 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSE: A New Dataset for Video Object Segmentation in Complex Scenes
Feb 03, 2023Video object segmentation (VOS) aims at segmenting a particular object throughout the entire video clip sequence. The state-of-the-art VOS methods have achieved excellent performance (e.g., 90+% J&F) on existing datasets. However, since the target objects in these existing datasets are usually relatively salient, dominant, and isolated, VOS under complex scenes has rarely been studied. To revisit VOS and make it more applicable in the real world, we collect a new VOS dataset called coMplex video Object SEgmentation (MOSE) to study the tracking and segmenting objects in complex environments. MOSE contains 2,149 video clips and 5,200 objects from 36 categories, with 431,725 high-quality object segmentation masks. The most notable feature of MOSE dataset is complex scenes with crowded and occluded objects. The target objects in the videos are commonly occluded by others and disappear in some frames. To analyze the proposed MOSE dataset, we benchmark 18 existing VOS methods under 4 different settings on the proposed MOSE dataset and conduct comprehensive comparisons. The experiments show that current VOS algorithms cannot well perceive objects in complex scenes. For example, under the semi-supervised VOS setting, the highest J&F by existing state-of-the-art VOS methods is only 59.4% on MOSE, much lower than their ~90% J&F performance on DAVIS. The results reveal that although excellent performance has been achieved on existing benchmarks, there are unresolved challenges under complex scenes and more efforts are desired to explore these challenges in the future. The proposed MOSE dataset has been released at https://henghuiding.github.io/MOSE.
PV3D: A 3D Generative Model for Portrait Video Generation
Dec 13, 2022



Recent advances in generative adversarial networks (GANs) have demonstrated the capabilities of generating stunning photo-realistic portrait images. While some prior works have applied such image GANs to unconditional 2D portrait video generation and static 3D portrait synthesis, there are few works successfully extending GANs for generating 3D-aware portrait videos. In this work, we propose PV3D, the first generative framework that can synthesize multi-view consistent portrait videos. Specifically, our method extends the recent static 3D-aware image GAN to the video domain by generalizing the 3D implicit neural representation to model the spatio-temporal space. To introduce motion dynamics to the generation process, we develop a motion generator by stacking multiple motion layers to generate motion features via modulated convolution. To alleviate motion ambiguities caused by camera/human motions, we propose a simple yet effective camera condition strategy for PV3D, enabling both temporal and multi-view consistent video generation. Moreover, PV3D introduces two discriminators for regularizing the spatial and temporal domains to ensure the plausibility of the generated portrait videos. These elaborated designs enable PV3D to generate 3D-aware motion-plausible portrait videos with high-quality appearance and geometry, significantly outperforming prior works. As a result, PV3D is able to support many downstream applications such as animating static portraits and view-consistent video motion editing. Code and models will be released at https://showlab.github.io/pv3d.
Language-driven Open-Vocabulary 3D Scene Understanding
Nov 29, 2022



Open-vocabulary scene understanding aims to localize and recognize unseen categories beyond the annotated label space. The recent breakthrough of 2D open-vocabulary perception is largely driven by Internet-scale paired image-text data with rich vocabulary concepts. However, this success cannot be directly transferred to 3D scenarios due to the inaccessibility of large-scale 3D-text pairs. To this end, we propose to distill knowledge encoded in pre-trained vision-language (VL) foundation models through captioning multi-view images from 3D, which allows explicitly associating 3D and semantic-rich captions. Further, to facilitate coarse-to-fine visual-semantic representation learning from captions, we design hierarchical 3D-caption pairs, leveraging geometric constraints between 3D scenes and multi-view images. Finally, by employing contrastive learning, the model learns language-aware embeddings that connect 3D and text for open-vocabulary tasks. Our method not only remarkably outperforms baseline methods by 25.8% $\sim$ 44.7% hIoU and 14.5% $\sim$ 50.4% hAP$_{50}$ on open-vocabulary semantic and instance segmentation, but also shows robust transferability on challenging zero-shot domain transfer tasks. Code will be available at https://github.com/CVMI-Lab/PLA.
LUMix: Improving Mixup by Better Modelling Label Uncertainty
Nov 29, 2022



