 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRainbow Delay Compensation: A Multi-Agent Reinforcement Learning Framework for Mitigating Delayed Observation
May 06, 2025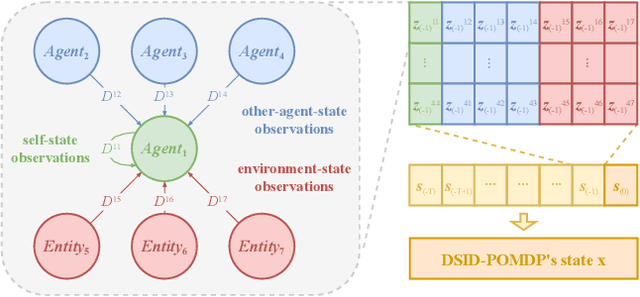

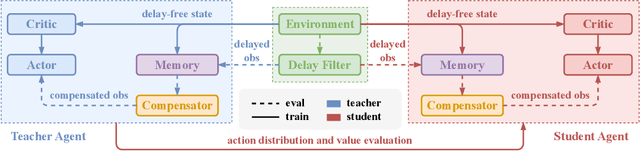
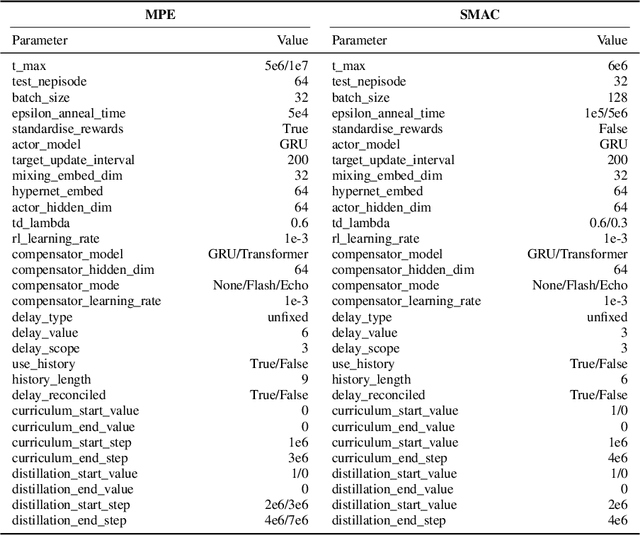
In real-world multi-agent systems (MASs), observation delays are ubiquitous, preventing agents from making decisions based on the environment's true state. An individual agent's local observation often consists of multiple components from other agents or dynamic entities in the environment. These discrete observation components with varying delay characteristics pose significant challenges for multi-agent reinforcement learning (MARL). In this paper, we first formulate the decentralized stochastic individual delay partially observable Markov decision process (DSID-POMDP) by extending the standard Dec-POMDP. We then propose the Rainbow Delay Compensation (RDC), a MARL training framework for addressing stochastic individual delays, along with recommended implementations for its constituent modules. We implement the DSID-POMDP's observation generation pattern using standard MARL benchmarks, including MPE and SMAC. Experiments demonstrate that baseline MARL methods suffer severe performance degradation under fixed and unfixed delays. The RDC-enhanced approach mitigates this issue, remarkably achieving ideal delay-free performance in certain delay scenarios while maintaining generalization capability. Our work provides a novel perspective on multi-agent delayed observation problems and offers an effective solution framework.
Efficient End-to-End 6-Dof Grasp Detection Framework for Edge Devices with Hierarchical Heatmaps and Feature Propagation
Oct 30, 2024



6-DoF grasp detection is critically important for the advancement of intelligent embodied systems, as it provides feasible robot poses for object grasping. Various methods have been proposed to detect 6-DoF grasps through the extraction of 3D geometric features from RGBD or point cloud data. However, most of these approaches encounter challenges during real robot deployment due to their significant computational demands, which can be particularly problematic for mobile robot platforms, especially those reliant on edge computing devices. This paper presents an Efficient End-to-End Grasp Detection Network (E3GNet) for 6-DoF grasp detection utilizing hierarchical heatmap representations. E3GNet effectively identifies high-quality and diverse grasps in cluttered real-world environments. Benefiting from our end-to-end methodology and efficient network design, our approach surpasses previous methods in model inference efficiency and achieves real-time 6-Dof grasp detection on edge devices. Furthermore, real-world experiments validate the effectiveness of our method, achieving a satisfactory 94% object grasping success rate.
GAP-RL: Grasps As Points for RL Towards Dynamic Object Grasping
Oct 04, 2024



