 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRainbow Delay Compensation: A Multi-Agent Reinforcement Learning Framework for Mitigating Delayed Observation
May 06, 2025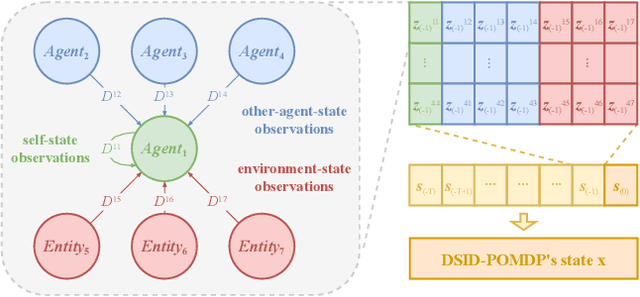

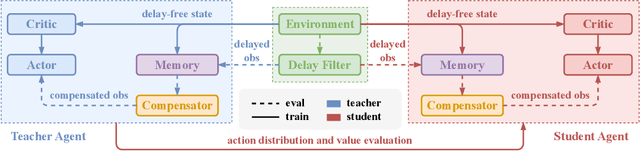
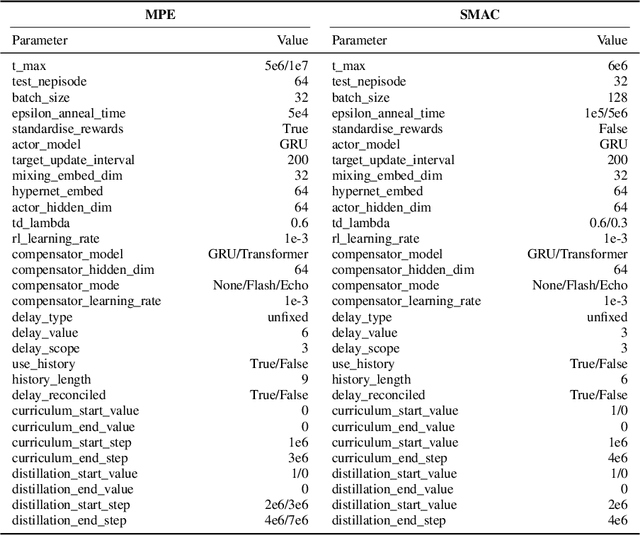
In real-world multi-agent systems (MASs), observation delays are ubiquitous, preventing agents from making decisions based on the environment's true state. An individual agent's local observation often consists of multiple components from other agents or dynamic entities in the environment. These discrete observation components with varying delay characteristics pose significant challenges for multi-agent reinforcement learning (MARL). In this paper, we first formulate the decentralized stochastic individual delay partially observable Markov decision process (DSID-POMDP) by extending the standard Dec-POMDP. We then propose the Rainbow Delay Compensation (RDC), a MARL training framework for addressing stochastic individual delays, along with recommended implementations for its constituent modules. We implement the DSID-POMDP's observation generation pattern using standard MARL benchmarks, including MPE and SMAC. Experiments demonstrate that baseline MARL methods suffer severe performance degradation under fixed and unfixed delays. The RDC-enhanced approach mitigates this issue, remarkably achieving ideal delay-free performance in certain delay scenarios while maintaining generalization capability. Our work provides a novel perspective on multi-agent delayed observation problems and offers an effective solution framework.
QTypeMix: Enhancing Multi-Agent Cooperative Strategies through Heterogeneous and Homogeneous Value Decomposition
Aug 12, 2024In multi-agent cooperative tasks, the presence of heterogeneous agents is familiar. Compared to cooperation among homogeneous agents, collaboration requires considering the best-suited sub-tasks for each agent. However, the operation of multi-agent systems often involves a large amount of complex interaction information, making it more challenging to learn heterogeneous strategies. Related multi-agent reinforcement learning methods sometimes use grouping mechanisms to form smaller cooperative groups or leverage prior domain knowledge to learn strategies for different roles. In contrast, agents should learn deeper role features without relying on additional information. Therefore, we propose QTypeMix, which divides the value decomposition process into homogeneous and heterogeneous stages. QTypeMix learns to extract type features from local historical observations through the TE loss. In addition, we introduce advanced network structures containing attention mechanisms and hypernets to enhance the representation capability and achieve the value decomposition process. The results of testing the proposed method on 14 maps from SMAC and SMACv2 show that QTypeMix achieves state-of-the-art performance in tasks of varying difficulty.