesized data achieve performance comparable to models trained on human-annotated data in standard metrics. Additionally, when using our framework to generate larger datasets from web data, our models surpass larger, instruction-tuned models in zero-shot conversational grounded reasoning tasks.
On the Equivalence of Graph Convolution and Mixup
Sep 29, 2023



This paper investigates the relationship between graph convolution and Mixup techniques. Graph convolution in a graph neural network involves aggregating features from neighboring samples to learn representative features for a specific node or sample. On the other hand, Mixup is a data augmentation technique that generates new examples by averaging features and one-hot labels from multiple samples. One commonality between these techniques is their utilization of information from multiple samples to derive feature representation. This study aims to explore whether a connection exists between these two approaches. Our investigation reveals that, under two mild conditions, graph convolution can be viewed as a specialized form of Mixup that is applied during both the training and testing phases. The two conditions are: 1) \textit{Homophily Relabel} - assigning the target node's label to all its neighbors, and 2) \textit{Test-Time Mixup} - Mixup the feature during the test time. We establish this equivalence mathematically by demonstrating that graph convolution networks (GCN) and simplified graph convolution (SGC) can be expressed as a form of Mixup. We also empirically verify the equivalence by training an MLP using the two conditions to achieve comparable performance.
Meta-training with Demonstration Retrieval for Efficient Few-shot Learning
Jun 30, 2023



Large language models show impressive results on few-shot NLP tasks. However, these models are memory and computation-intensive. Meta-training allows one to leverage smaller models for few-shot generalization in a domain-general and task-agnostic manner; however, these methods alone results in models that may not have sufficient parameterization or knowledge to adapt quickly to a large variety of tasks. To overcome this issue, we propose meta-training with demonstration retrieval, where we use a dense passage retriever to retrieve semantically similar labeled demonstrations to each example for more varied supervision. By separating external knowledge from model parameters, we can use meta-training to train parameter-efficient models that generalize well on a larger variety of tasks. We construct a meta-training set from UnifiedQA and CrossFit, and propose a demonstration bank based on UnifiedQA tasks. To our knowledge, our work is the first to combine retrieval with meta-training, to use DPR models to retrieve demonstrations, and to leverage demonstrations from many tasks simultaneously, rather than randomly sampling demonstrations from the training set of the target task. Our approach outperforms a variety of targeted parameter-efficient and retrieval-augmented few-shot methods on QA, NLI, and text classification tasks (including SQuAD, QNLI, and TREC). Our approach can be meta-trained and fine-tuned quickly on a single GPU.
Understanding Failure Modes of Self-Supervised Learning
Mar 03, 2022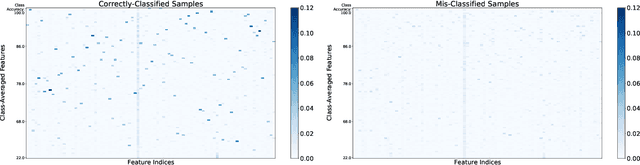
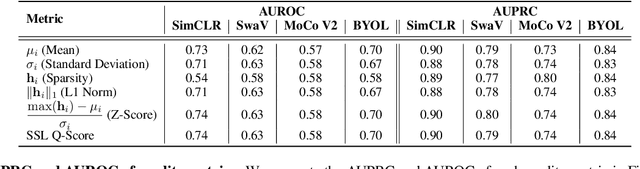
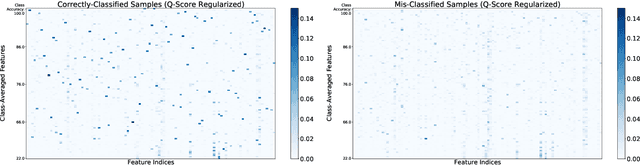
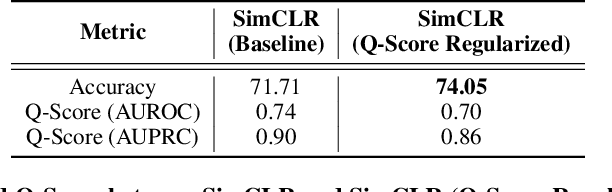
Self-supervised learning methods have shown impressive results in downstream classification tasks. However, there is limited work in understanding their failure models and interpreting the learned representations of these models. In this paper, we tackle these issues and study the representation space of self-supervised models by understanding the underlying reasons for misclassifications in a downstream task. Over several state-of-the-art self-supervised models including SimCLR, SwaV, MoCo V2 and BYOL, we observe that representations of correctly classified samples have few discriminative features with highly deviated values compared to other features. This is in a clear contrast with representations of misclassified samples. We also observe that noisy features in the representation space often correspond to spurious attributes in images making the models less interpretable. Building on these observations, we propose a sample-wise Self-Supervised Representation Quality Score (or, Q-Score) that, without access to any label information, is able to predict if a given sample is likely to be misclassified in the downstream task, achieving an AUPRC of up to 0.90. Q-Score can also be used as a regularization to remedy low-quality representations leading to 3.26% relative improvement in accuracy of SimCLR on ImageNet-100. Moreover, we show that Q-Score regularization increases representation sparsity, thus reducing noise and improving interpretability through gradient heatmaps.
An Induced Multi-Relational Framework for Answer Selection in Community Question Answer Platforms
Nov 16, 2019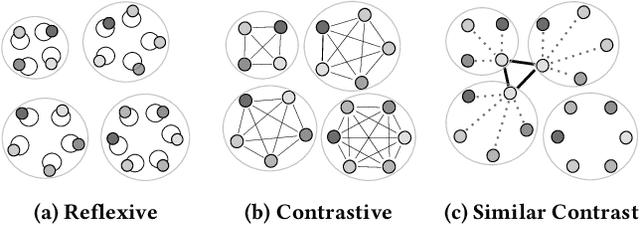