Dynamic grasping of moving objects in complex, continuous motion scenarios remains challenging. Reinforcement Learning (RL) has been applied in various robotic manipulation tasks, benefiting from its closed-loop property. However, existing RL-based methods do not fully explore the potential for enhancing visual representations. In this letter, we propose a novel framework called Grasps As Points for RL (GAP-RL) to effectively and reliably grasp moving objects. By implementing a fast region-based grasp detector, we build a Grasp Encoder by transforming 6D grasp poses into Gaussian points and extracting grasp features as a higher-level abstraction than the original object point features. Additionally, we develop a Graspable Region Explorer for real-world deployment, which searches for consistent graspable regions, enabling smoother grasp generation and stable policy execution. To assess the performance fairly, we construct a simulated dynamic grasping benchmark involving objects with various complex motions. Experiment results demonstrate that our method effectively generalizes to novel objects and unseen dynamic motions compared to other baselines. Real-world experiments further validate the framework's sim-to-real transferability.
Target-Oriented Object Grasping via Multimodal Human Guidance
Aug 20, 2024



In the context of human-robot interaction and collaboration scenarios, robotic grasping still encounters numerous challenges. Traditional grasp detection methods generally analyze the entire scene to predict grasps, leading to redundancy and inefficiency. In this work, we reconsider 6-DoF grasp detection from a target-referenced perspective and propose a Target-Oriented Grasp Network (TOGNet). TOGNet specifically targets local, object-agnostic region patches to predict grasps more efficiently. It integrates seamlessly with multimodal human guidance, including language instructions, pointing gestures, and interactive clicks. Thus our system comprises two primary functional modules: a guidance module that identifies the target object in 3D space and TOGNet, which detects region-focal 6-DoF grasps around the target, facilitating subsequent motion planning. Through 50 target-grasping simulation experiments in cluttered scenes, our system achieves a success rate improvement of about 13.7%. In real-world experiments, we demonstrate that our method excels in various target-oriented grasping scenarios.
Region-aware Grasp Framework with Normalized Grasp Space for 6-DoF Grasping in Cluttered Scene
Jun 03, 2024



Regional geometric information is crucial for determining grasp poses. A series of region-based methods succeed in extracting regional features and enhancing grasp detection quality. However, faced with a cluttered scene with multiple objects and potential collision, the definition of the grasp-relevant region remains inconsistent among methods, and the relationship between grasps and regional spaces remains incompletely investigated. In this paper, from a novel region-aware and grasp-centric viewpoint, we propose Normalized Grasp Space (NGS), unifying the grasp representation within a normalized regional space. The relationship among the grasp widths, region scales, and gripper sizes is considered and empowers our method to generalize to grippers and scenes with different scales. Leveraging the characteristics of the NGS, we find that 2D CNNs are surprisingly underestimated for complicated 6-DoF grasp detection tasks in clutter scenes and build a highly efficient Region-aware Normalized Grasp Network (RNGNet). Experiments conducted on the public benchmark show that our method achieves the best grasp detection results compared to the previous state-of-the-arts while attaining a real-time inference speed of approximately 50 FPS. Real-world cluttered scene clearance experiments underscore the effectiveness of our method with a higher success rate than other methods. Further human-to-robot handover and moving object grasping experiments demonstrate the potential of our proposed method for closed-loop grasping in dynamic scenarios.
Part-Guided 3D RL for Sim2Real Articulated Object Manipulation
Apr 26, 2024



Manipulating unseen articulated objects through visual feedback is a critical but challenging task for real robots. Existing learning-based solutions mainly focus on visual affordance learning or other pre-trained visual models to guide manipulation policies, which face challenges for novel instances in real-world scenarios. In this paper, we propose a novel part-guided 3D RL framework, which can learn to manipulate articulated objects without demonstrations. We combine the strengths of 2D segmentation and 3D RL to improve the efficiency of RL policy training. To improve the stability of the policy on real robots, we design a Frame-consistent Uncertainty-aware Sampling (FUS) strategy to get a condensed and hierarchical 3D representation. In addition, a single versatile RL policy can be trained on multiple articulated object manipulation tasks simultaneously in simulation and shows great generalizability to novel categories and instances. Experimental results demonstrate the effectiveness of our framework in both simulation and real-world settings. Our code is available at https://github.com/THU-VCLab/Part-Guided-3D-RL-for-Sim2Real-Articulated-Object-Manipulation.
Efficient Heatmap-Guided 6-Dof Grasp Detection in Cluttered Scenes
Mar 27, 2024