Modern deep networks can be better generalized when trained with noisy samples and regularization techniques. Mixup and CutMix have been proven to be effective for data augmentation to help avoid overfitting. Previous Mixup-based methods linearly combine images and labels to generate additional training data. However, this is problematic if the object does not occupy the whole image as we demonstrate in Figure 1. Correctly assigning the label weights is hard even for human beings and there is no clear criterion to measure it. To tackle this problem, in this paper, we propose LUMix, which models such uncertainty by adding label perturbation during training. LUMix is simple as it can be implemented in just a few lines of code and can be universally applied to any deep networks \eg CNNs and Vision Transformers, with minimal computational cost. Extensive experiments show that our LUMix can consistently boost the performance for networks with a wide range of diversity and capacity on ImageNet, \eg $+0.7\%$ for a small model DeiT-S and $+0.6\%$ for a large variant XCiT-L. We also demonstrate that LUMix can lead to better robustness when evaluated on ImageNet-O and ImageNet-A. The source code can be found \href{https://github.com/kevin-ssy/LUMix}{here}
The Runner-up Solution for YouTube-VIS Long Video Challenge 2022
Nov 18, 2022This technical report describes our 2nd-place solution for the ECCV 2022 YouTube-VIS Long Video Challenge. We adopt the previously proposed online video instance segmentation method IDOL for this challenge. In addition, we use pseudo labels to further help contrastive learning, so as to obtain more temporally consistent instance embedding to improve tracking performance between frames. The proposed method obtains 40.2 AP on the YouTube-VIS 2022 long video dataset and was ranked second place in this challenge. We hope our simple and effective method could benefit further research.
Holistically-Attracted Wireframe Parsing: From Supervised to Self-Supervised Learning
Oct 24, 2022This paper presents Holistically-Attracted Wireframe Parsing (HAWP) for 2D images using both fully supervised and self-supervised learning paradigms. At the core is a parsimonious representation that encodes a line segment using a closed-form 4D geometric vector, which enables lifting line segments in wireframe to an end-to-end trainable holistic attraction field that has built-in geometry-awareness, context-awareness and robustness. The proposed HAWP consists of three components: generating line segment and end-point proposal, binding line segment and end-point, and end-point-decoupled lines-of-interest verification. For self-supervised learning, a simulation-to-reality pipeline is exploited in which a HAWP is first trained using synthetic data and then used to ``annotate" wireframes in real images with Homographic Adaptation. With the self-supervised annotations, a HAWP model for real images is trained from scratch. In experiments, the proposed HAWP achieves state-of-the-art performance in both the Wireframe dataset and the YorkUrban dataset in fully-supervised learning. It also demonstrates a significantly better repeatability score than prior arts with much more efficient training in self-supervised learning. Furthermore, the self-supervised HAWP shows great potential for general wireframe parsing without onerous wireframe labels.
Is synthetic data from generative models ready for image recognition?
Oct 14, 2022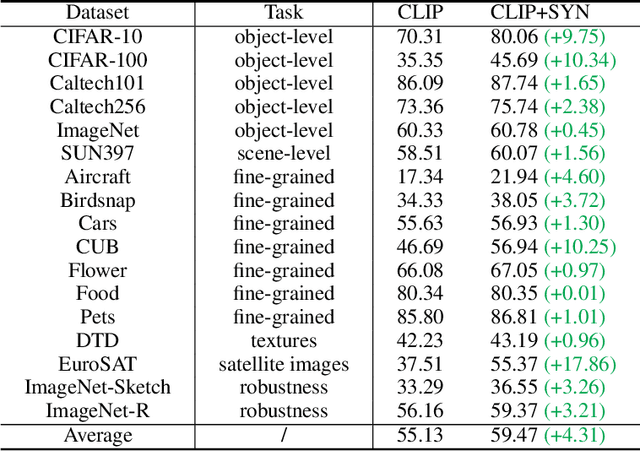
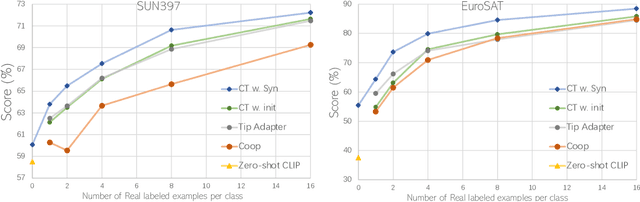
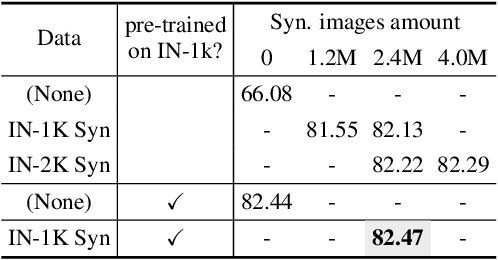