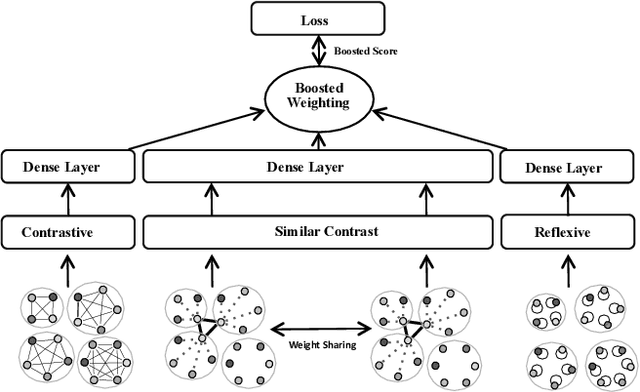
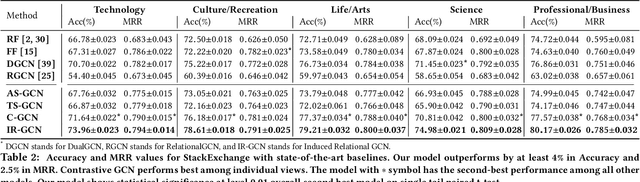
This paper addresses the question of identifying the best candidate answer to a question on Community Question Answer (CQA) forums. The problem is important because Individuals often visit CQA forums to seek answers to nuanced questions. We develop a novel induced relational graph convolutional network (IR-GCN) framework to address the question. We make three contributions. First, we introduce a modular framework that separates the construction of the graph with the label selection mechanism. We use equivalence relations to induce a graph comprising cliques and identify two label assignment mechanisms---label contrast, label sharing. Then, we show how to encode these assignment mechanisms in GCNs. Second, we show that encoding contrast creates discriminative magnification---enhancing the separation between nodes in the embedding space. Third, we show a surprising result---boosting techniques improve learning over familiar stacking, fusion, or aggregation approaches for neural architectures. We show strong results over the state-of-the-art neural baselines in extensive experiments on 50 StackExchange communities.