Fast and robust object grasping in clutter is a crucial component of robotics. Most current works resort to the whole observed point cloud for 6-Dof grasp generation, ignoring the guidance information excavated from global semantics, thus limiting high-quality grasp generation and real-time performance. In this work, we show that the widely used heatmaps are underestimated in the efficiency of 6-Dof grasp generation. Therefore, we propose an effective local grasp generator combined with grasp heatmaps as guidance, which infers in a global-to-local semantic-to-point way. Specifically, Gaussian encoding and the grid-based strategy are applied to predict grasp heatmaps as guidance to aggregate local points into graspable regions and provide global semantic information. Further, a novel non-uniform anchor sampling mechanism is designed to improve grasp accuracy and diversity. Benefiting from the high-efficiency encoding in the image space and focusing on points in local graspable regions, our framework can perform high-quality grasp detection in real-time and achieve state-of-the-art results. In addition, real robot experiments demonstrate the effectiveness of our method with a success rate of 94% and a clutter completion rate of 100%. Our code is available at https://github.com/THU-VCLab/HGGD.
Rethinking 6-Dof Grasp Detection: A Flexible Framework for High-Quality Grasping
Mar 22, 2024Robotic grasping is a primitive skill for complex tasks and is fundamental to intelligence. For general 6-Dof grasping, most previous methods directly extract scene-level semantic or geometric information, while few of them consider the suitability for various downstream applications, such as target-oriented grasping. Addressing this issue, we rethink 6-Dof grasp detection from a grasp-centric view and propose a versatile grasp framework capable of handling both scene-level and target-oriented grasping. Our framework, FlexLoG, is composed of a Flexible Guidance Module and a Local Grasp Model. Specifically, the Flexible Guidance Module is compatible with both global (e.g., grasp heatmap) and local (e.g., visual grounding) guidance, enabling the generation of high-quality grasps across various tasks. The Local Grasp Model focuses on object-agnostic regional points and predicts grasps locally and intently. Experiment results reveal that our framework achieves over 18% and 23% improvement on unseen splits of the GraspNet-1Billion Dataset. Furthermore, real-world robotic tests in three distinct settings yield a 95% success rate.
Category-Agnostic Pose Estimation for Point Clouds
Mar 12, 2024



The goal of object pose estimation is to visually determine the pose of a specific object in the RGB-D input. Unfortunately, when faced with new categories, both instance-based and category-based methods are unable to deal with unseen objects of unseen categories, which is a challenge for pose estimation. To address this issue, this paper proposes a method to introduce geometric features for pose estimation of point clouds without requiring category information. The method is based only on the patch feature of the point cloud, a geometric feature with rotation invariance. After training without category information, our method achieves as good results as other category-based methods. Our method successfully achieved pose annotation of no category information instances on the CAMERA25 dataset and ModelNet40 dataset.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020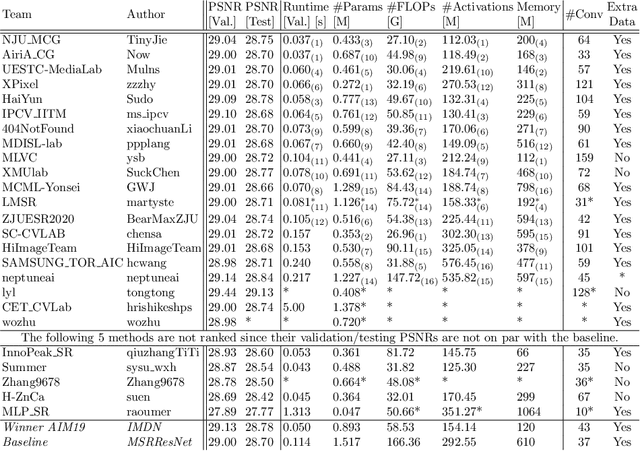
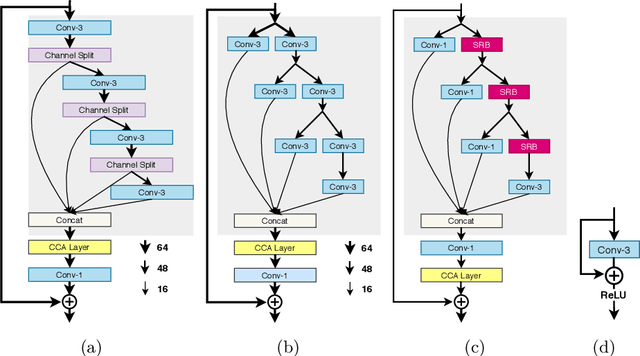
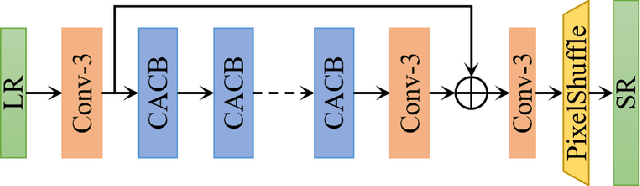
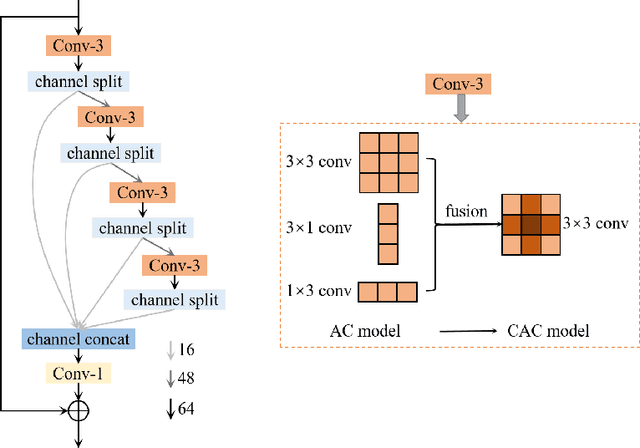
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.