Recent text-to-image generation models have shown promising results in generating high-fidelity photo-realistic images. Though the results are astonishing to human eyes, how applicable these generated images are for recognition tasks remains under-explored. In this work, we extensively study whether and how synthetic images generated from state-of-the-art text-to-image generation models can be used for image recognition tasks, and focus on two perspectives: synthetic data for improving classification models in data-scarce settings (i.e. zero-shot and few-shot), and synthetic data for large-scale model pre-training for transfer learning. We showcase the powerfulness and shortcomings of synthetic data from existing generative models, and propose strategies for better applying synthetic data for recognition tasks. Code: https://github.com/CVMI-Lab/SyntheticData.
Towards Understanding and Mitigating Dimensional Collapse in Heterogeneous Federated Learning
Oct 01, 2022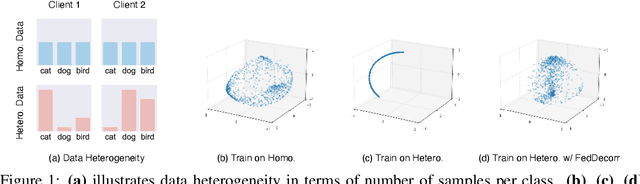
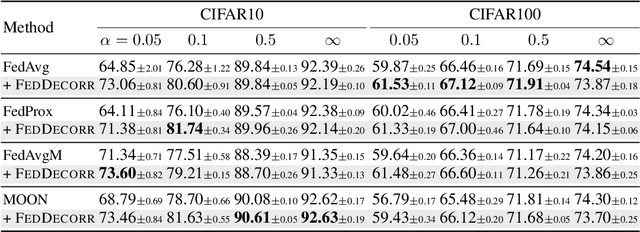
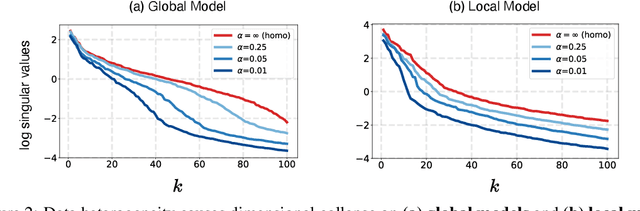
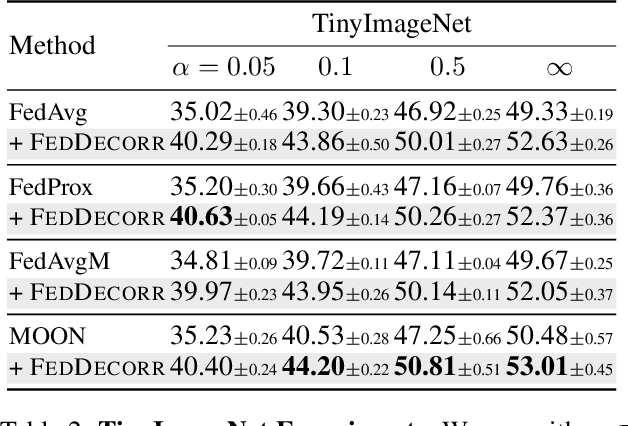
Federated learning aims to train models collaboratively across different clients without the sharing of data for privacy considerations. However, one major challenge for this learning paradigm is the {\em data heterogeneity} problem, which refers to the discrepancies between the local data distributions among various clients. To tackle this problem, we first study how data heterogeneity affects the representations of the globally aggregated models. Interestingly, we find that heterogeneous data results in the global model suffering from severe {\em dimensional collapse}, in which representations tend to reside in a lower-dimensional space instead of the ambient space. Moreover, we observe a similar phenomenon on models locally trained on each client and deduce that the dimensional collapse on the global model is inherited from local models. In addition, we theoretically analyze the gradient flow dynamics to shed light on how data heterogeneity result in dimensional collapse for local models. To remedy this problem caused by the data heterogeneity, we propose {\sc FedDecorr}, a novel method that can effectively mitigate dimensional collapse in federated learning. Specifically, {\sc FedDecorr} applies a regularization term during local training that encourages different dimensions of representations to be uncorrelated. {\sc FedDecorr}, which is implementation-friendly and computationally-efficient, yields consistent improvements over baselines on standard benchmark datasets. Code will be released.
1st Place Solution to ECCV 2022 Challenge on Out of Vocabulary Scene Text Understanding: Cropped Word Recognition
Aug 04, 2022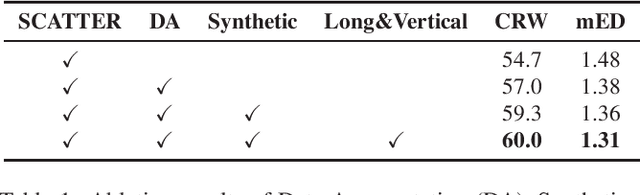

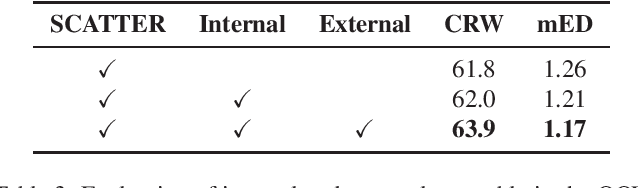

This report presents our winner solution to ECCV 2022 challenge on Out-of-Vocabulary Scene Text Understanding (OOV-ST) : Cropped Word Recognition. This challenge is held in the context of ECCV 2022 workshop on Text in Everything (TiE), which aims to extract out-of-vocabulary words from natural scene images. In the competition, we first pre-train SCATTER on the synthetic datasets, then fine-tune the model on the training set with data augmentations. Meanwhile, two additional models are trained specifically for long and vertical texts. Finally, we combine the output from different models with different layers, different backbones, and different seeds as the final results. Our solution achieves an overall word accuracy of 69.73% when considering both in-vocabulary and out-of-vocabulary words.
Explicit Occlusion Reasoning for Multi-person 3D Human Pose Estimation
Jul 29, 2022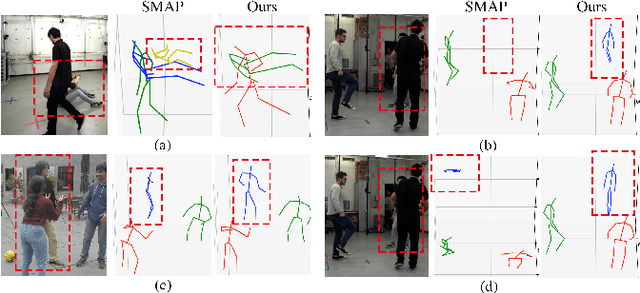
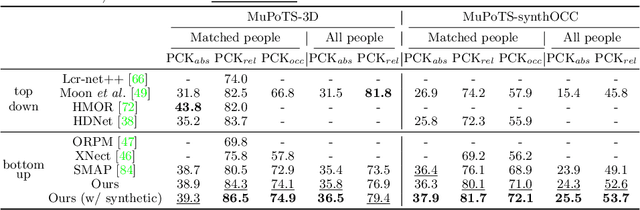
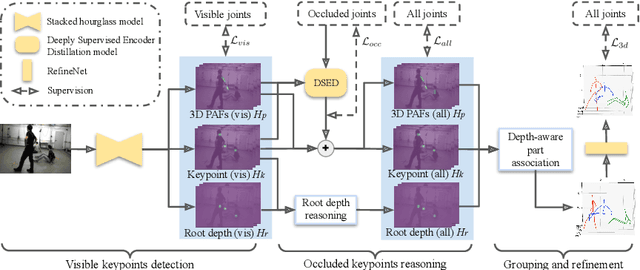

Occlusion poses a great threat to monocular multi-person 3D human pose estimation due to large variability in terms of the shape, appearance, and position of occluders. While existing methods try to handle occlusion with pose priors/constraints, data augmentation, or implicit reasoning, they still fail to generalize to unseen poses or occlusion cases and may make large mistakes when multiple people are present. Inspired by the remarkable ability of humans to infer occluded joints from visible cues, we develop a method to explicitly model this process that significantly improves bottom-up multi-person human pose estimation with or without occlusions. First, we split the task into two subtasks: visible keypoints detection and occluded keypoints reasoning, and propose a Deeply Supervised Encoder Distillation (DSED) network to solve the second one. To train our model, we propose a Skeleton-guided human Shape Fitting (SSF) approach to generate pseudo occlusion labels on the existing datasets, enabling explicit occlusion reasoning. Experiments show that explicitly learning from occlusions improves human pose estimation. In addition, exploiting feature-level information of visible joints allows us to reason about occluded joints more accurately. Our method outperforms both the state-of-the-art top-down and bottom-up methods on several benchmarks.